Download as PDF, PPTX



![Complex network analysis 1/2
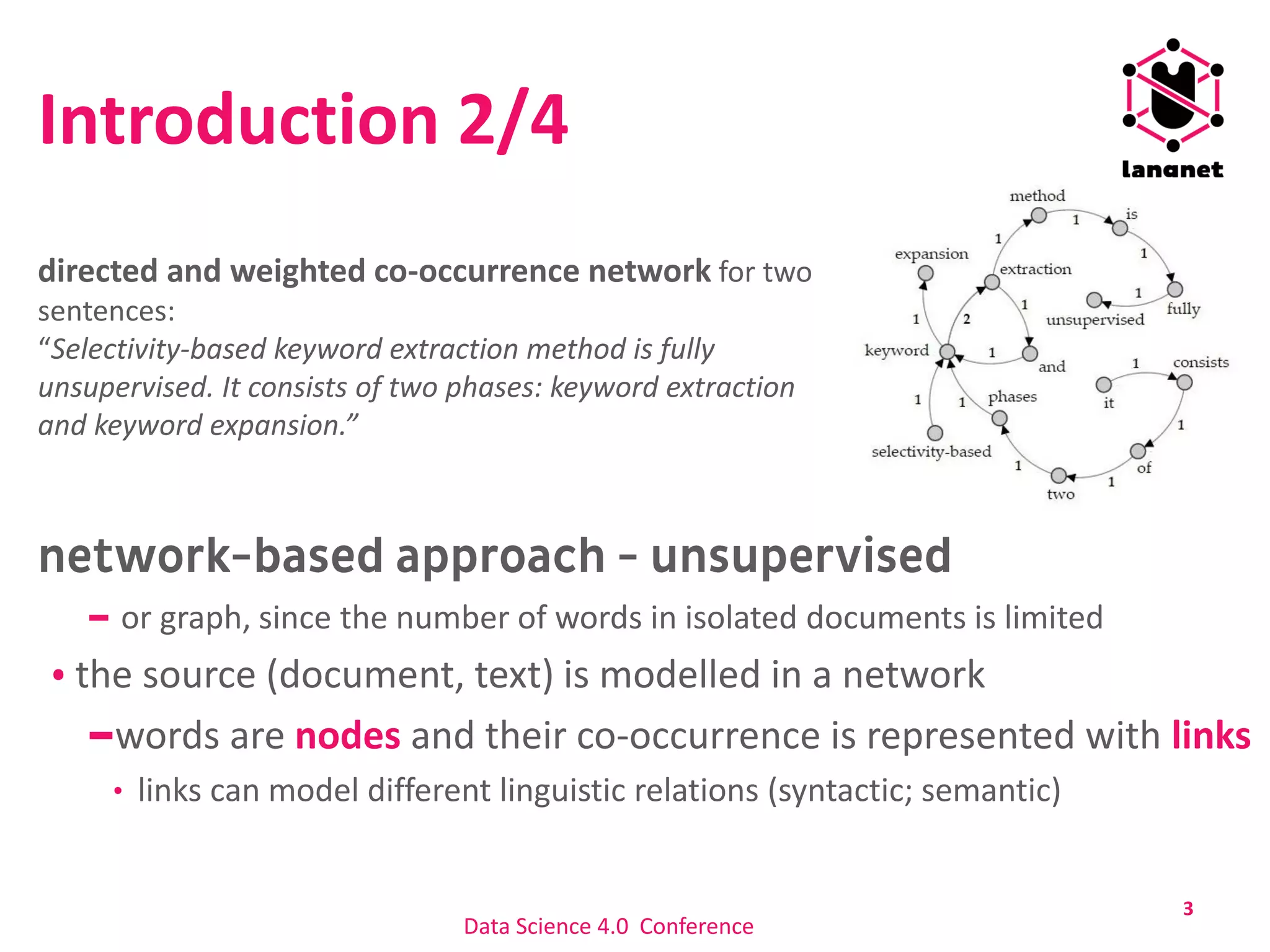
Directed and weighted network [Newman, 2010]
N – number of nodes
M – number of links
wij – weight for link which connects nodes i and j
