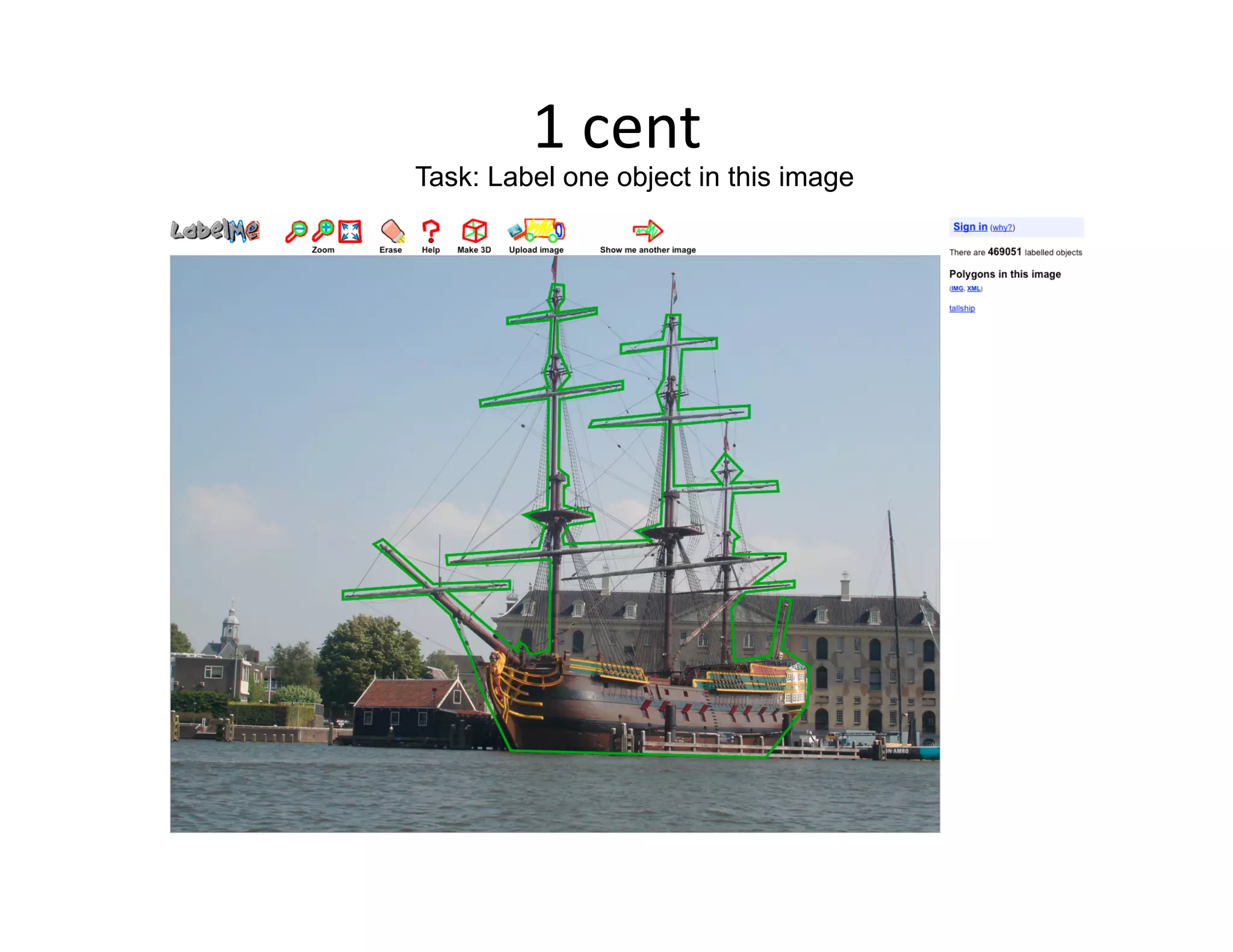
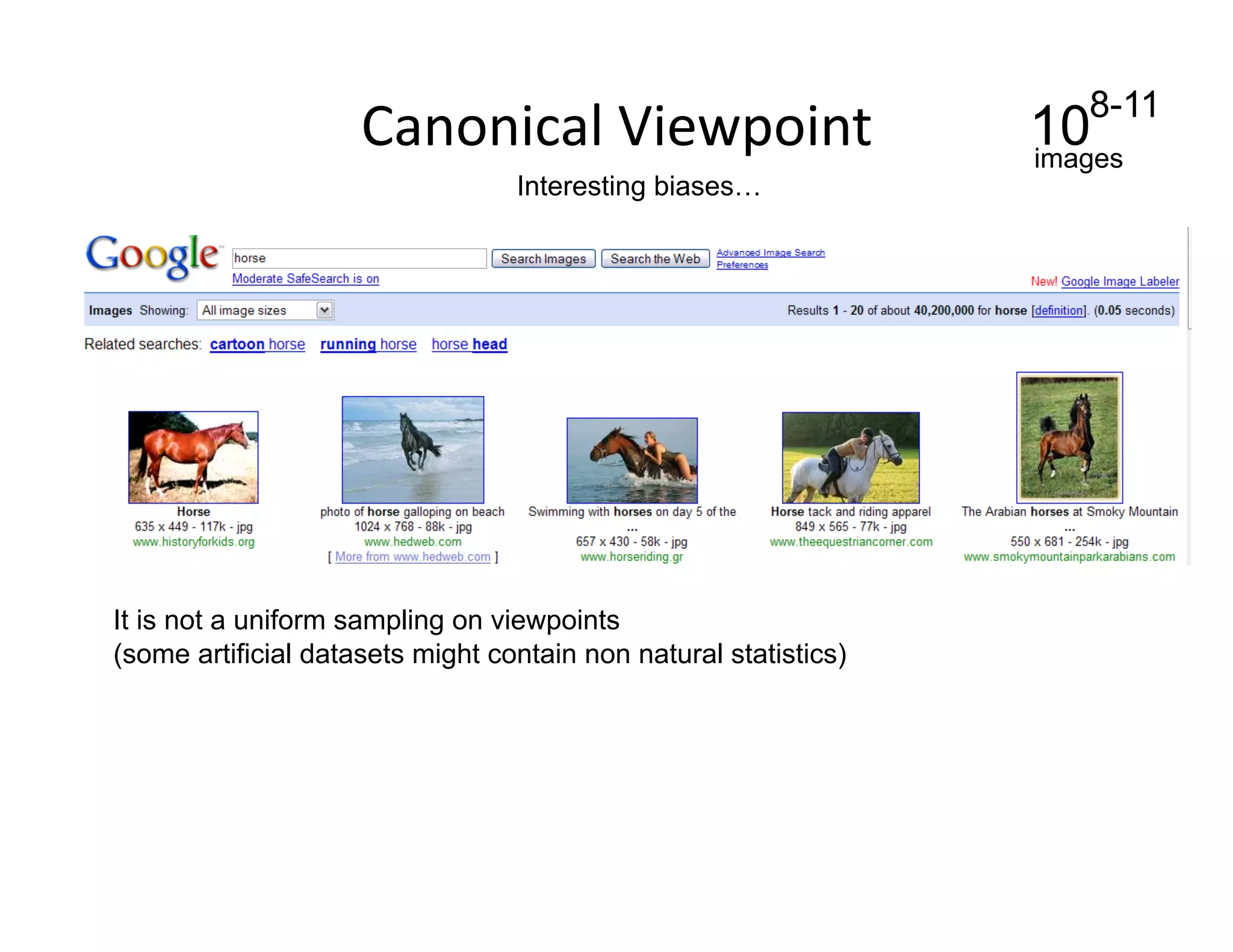
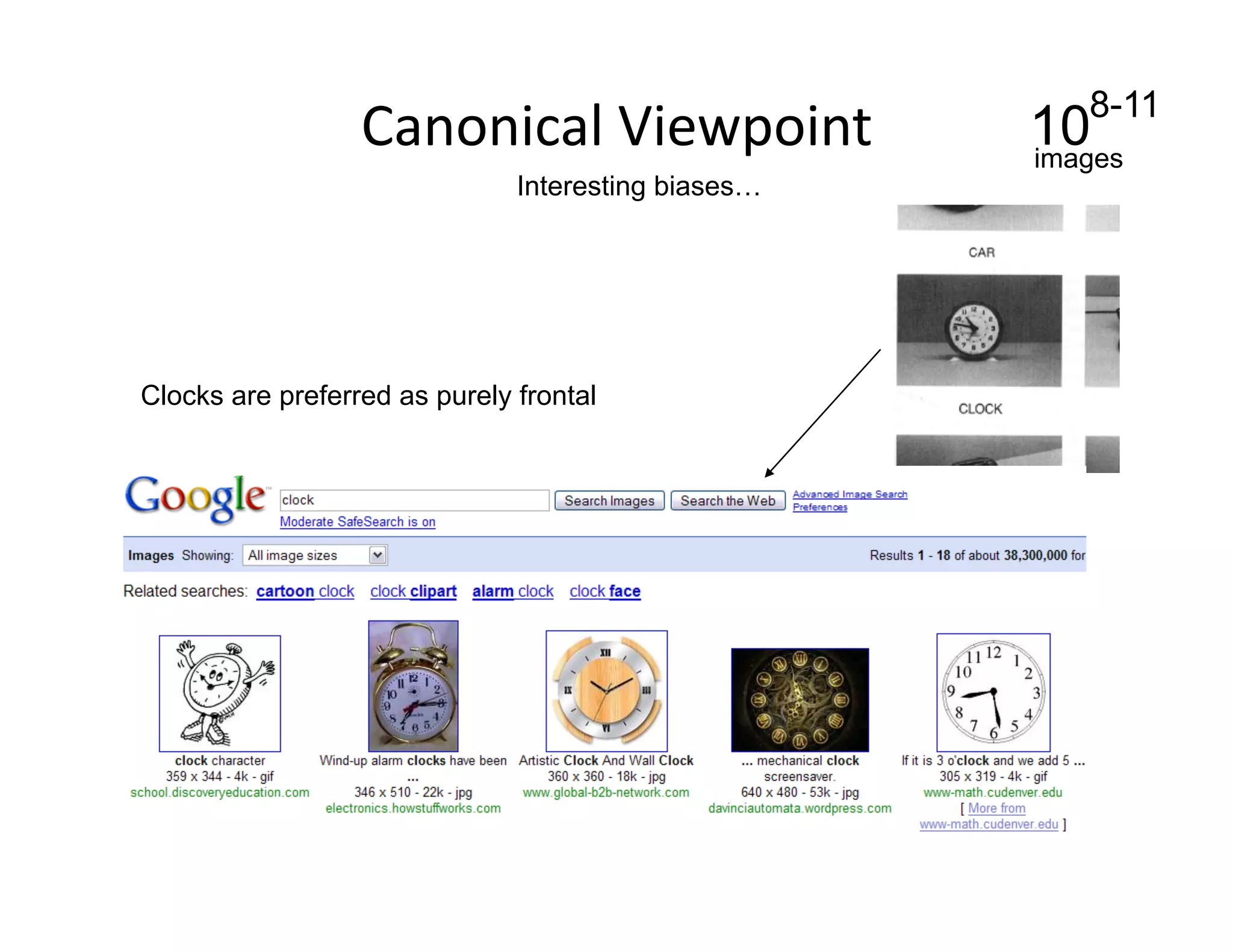
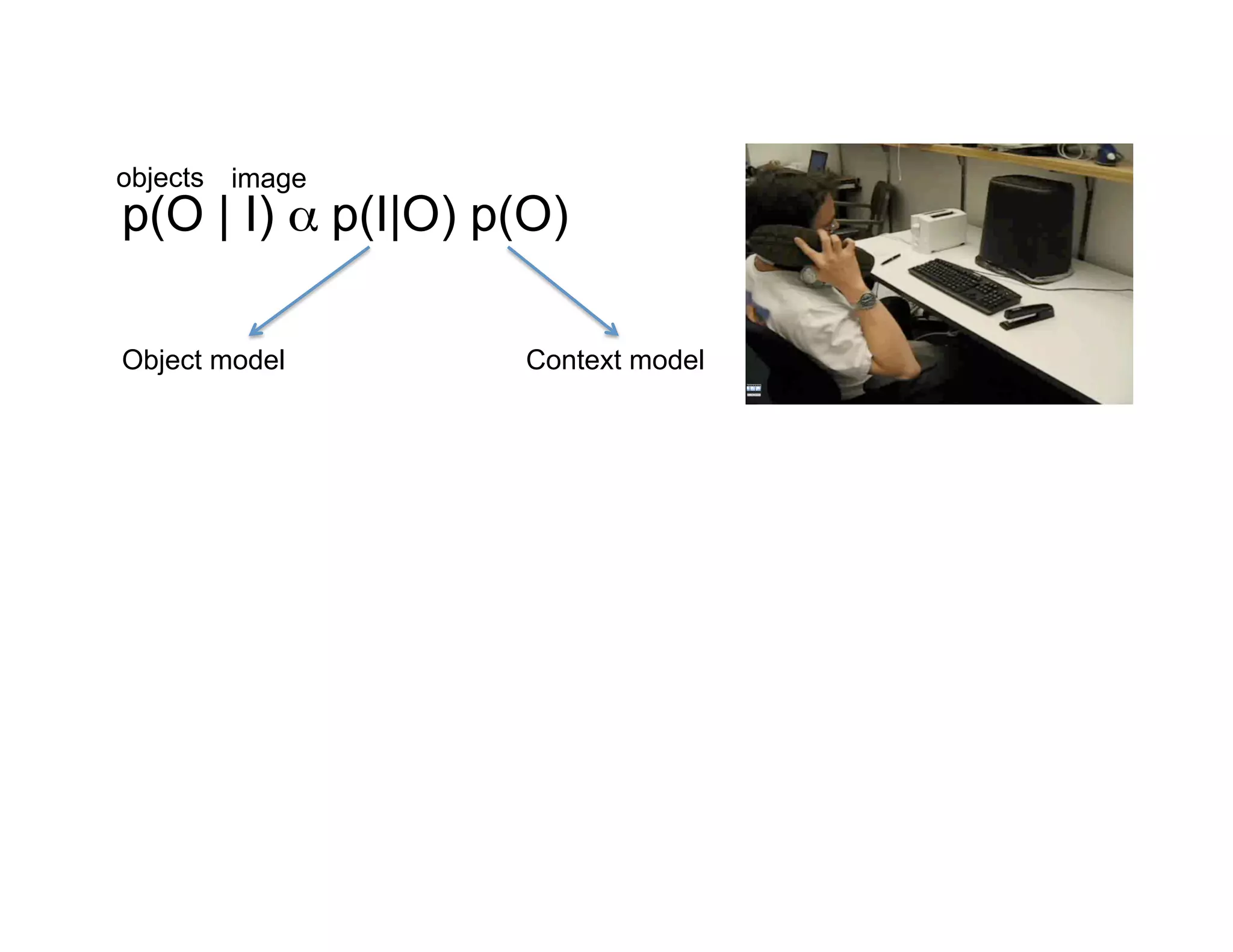
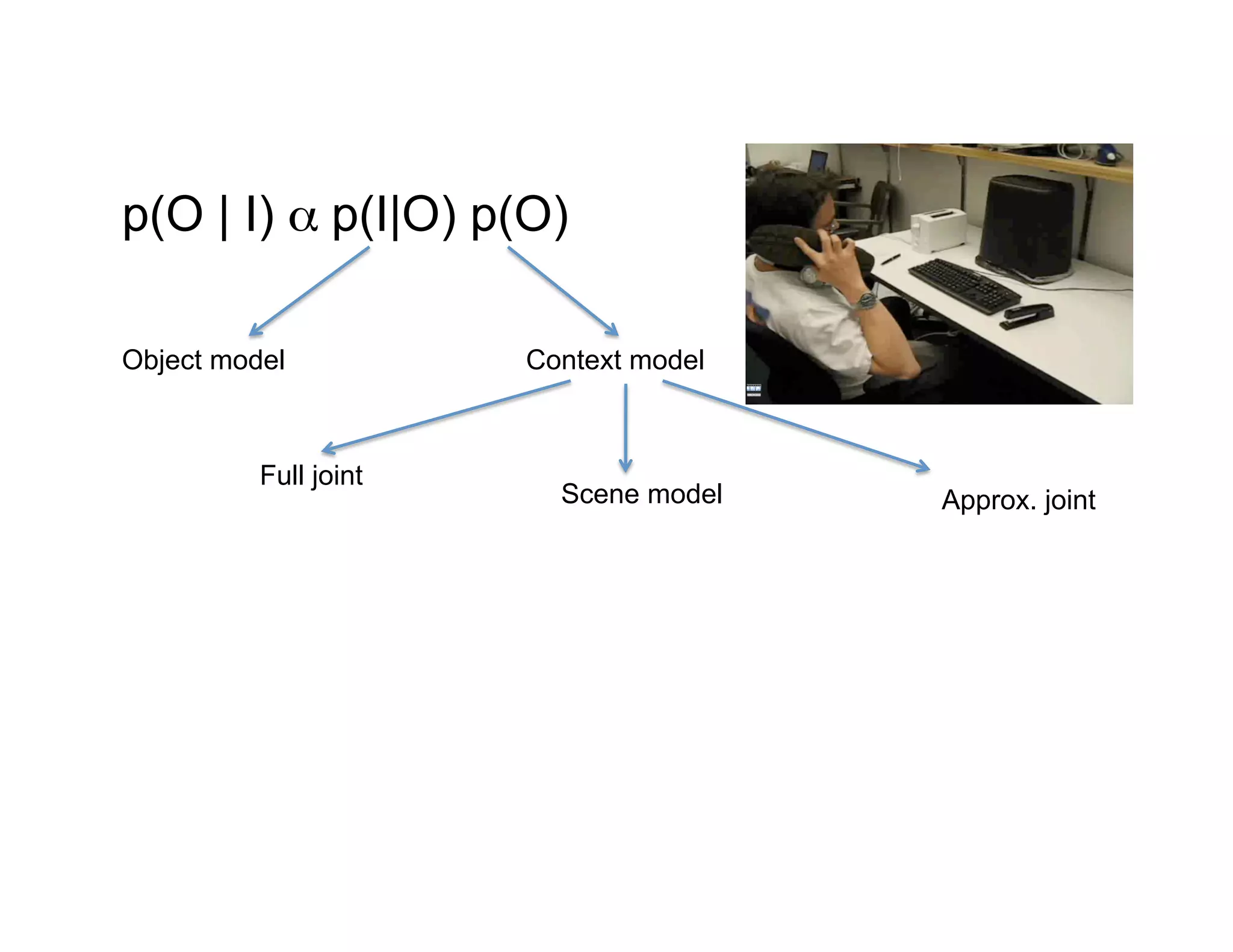
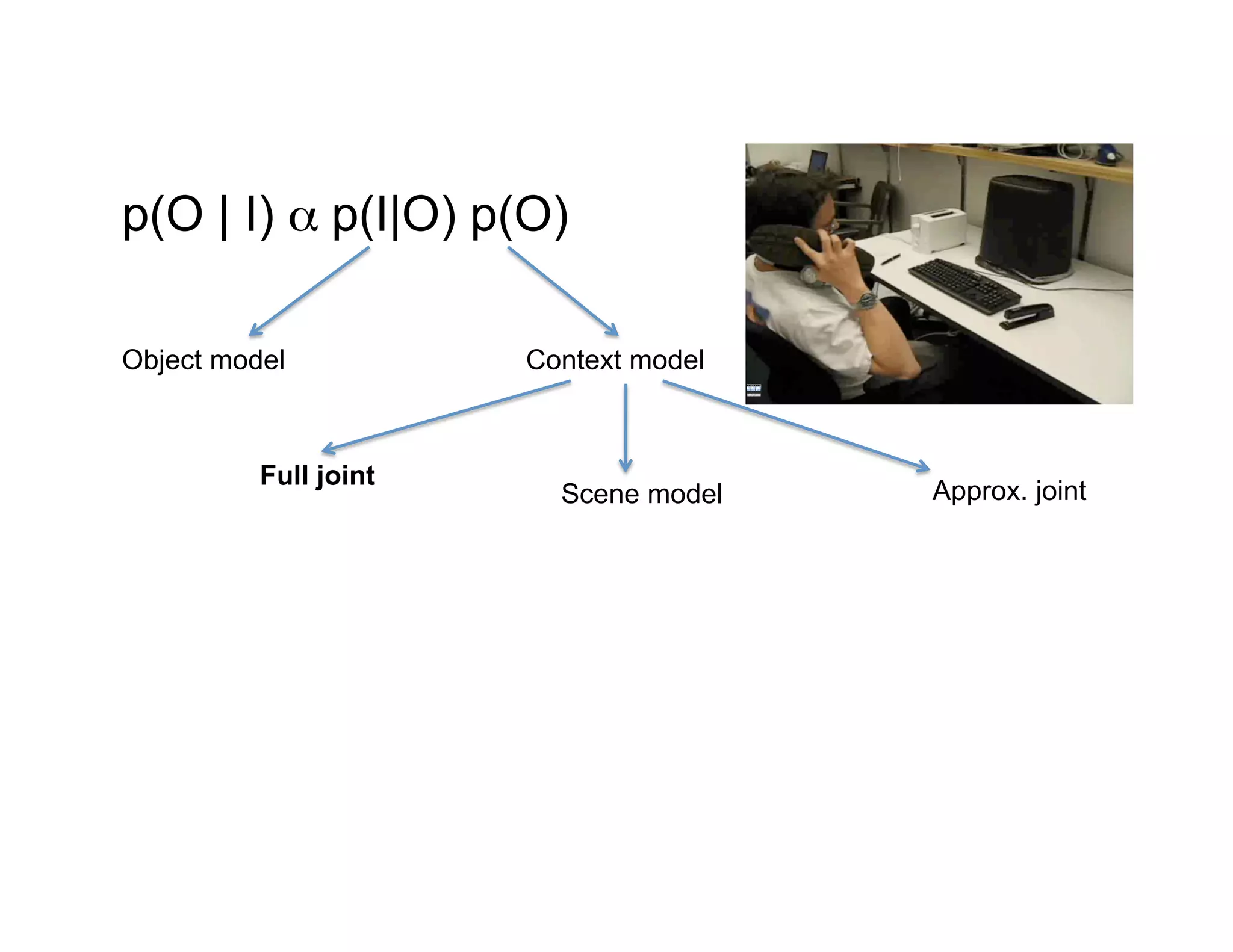
