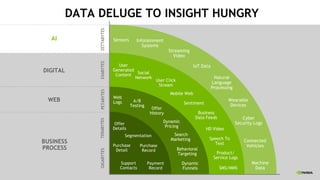
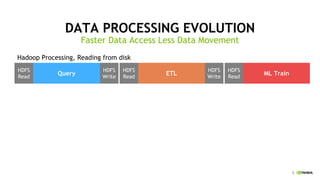
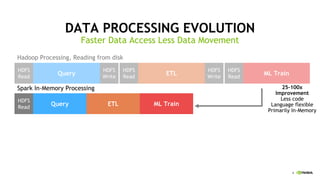
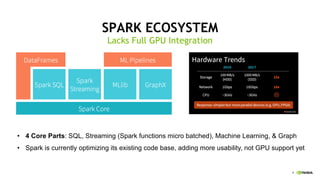
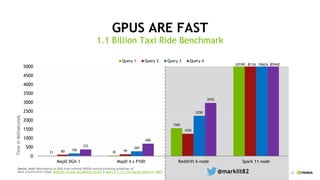
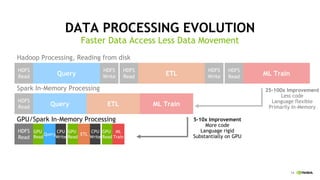
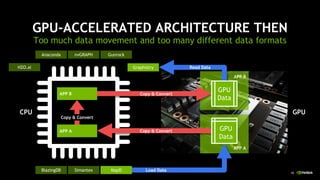
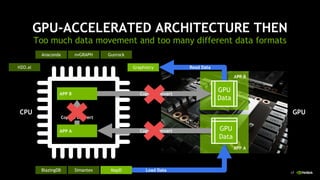
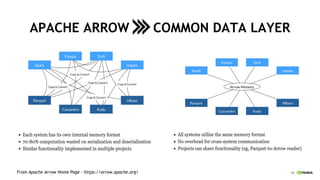
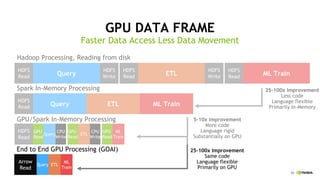
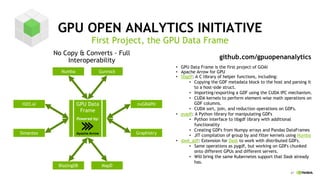
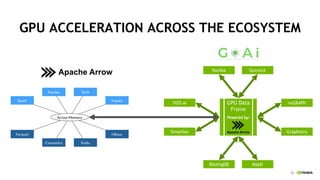
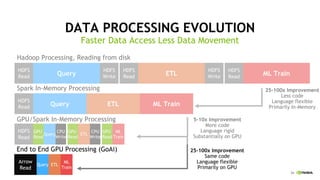
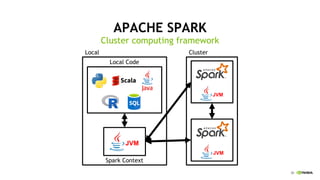
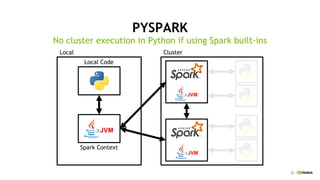
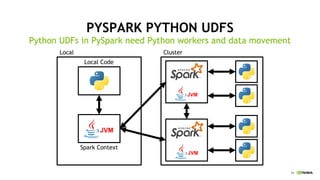
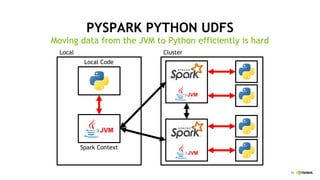
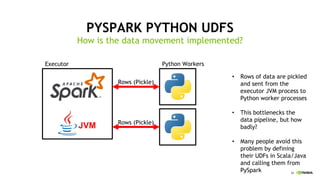
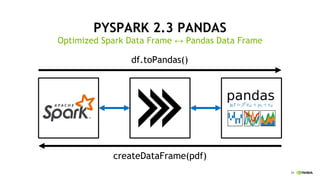
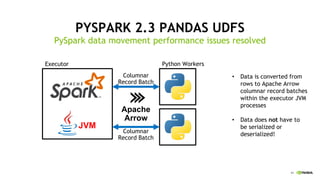
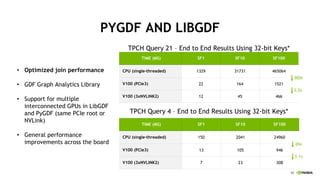
This document discusses accelerating Python user-defined functions (UDFs) in PySpark using Numba and PyGDF. It describes how data movement between the JVM and Python workers is currently a bottleneck for PySpark Python UDFs. With Apache Arrow, data can be transferred in a columnar format without serialization, improving performance. PyGDF enables defining UDFs that operate directly on GPU data frames using Numba for further acceleration. This allows leveraging GPUs to optimize complex UDFs in PySpark. Future work includes optimizing joins in PyGDF and supporting distributed GPU processing.































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