Ki – node degree: number of links incident upon a node
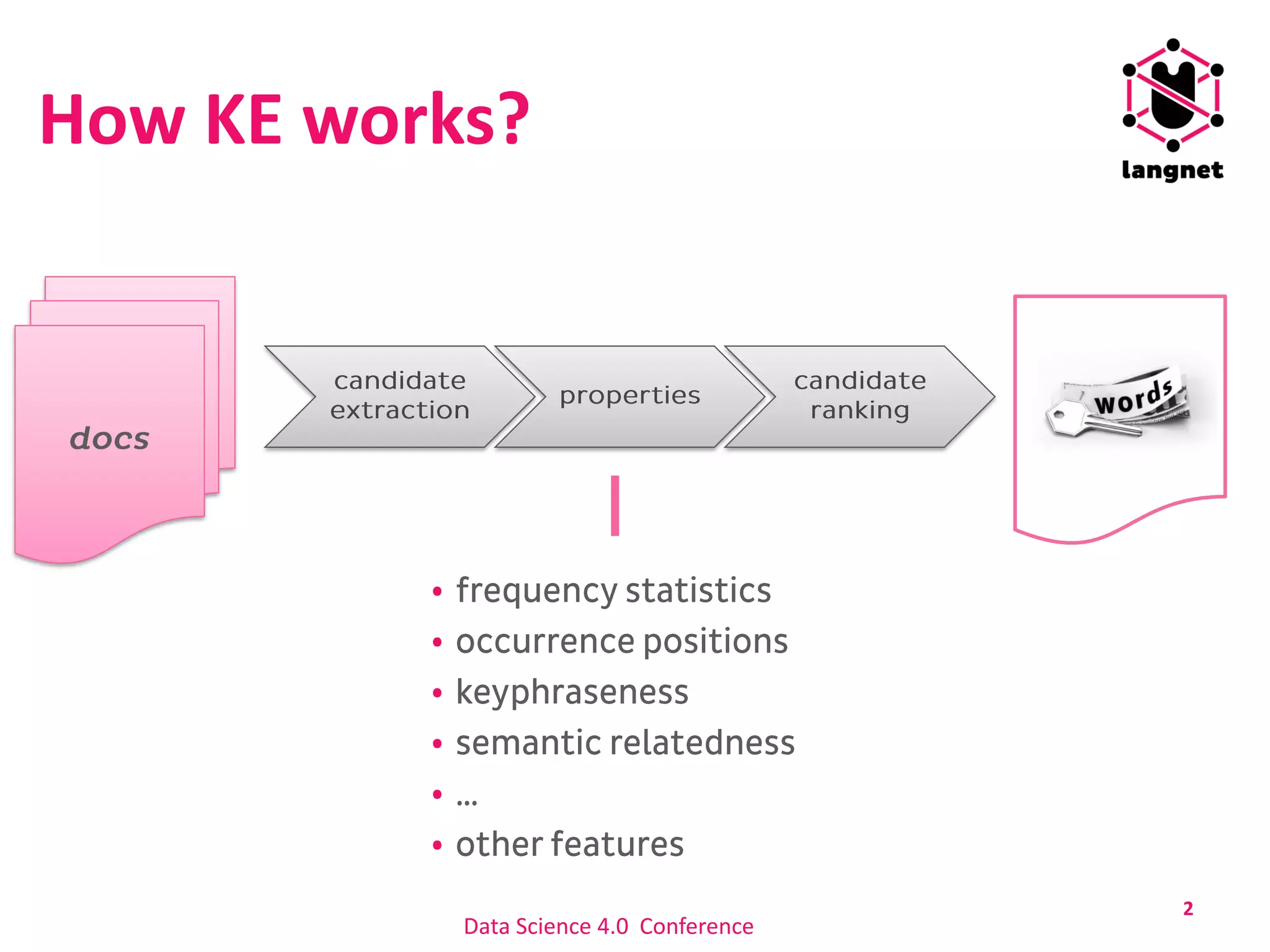
5
𝒅𝒄𝒊
(𝒊𝒏/𝒐𝒖𝒕)
=
𝒌𝒊
(𝒊𝒏/𝒐𝒖𝒕)
𝑵 − 𝟏
𝒄𝒄𝒊 =
𝑵 − 𝟏
σ𝒊≠𝒋 𝒅𝒊𝒋
𝒃𝒄𝒊 =
σ𝒊≠𝒋≠𝒌
𝝈𝒋𝒌(𝒊)
𝝈𝒋𝒌
(𝑵 − 𝟏)(𝑵 − 𝟐)
Data Science 4.0 Conference](https://image.slidesharecdn.com