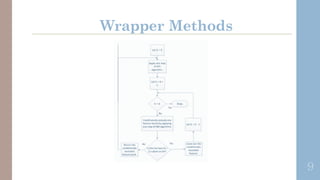
The document outlines various feature selection methods, focusing on filter, wrapper, and embedded techniques designed to enhance predictive performance while reducing irrelevant variables. It details computational strategies like sequential selection and genetic algorithms, as well as the integration of feature selection into model training processes. The conclusion emphasizes that effective feature selection improves model insights, generalization, and identifies irrelevant variables.





































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)






