Download as PDF, PPTX






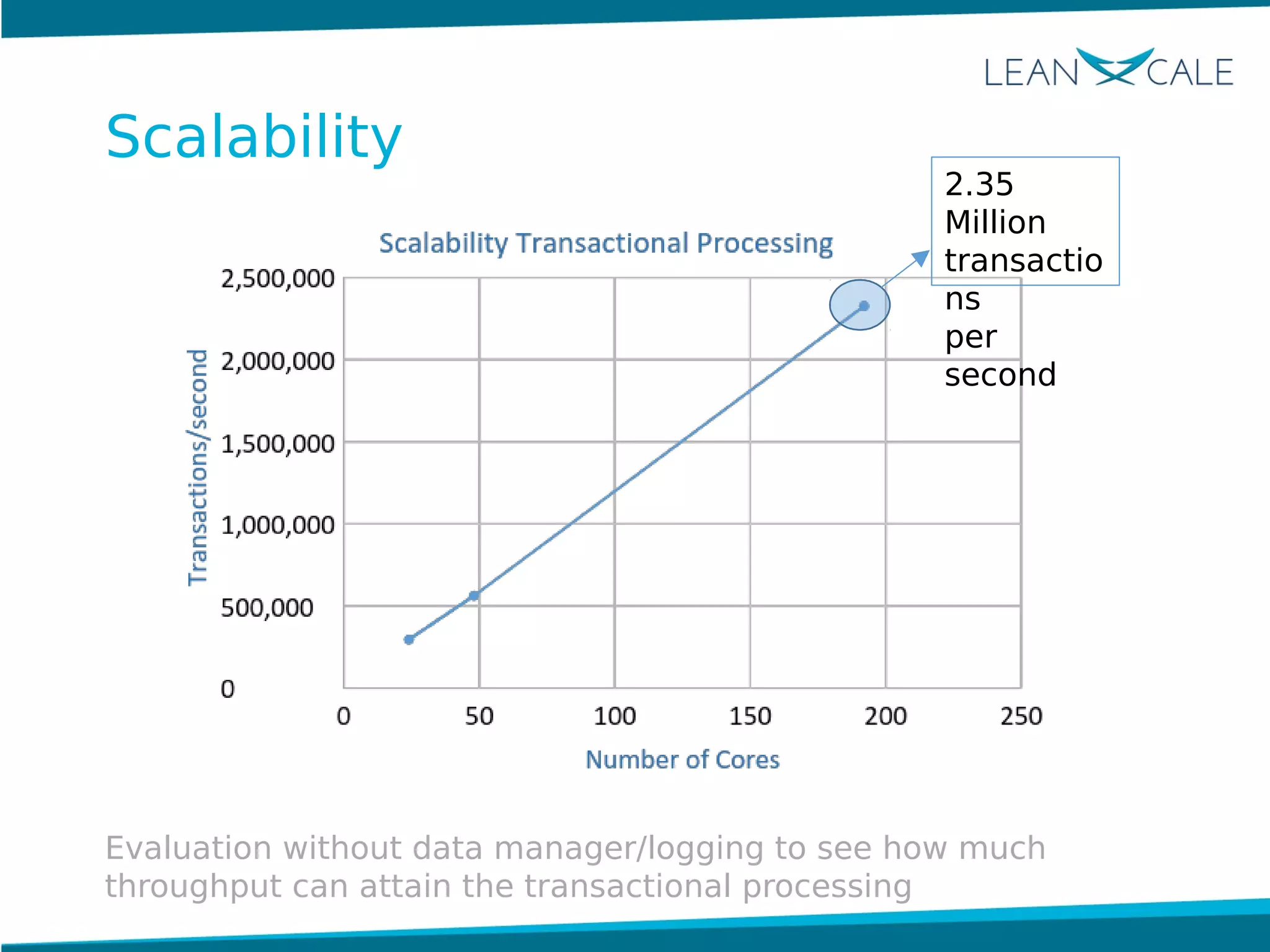
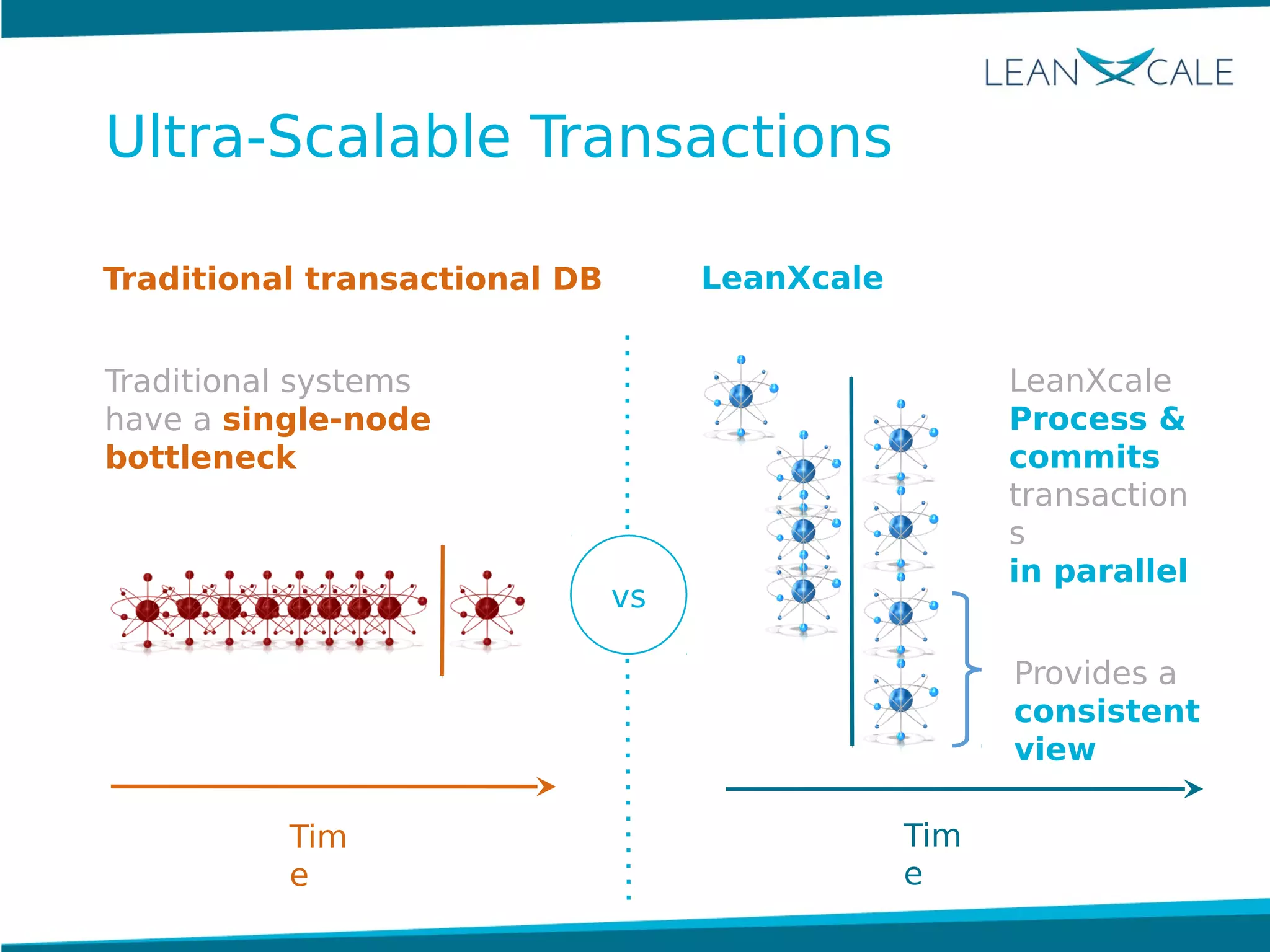