/extractingkeywordsfromtexts-sandramartincicipsic-181107124818/75/Extracting-keywords-from-texts-Sanda-Martincic-Ipsic-6-2048.jpg)
![3. Complex network analysis 1/2
strength and selectivity
selectivity
average weight distribution on the links of the single node
generalized selectivity
6
𝒔𝒊
𝒊𝒏/𝒐𝒖𝒕
=
𝒋
𝒘𝒋𝒊/𝒊𝒋
𝒈𝒆𝒊
α 𝒊𝒏/𝒐𝒖𝒕
= 𝒌𝒊
𝒊𝒏/𝒐𝒖𝒕 𝒔𝒊
𝒊𝒏/𝒐𝒖𝒕
𝒌𝒊
𝒊𝒏/𝒐𝒖𝒕
α
[Masucci &
Rodgers, 2009]𝒆𝒊
𝒊𝒏/𝒐𝒖𝒕
=
𝒔𝒊
𝒊𝒏/𝒐𝒖𝒕
𝒌𝒊
𝒊𝒏/𝒐𝒖𝒕
adapted from [Opsahl et al., 2010] in
[Beliga, Meštrović, Martinčić-Ipšić, 2016]
α∈ [0,1] – prefers nodes with higher
degrees
α ∈ [1, +∞] – prefers nodes with
lower degrees
𝛼 = 1– node strength
Data Science 4.0 Conference](https://image.slidesharecdn.com/extractingkeywordsfromtexts-sandramartincicipsic-181107