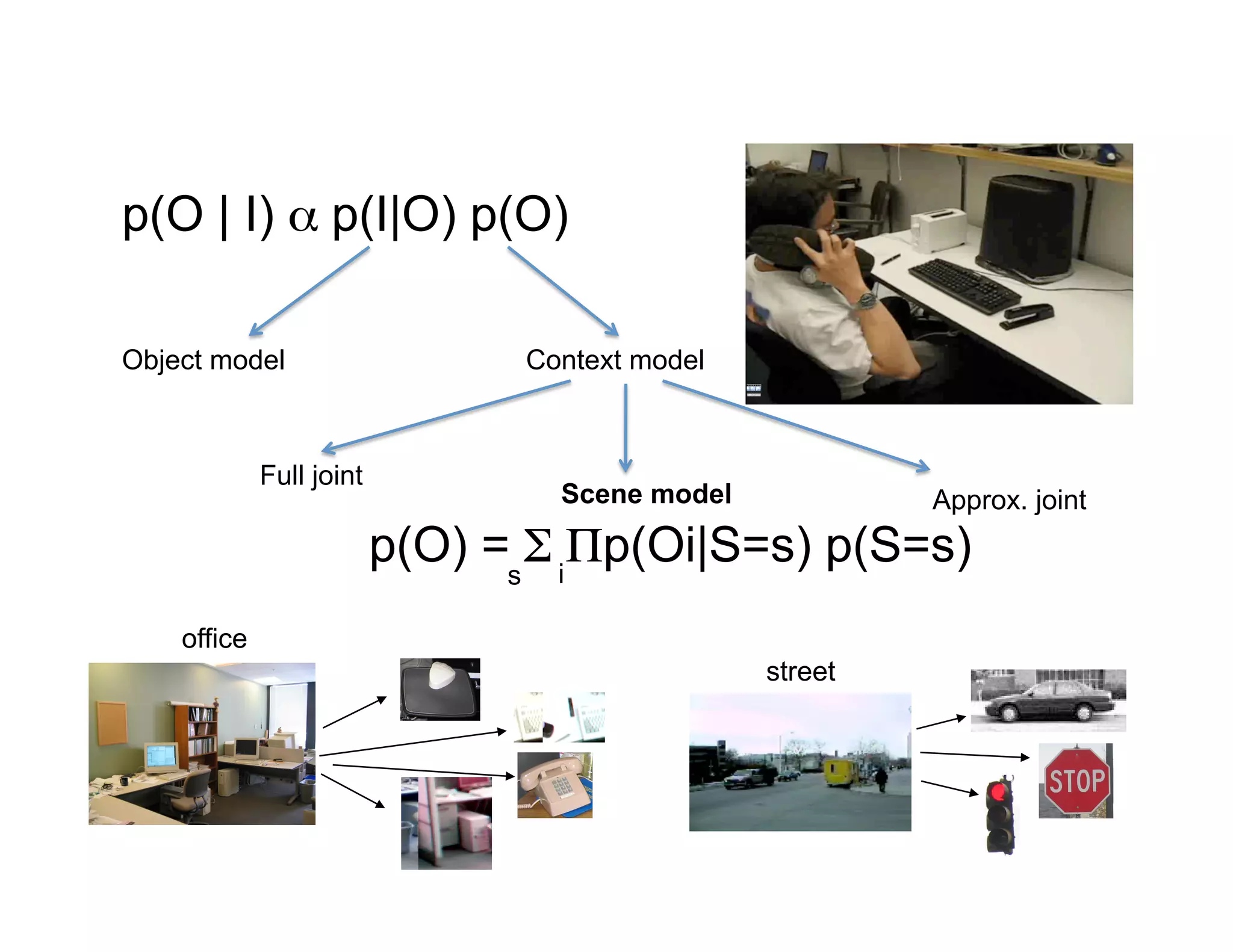
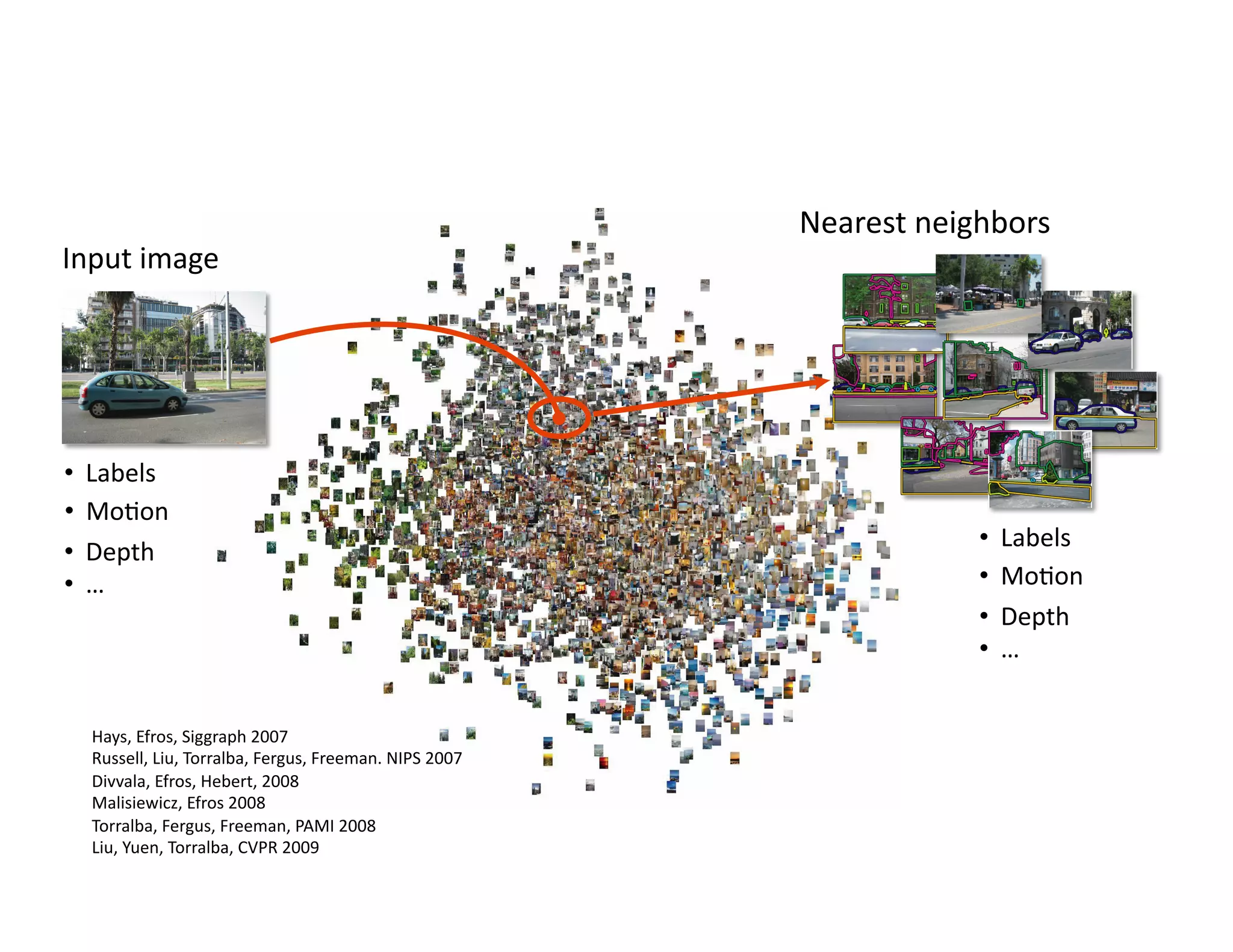
This document discusses using large image datasets and context to understand scenes and objects. It proposes using millions of internet images to generate proposals for image completion and labeling based on nearest visual neighbors. Location metadata from geotagged images can provide context without object labels. Event prediction and video synthesis is demonstrated by retrieving relevant images from large collections to construct new videos based on a text query. Overall it argues that large internet-scale image collections provide rich context that can be leveraged for computer vision tasks through data-driven approaches rather than explicit modeling.