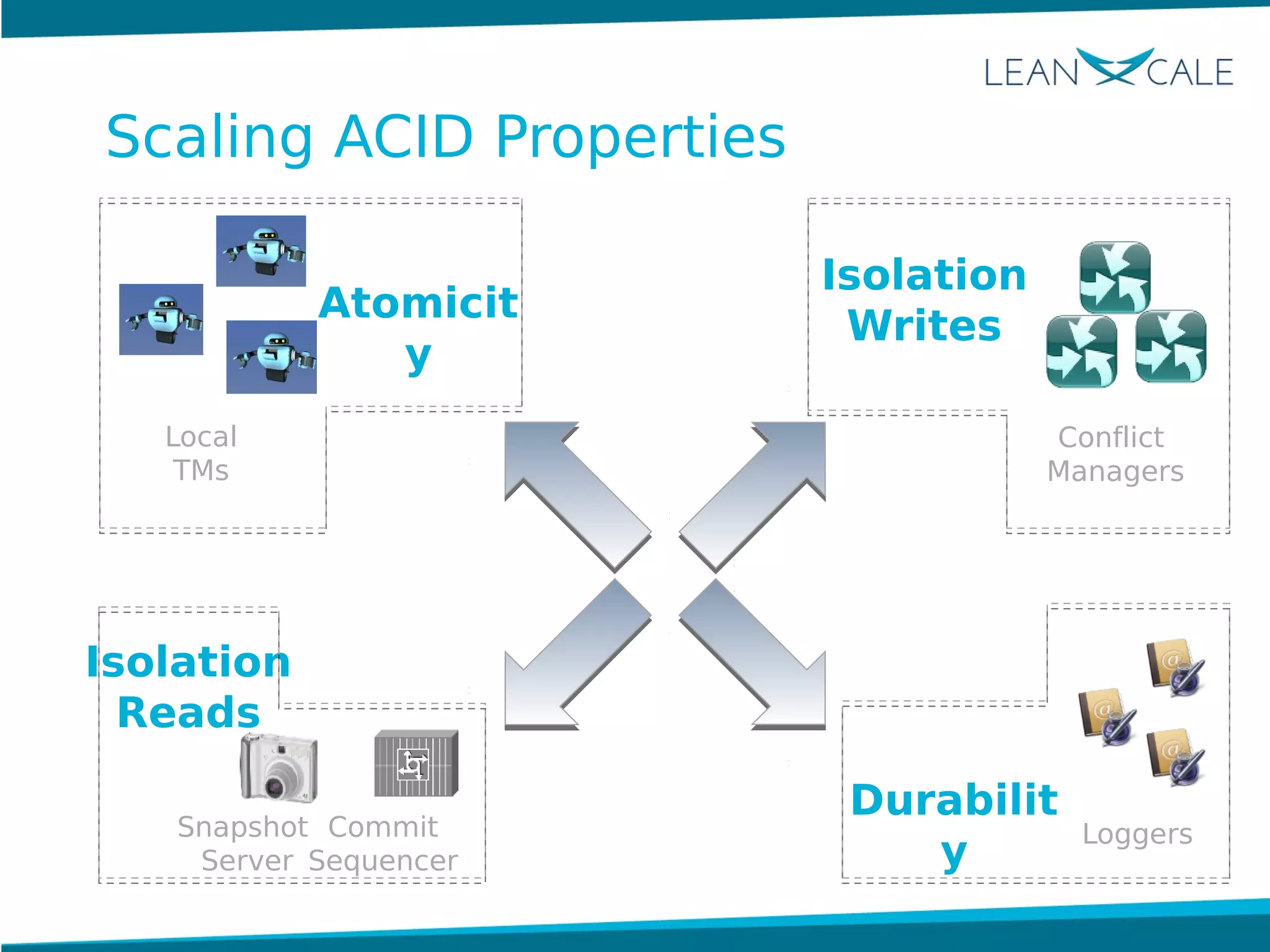

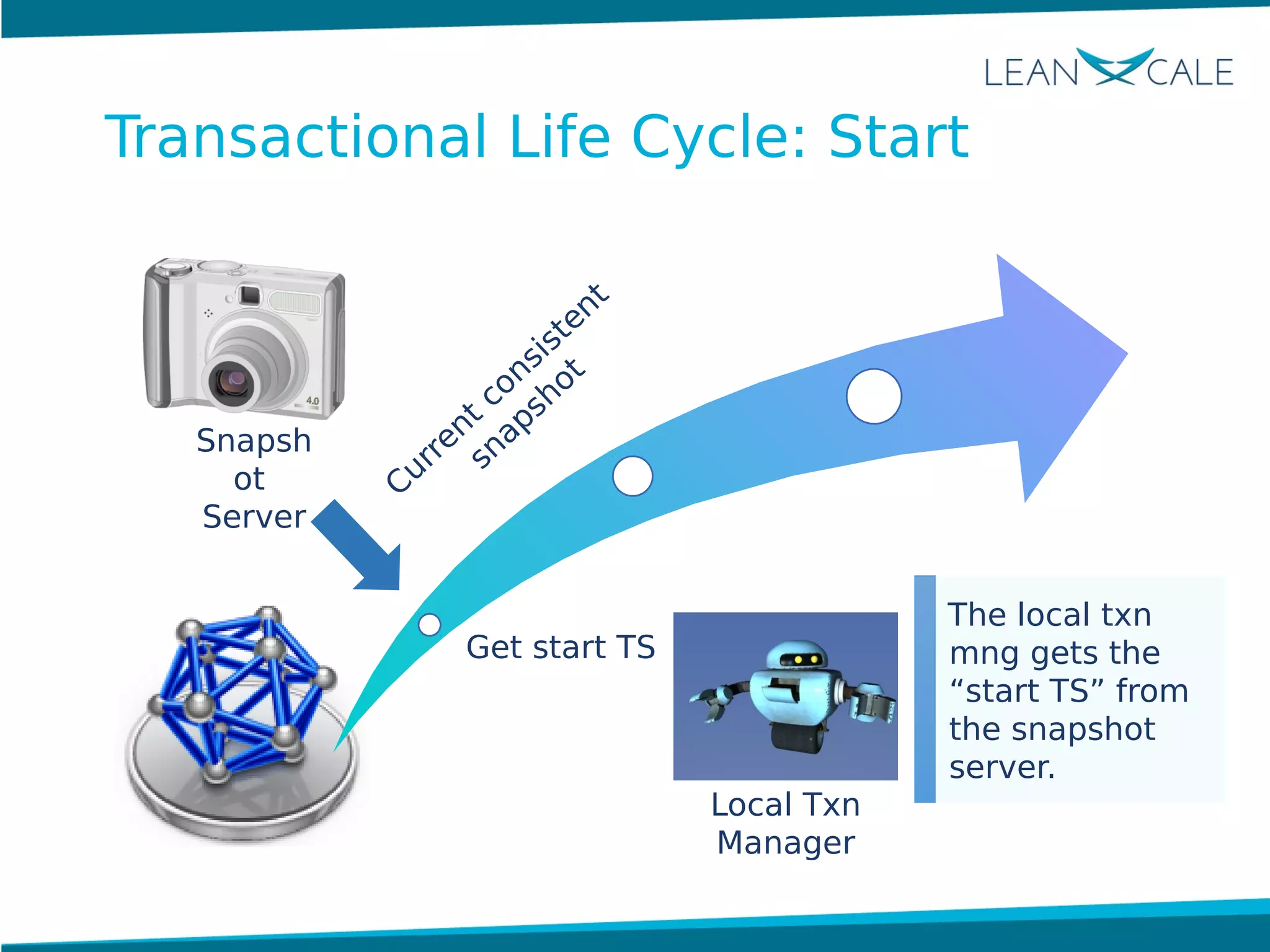
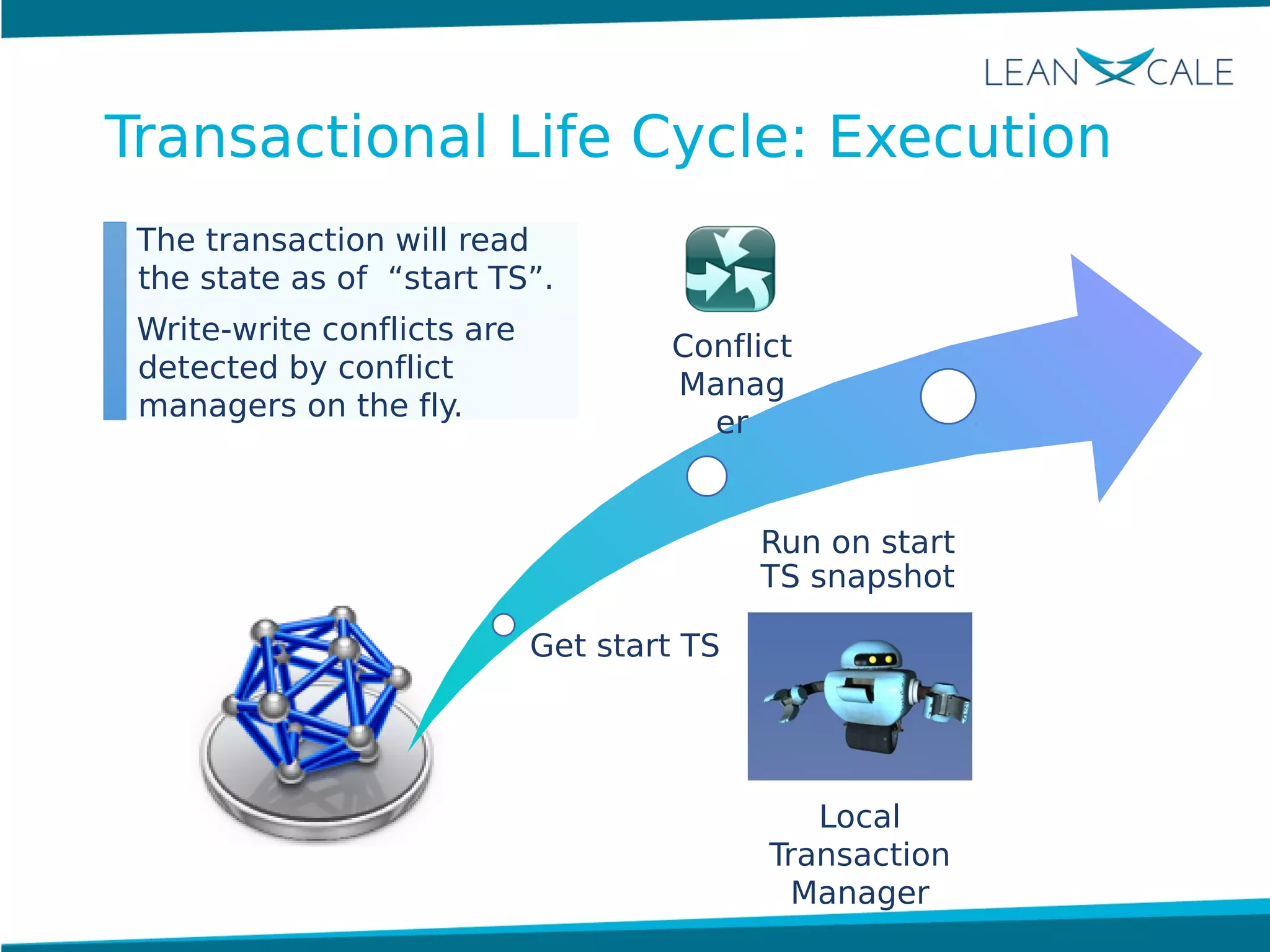

