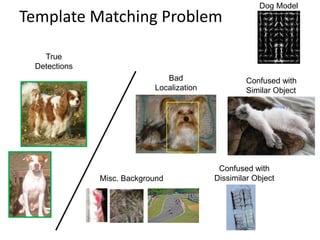
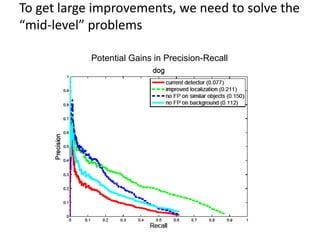
1) Recent advances in object recognition focused on detection but further improvements require better segmentation and mid-level representations to better localize objects.
2) The next challenges are in object interpretation, requiring new representations that can handle unfamiliar objects, physical context, and task-specific relevance.
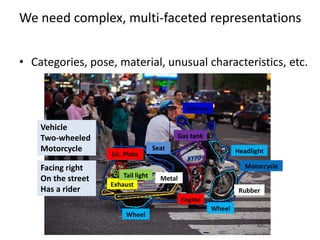
3) Building complex, multi-faceted representations of objects that describe categories, pose, materials, characteristics, and relationships will be needed to make progress on object interpretation.





























![Power%20 point[1]](https://cdn.slidesharecdn.com/ss_thumbnails/power20point1-100625081647-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























































