Downloaded 122 times



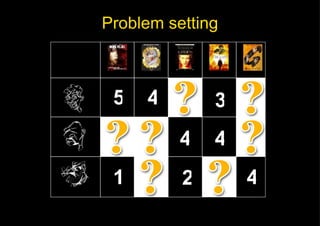



























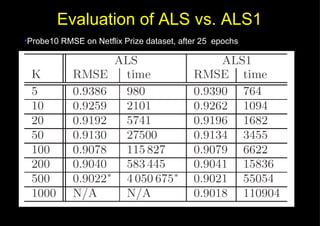
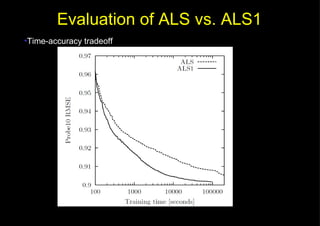
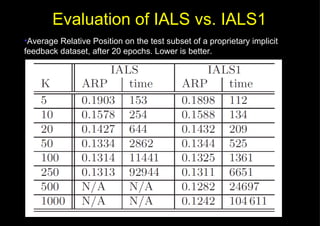
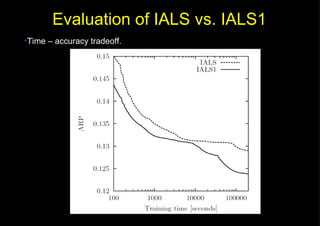



This document discusses fast matrix factorization techniques for collaborative filtering using alternating least squares (ALS) with modifications. It proposes two new methods: 1) ALS1, which uses coordinate descent (optimizing one variable at a time) instead of least squares when computing user/item vectors in ALS. 2) IALS1, which generates synthetic items to approximate the "null user" (who consumed nothing) in implicit ALS, instead of considering each zero entry. Evaluation on movie recommendation datasets shows ALS1 and IALS1 offer better time-accuracy tradeoffs than ALS and IALS, especially with large feature dimensions.













![Sensor Fusion Study - Ch15. The Particle Filter [Seoyeon Stella Yang]](https://cdn.slidesharecdn.com/ss_thumbnails/particlefilter-200815094542-thumbnail.jpg?width=640&height=640&fit=bounds)

![Sensor Fusion Study - Ch3. Least Square Estimation [강소라, Stella, Hayden]](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3-200521130800-thumbnail.jpg?width=640&height=640&fit=bounds)











































