Downloaded 36 times



![2 . 2
Motivation
MegaPipe [OSDI '12]
outperforms baseline Linux .. 582% (for short connections).
New API for applications (no existing applications benefit)
mTCP [NSDI '14]
improve... by a factor of 25 compared to the latest Linux TCP
implement with very limited TCP extensions
SandStorm [SIGCOMM '14]
our approach ..., demonstrating 2-10x improvements
specialized (no existing applications benefit)
Arrakis [OSDI '14]
improvements of 2-5x in latency and 9x in throughput .. to Linux
utilize simplified TCP/IP stack (lwip) (loose feature-rich extensions)
IX [OSDI '14]
improves throughput ... by 3.6x and reduces latency by 2x
utilize simplified TCP/IP stack (lwip) (loose feature-rich extensions)](https://image.slidesharecdn.com/netdev21-tazaki-170408031202/85/Playing-BBR-with-a-userspace-network-stack-3-320.jpg)


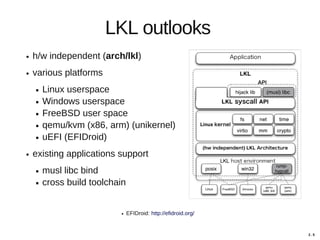




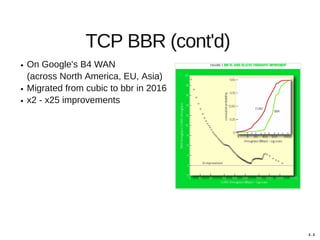











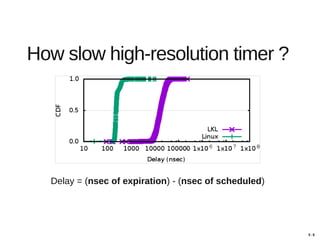


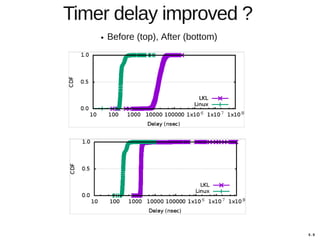
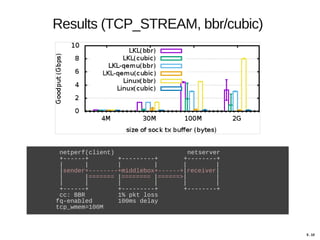


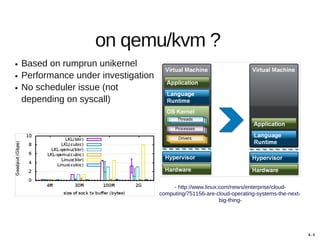









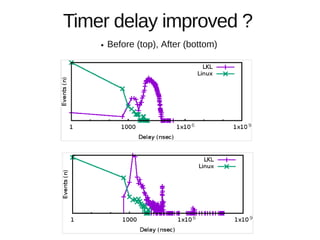
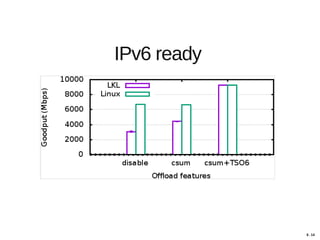

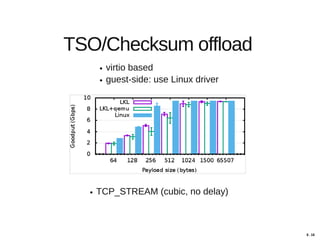

Hajime Tazaki presented on using the Linux Kernel Library (LKL) to run a userspace network stack with TCP BBR. Initial benchmarks showed poor BBR performance with LKL due to imprecise timestamps. Improving the timestamp resolution and scheduler optimizations increased BBR throughput to be comparable to native Linux. Further work is needed to fully understand performance impacts and optimize for high-speed networks. LKL provides a reusable network stack across platforms but faces challenges with timing accuracy required for features like BBR.














![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)




















































