






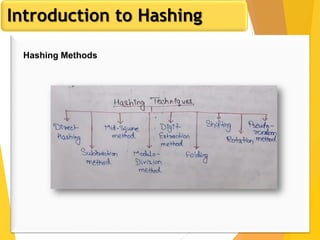



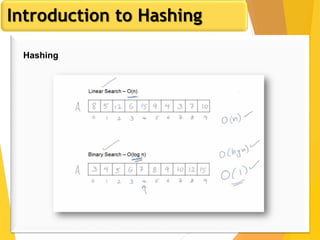
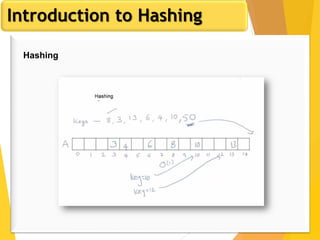
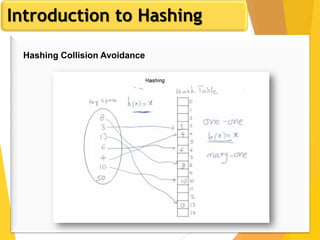
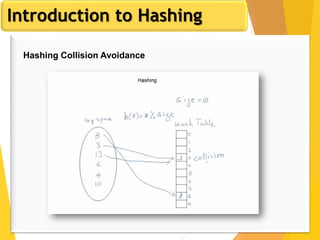

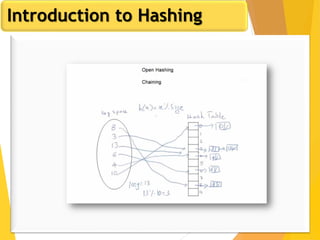
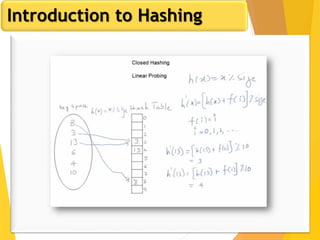
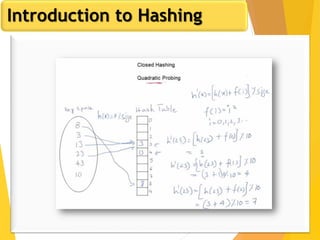





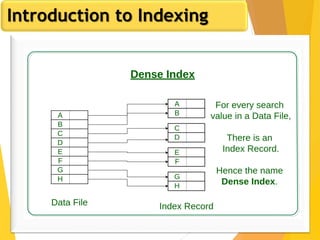
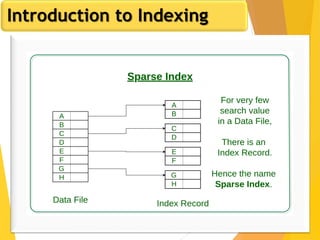

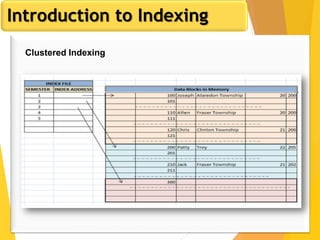
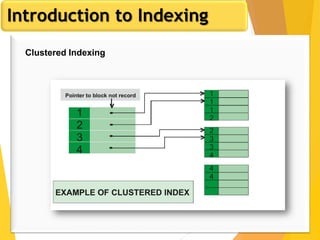
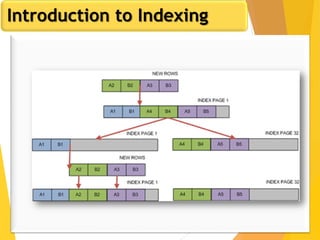

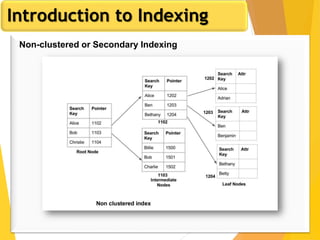
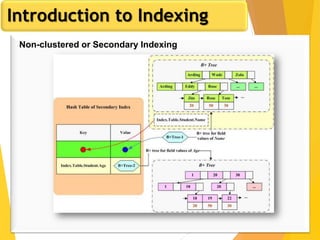
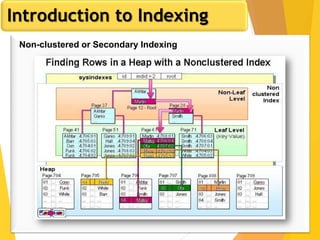

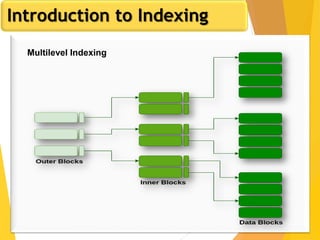
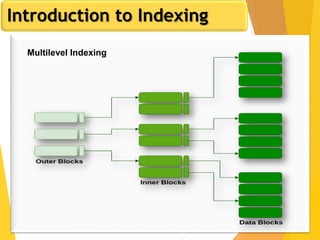


The document discusses database design, focusing on hashing and indexing techniques. It explains hashing as a method to directly locate data on disks and outlines various types of hashing, including static and dynamic hashing, as well as collision resolution techniques. Additionally, it covers indexing strategies like primary and secondary indexes, accessing methods, and clustering versus non-clustering indexing to optimize database performance.























































