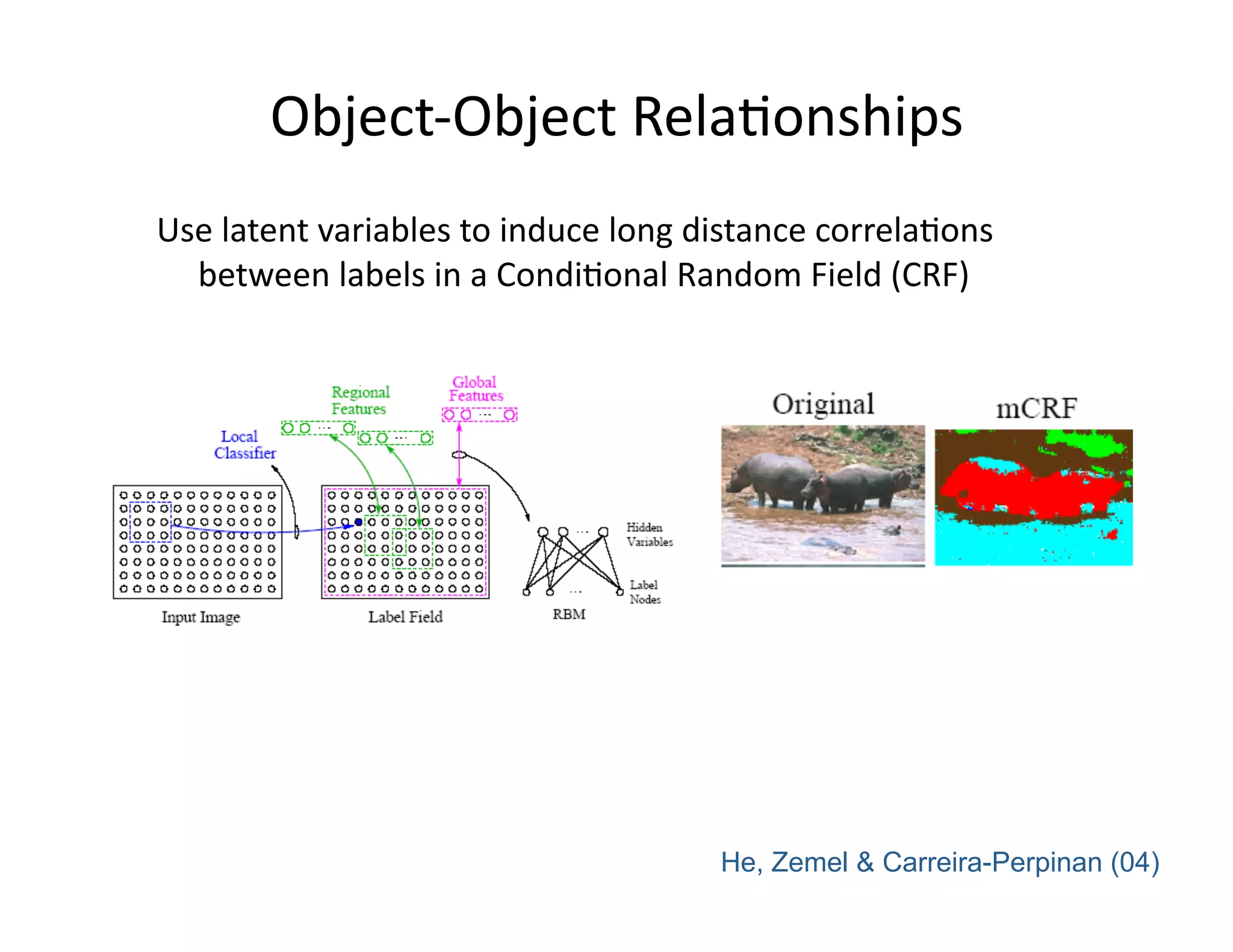
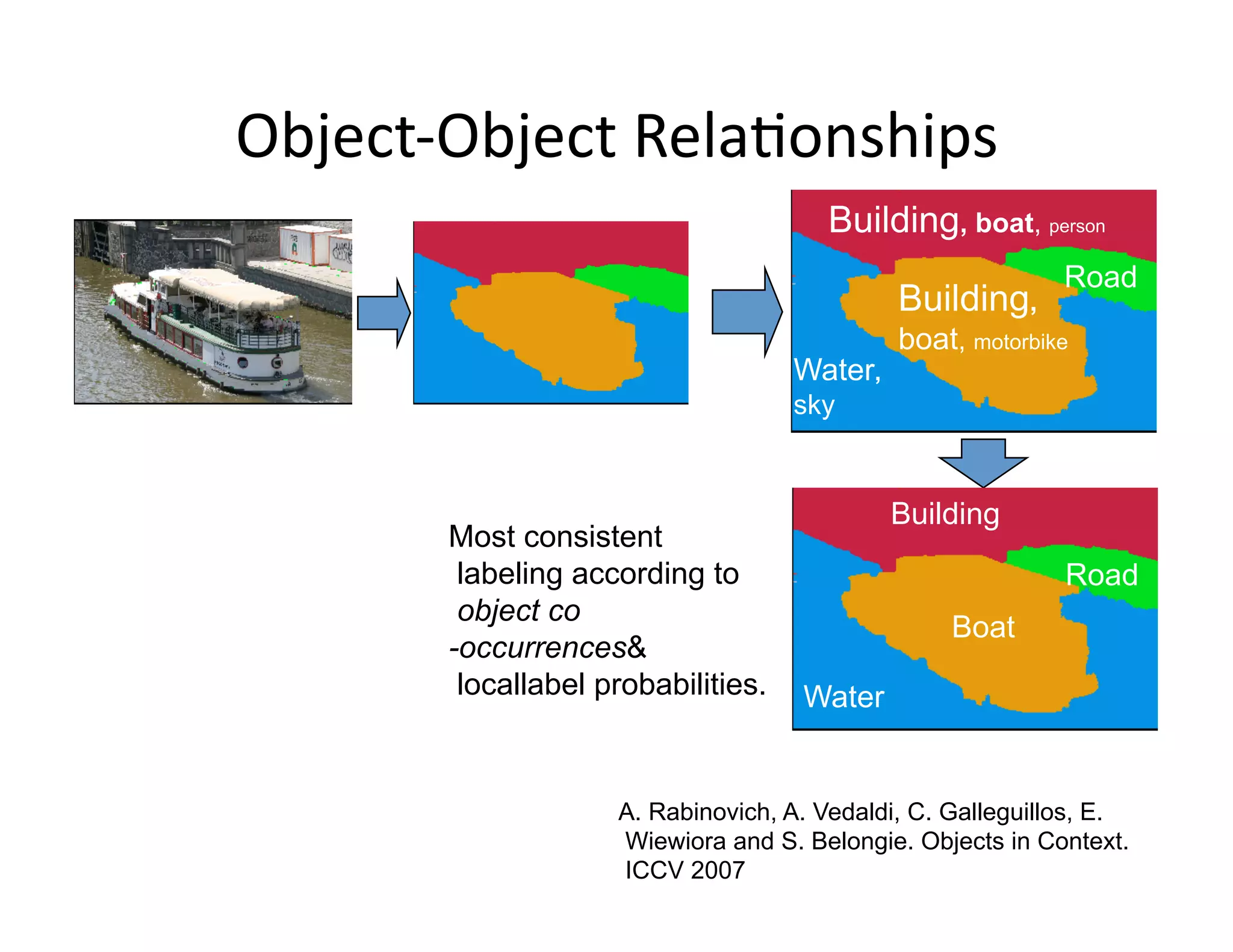
![Object‐Object RelaPonships
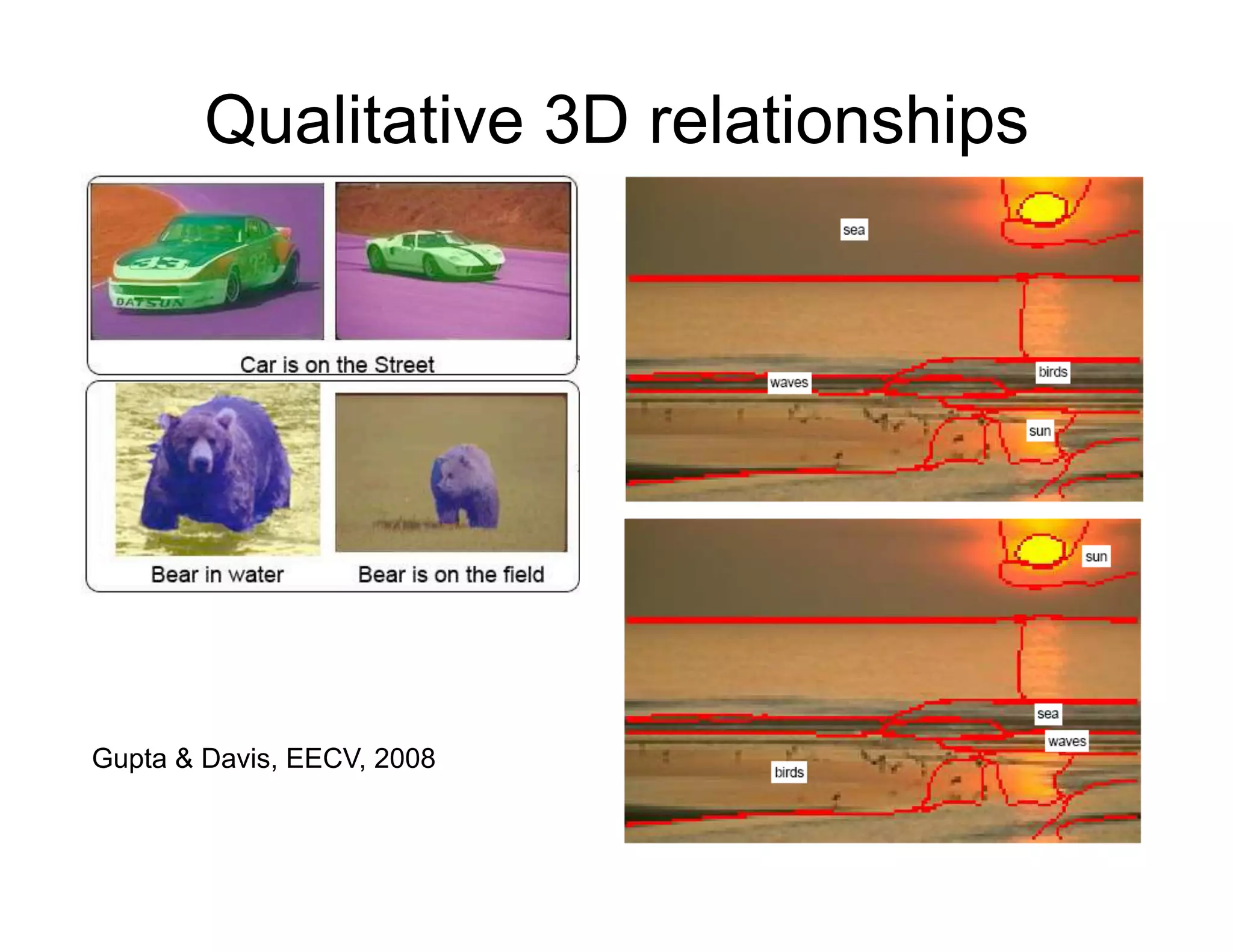
[Kumar Hebert 2005]](https://image.slidesharecdn.com/nips09torralbauvs02-110515110823-phpapp01/75/NIPS2009-Understand-Visual-Scenes-Part-2-12-2048.jpg)




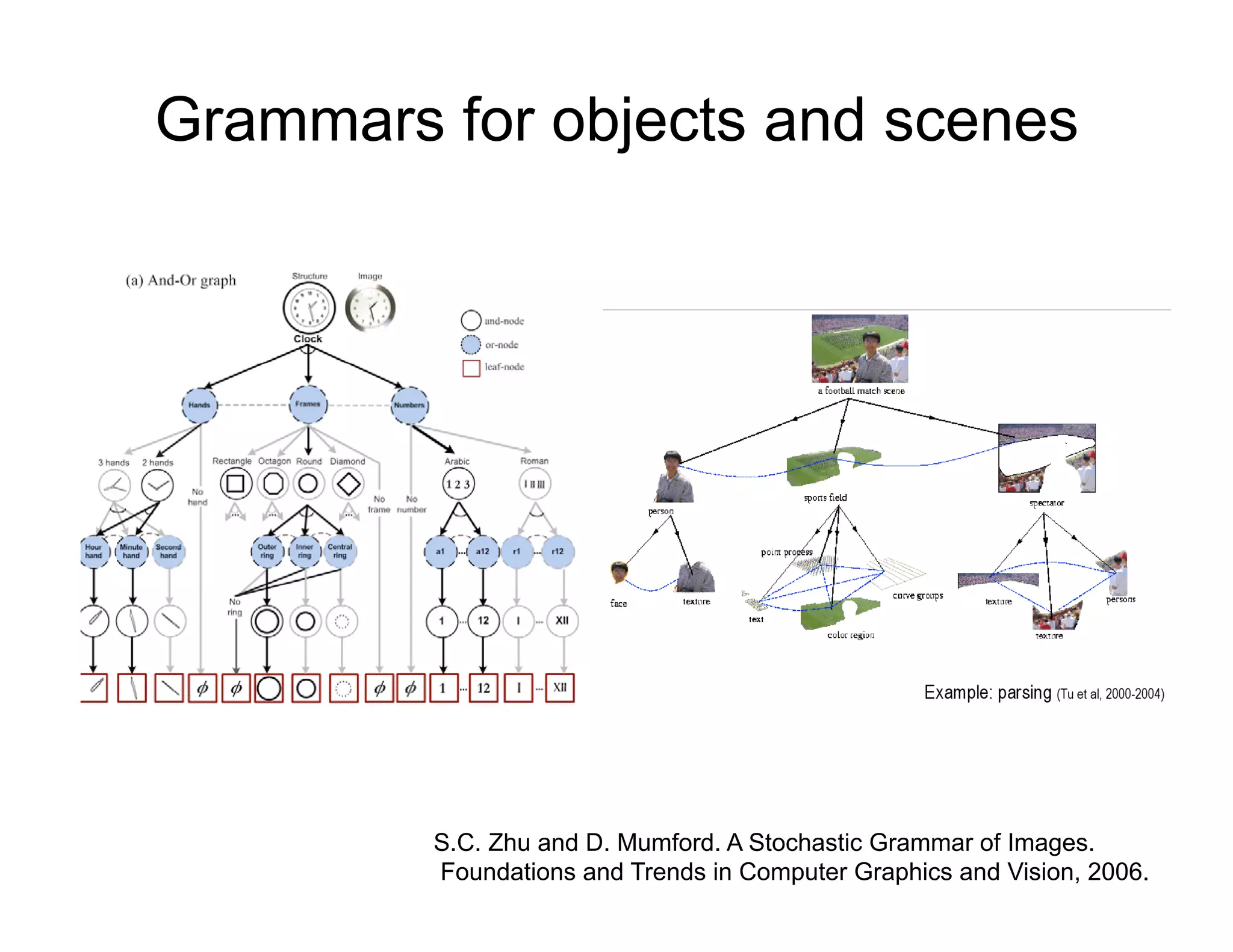
![Grammars
Guzman (SEE), 1968
Noton and Stark 1971
Hansen & Riseman (VISIONS), 1978