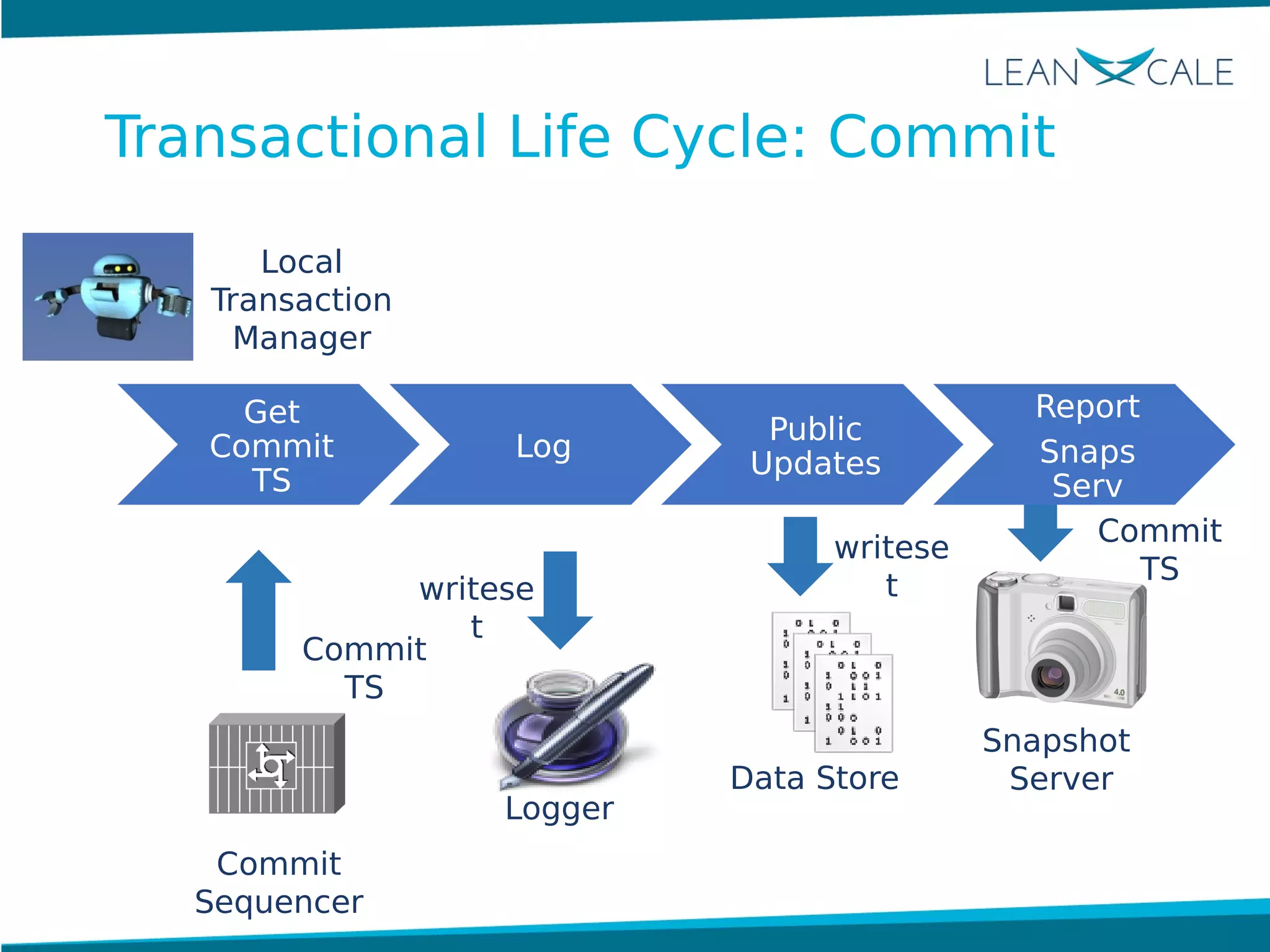
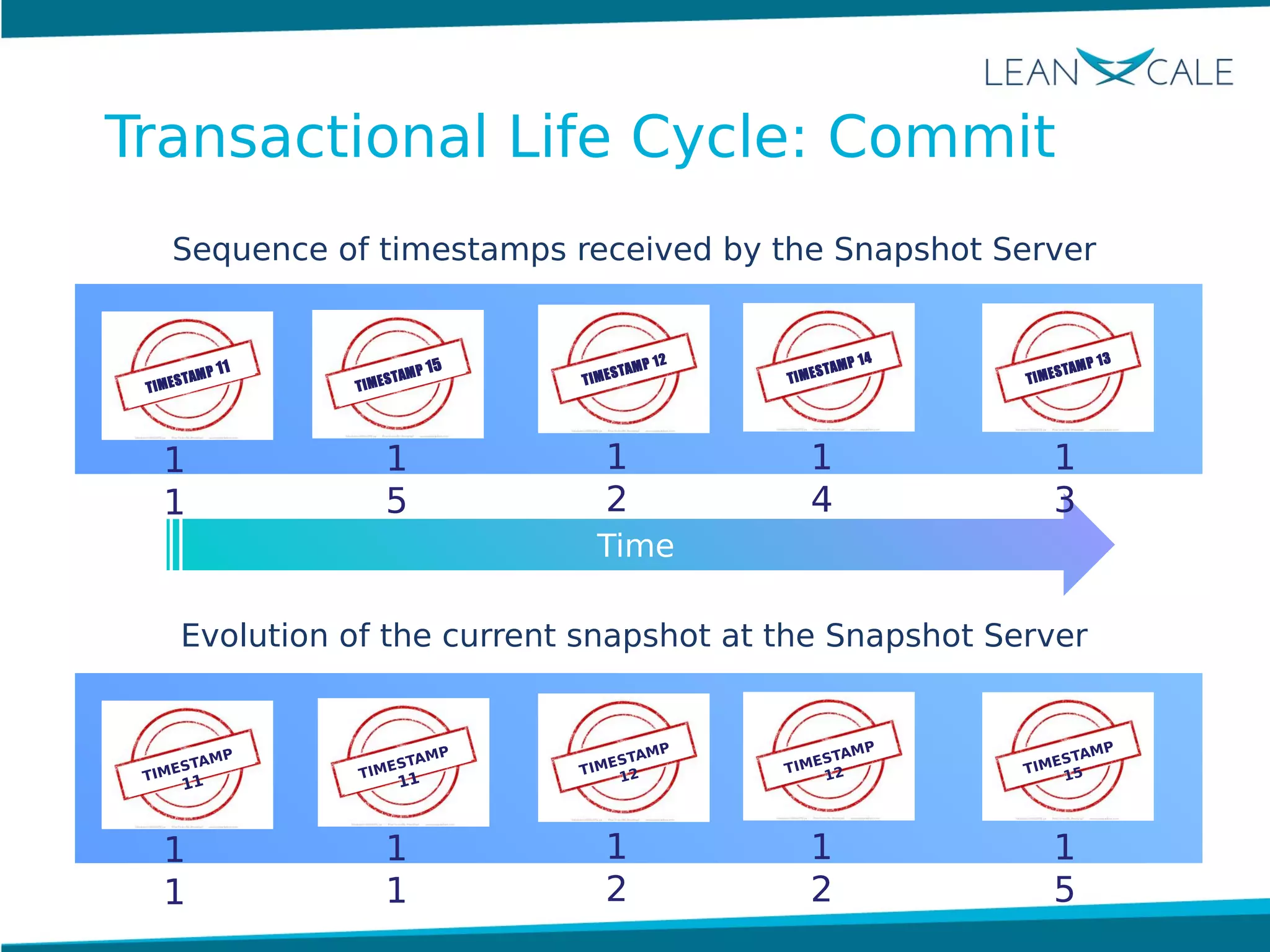


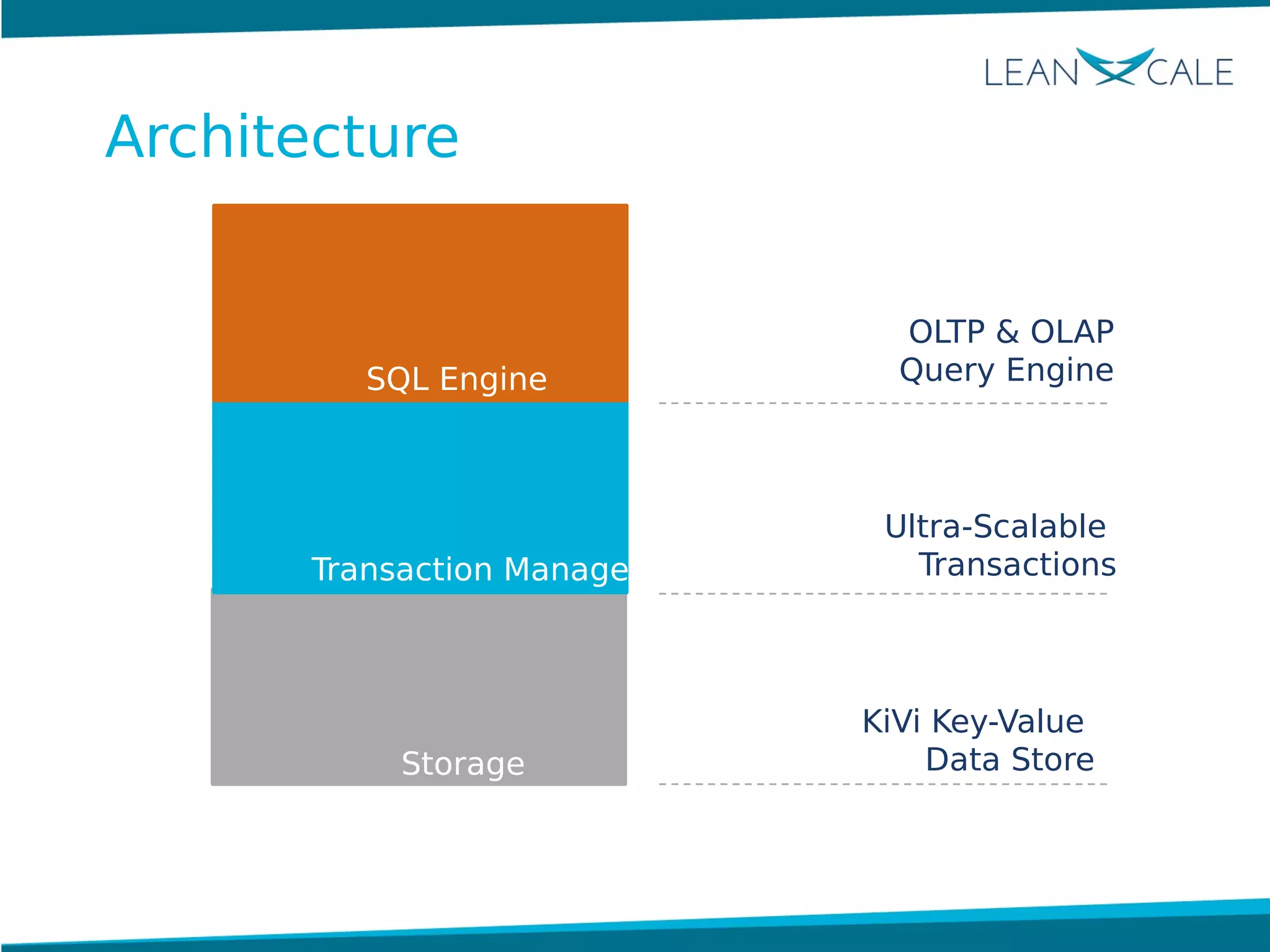








Ricardo Jimenez-Peris, CEO of LeanXcale, discusses the breakthrough in scalable transactional management that allows for 100 million update transactions per second, debunking the myth that operational databases cannot scale. LeanXcale offers an ultra-scalable database that combines both operational and analytical capabilities without sharding, maintaining full ACID properties. The technology can replace mainframe systems by providing real-time analytics while reducing costs and operational complexities.























































