Barrow & Tenenbaum 1978
Brooks (ACRONYM), 1979
[Ohta & Kanade 1978] Marr, 1982
Yakimovsky & Feldman, 1973](https://image.slidesharecdn.com/nips09torralbauvs02-110515110823-phpapp01/75/NIPS2009-Understand-Visual-Scenes-Part-2-19-2048.jpg)






![Qualitative Results
Car: TP / FP Ped: TP / FP
Initial: 2 TP / 3 FP Final: 7 TP / 4 FP
Slide by Derek Hoiem Local Detector from [Murphy-Torralba-Freeman 2003]](https://image.slidesharecdn.com/nips09torralbauvs02-110515110823-phpapp01/75/NIPS2009-Understand-Visual-Scenes-Part-2-31-2048.jpg)


![Surface Estimation
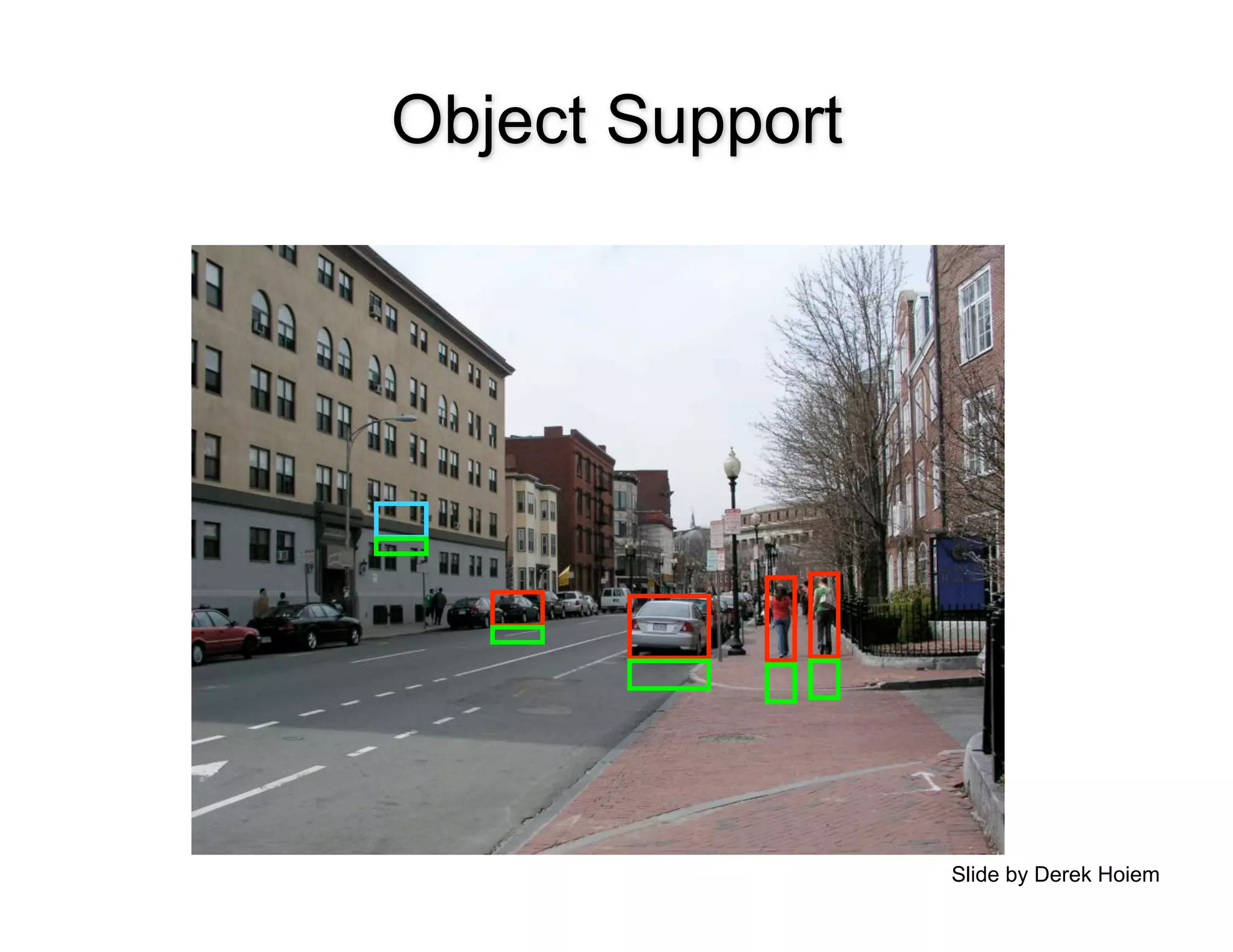
Image Support Vertical Sky
V-Left V-Center V-Right V-Porous V-Solid
Object
Surface?
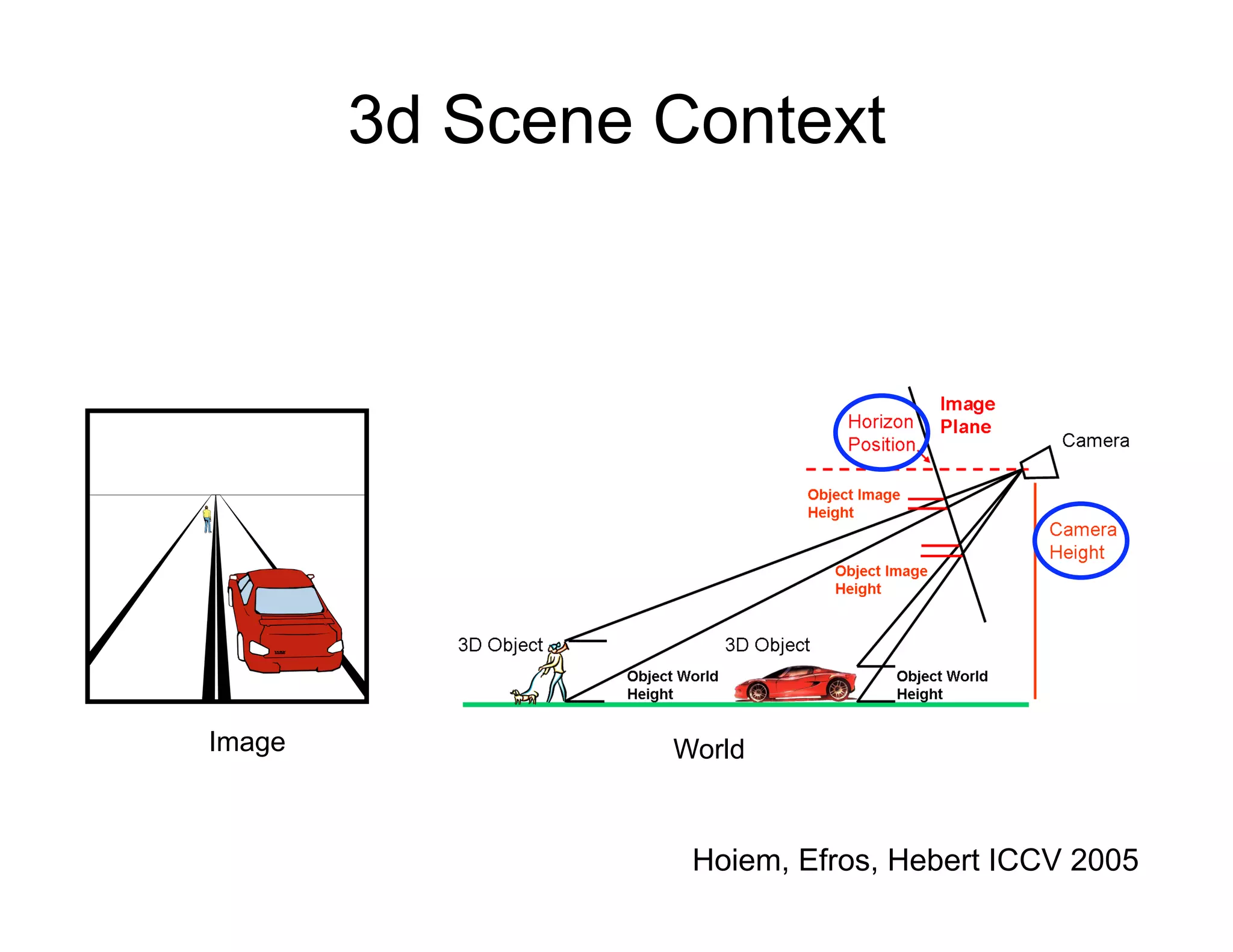
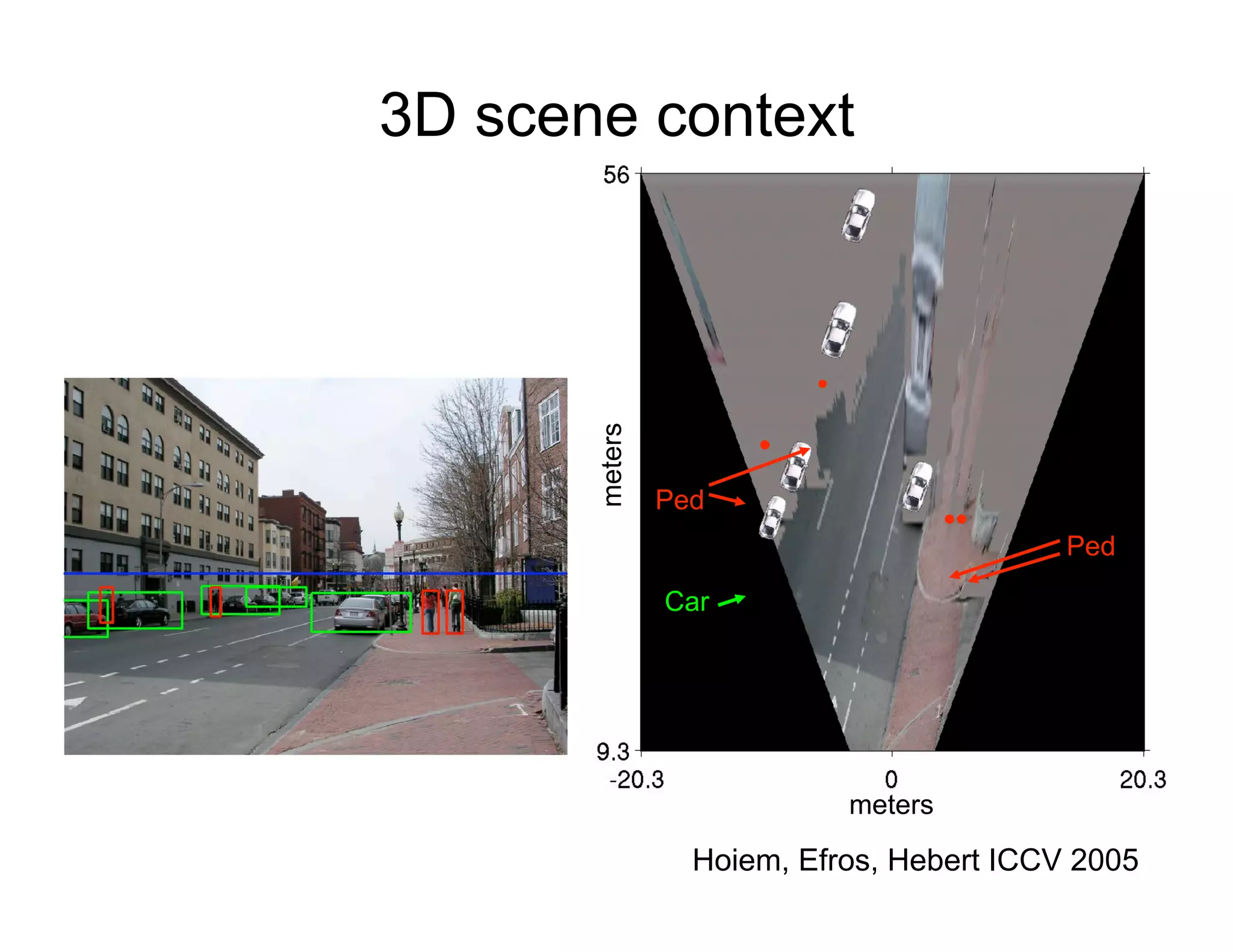
[Hoiem, Efros, Hebert ICCV 2005]
Support?
Slide by Derek Hoiem](https://image.slidesharecdn.com/nips09torralbauvs02-110515110823-phpapp01/75/NIPS2009-Understand-Visual-Scenes-Part-2-34-2048.jpg)


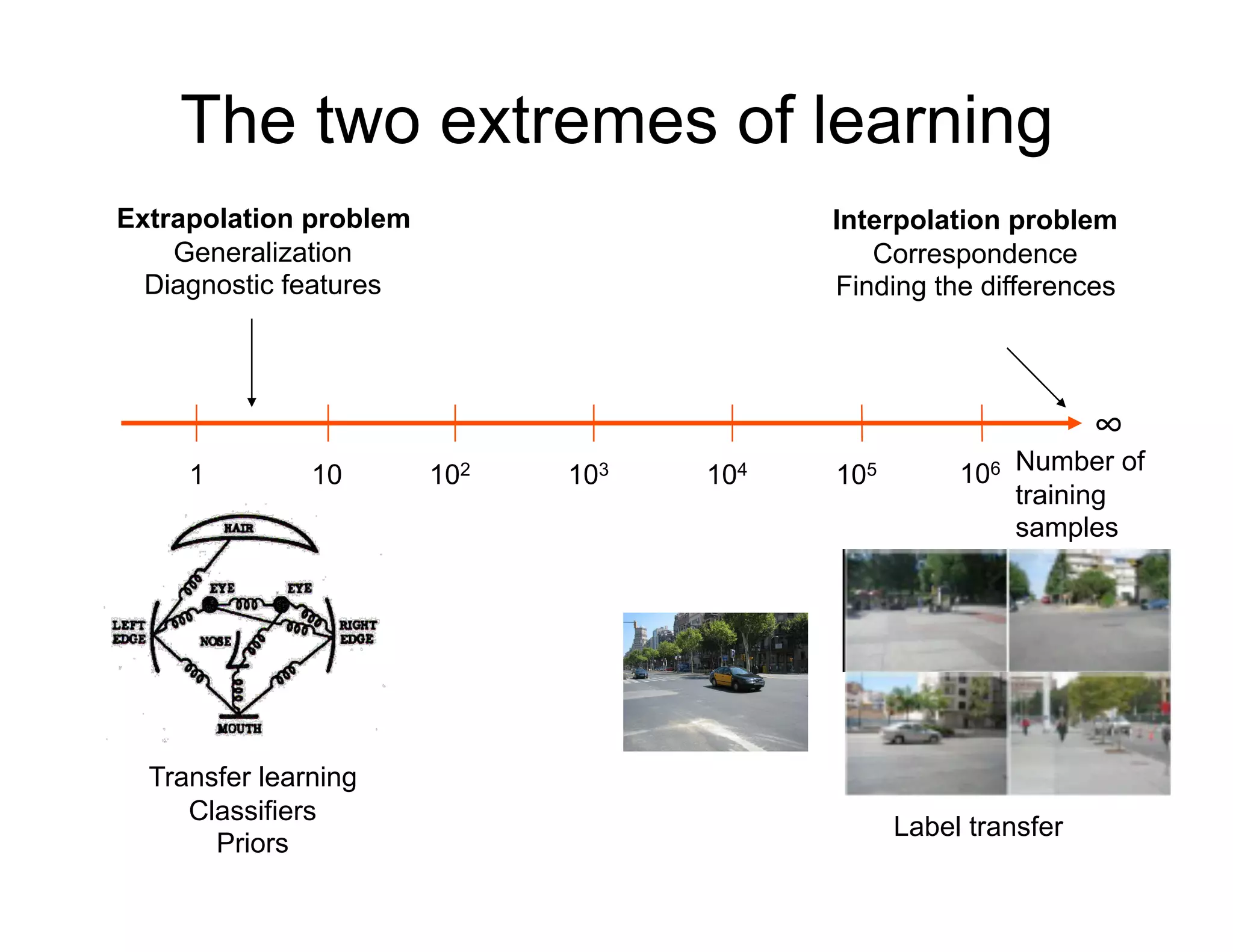
![The power of large collections
Google Street View PhotoToursim/PhotoSynth
(controlled image capture) [Snavely et al.,2006]
(register images based on
multi-view geometry)](https://image.slidesharecdn.com/nips09torralbauvs02-110515110823-phpapp01/75/NIPS2009-Understand-Visual-Scenes-Part-2-41-2048.jpg)