124818/75/Extracting-keywords-from-texts-Sanda-Martincic-Ipsic-7-2048.jpg)
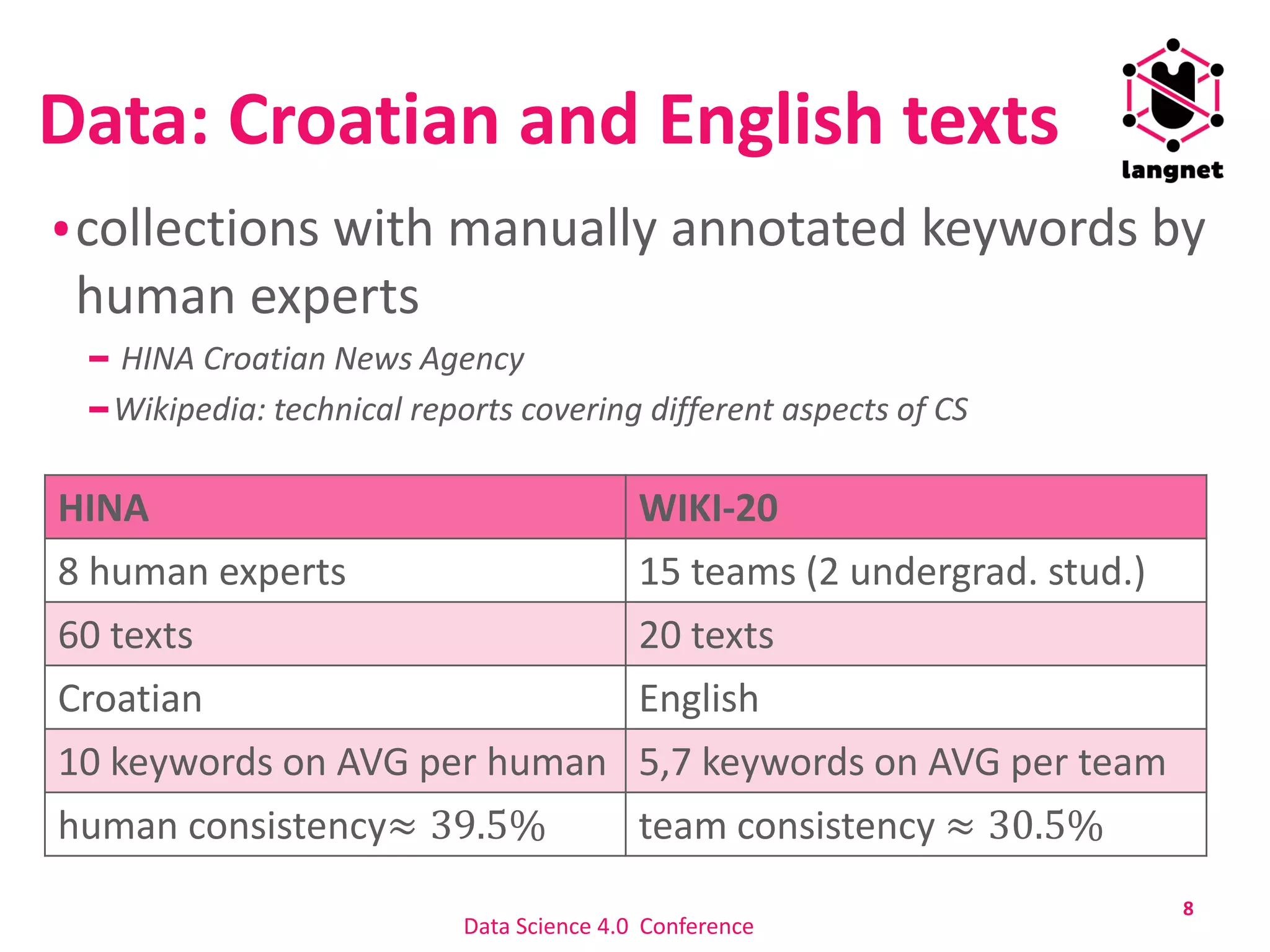

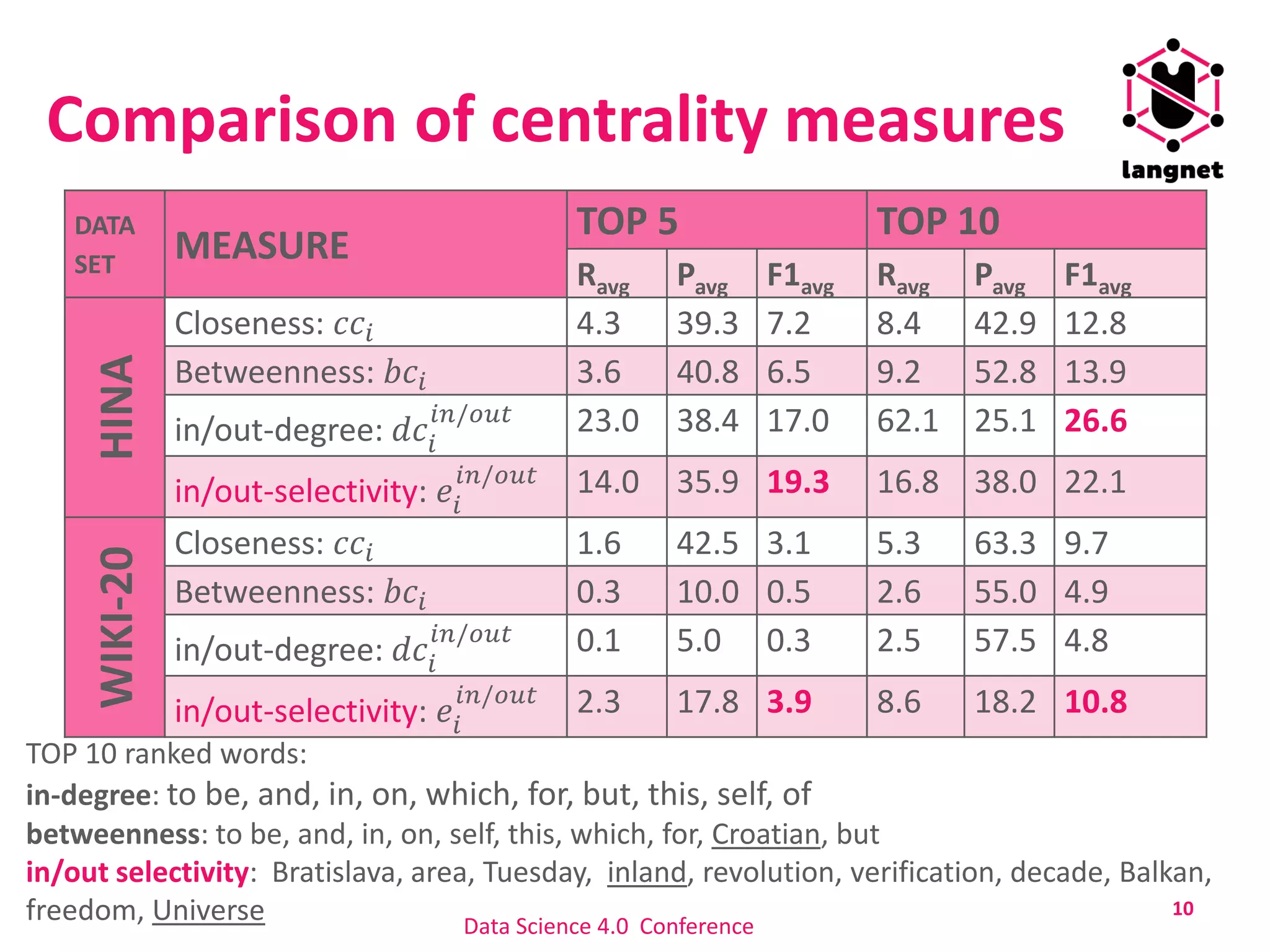

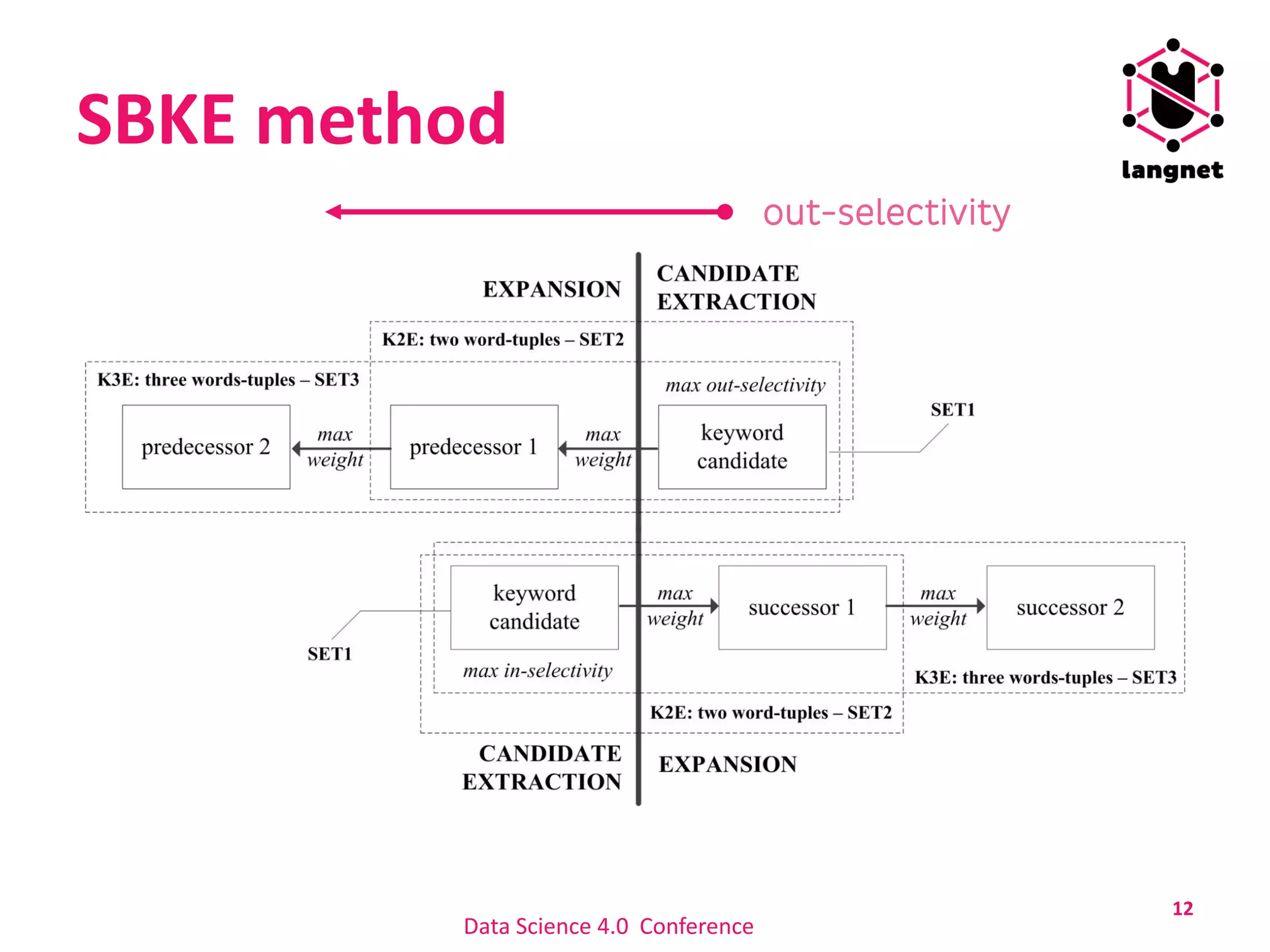
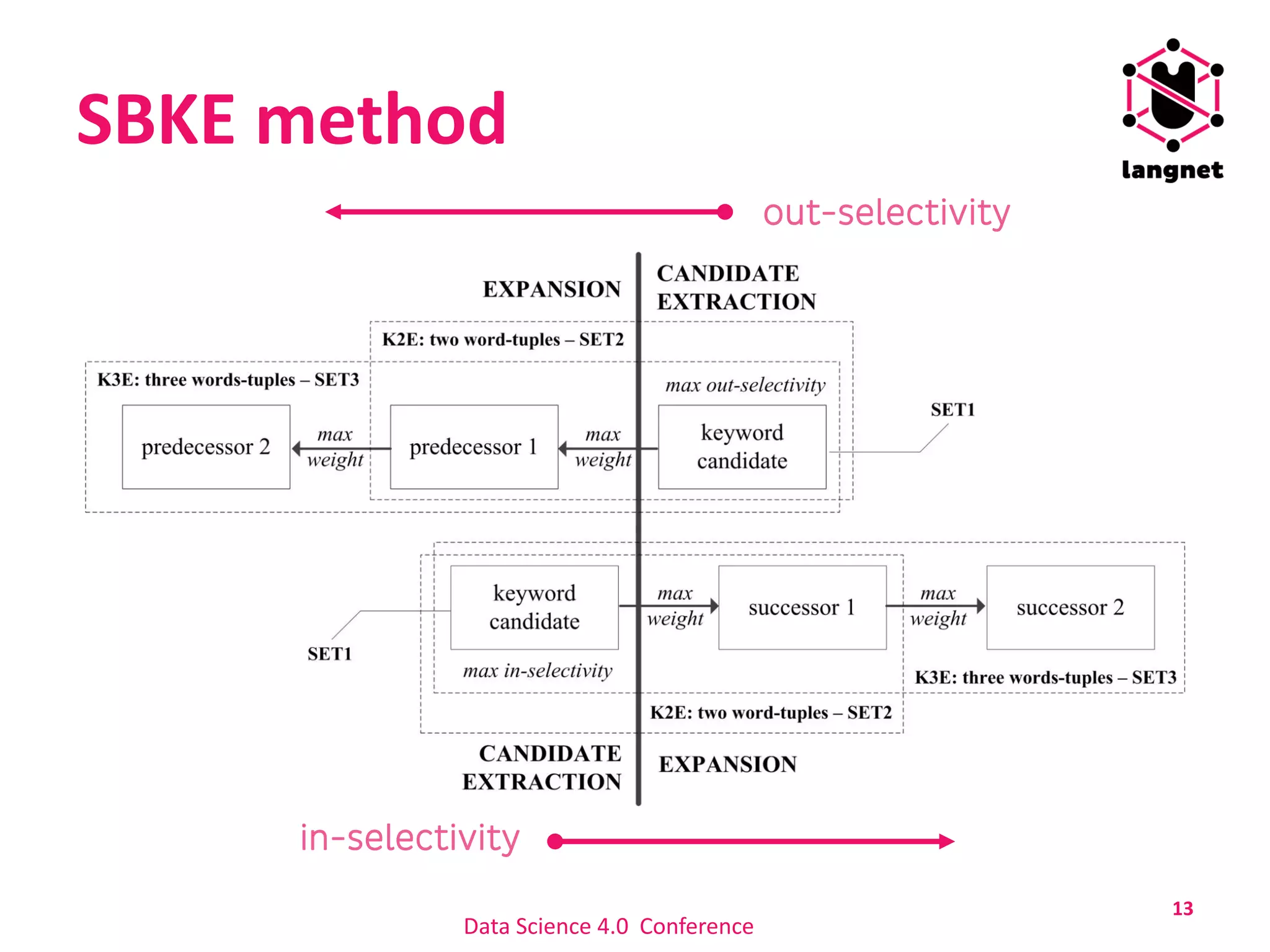
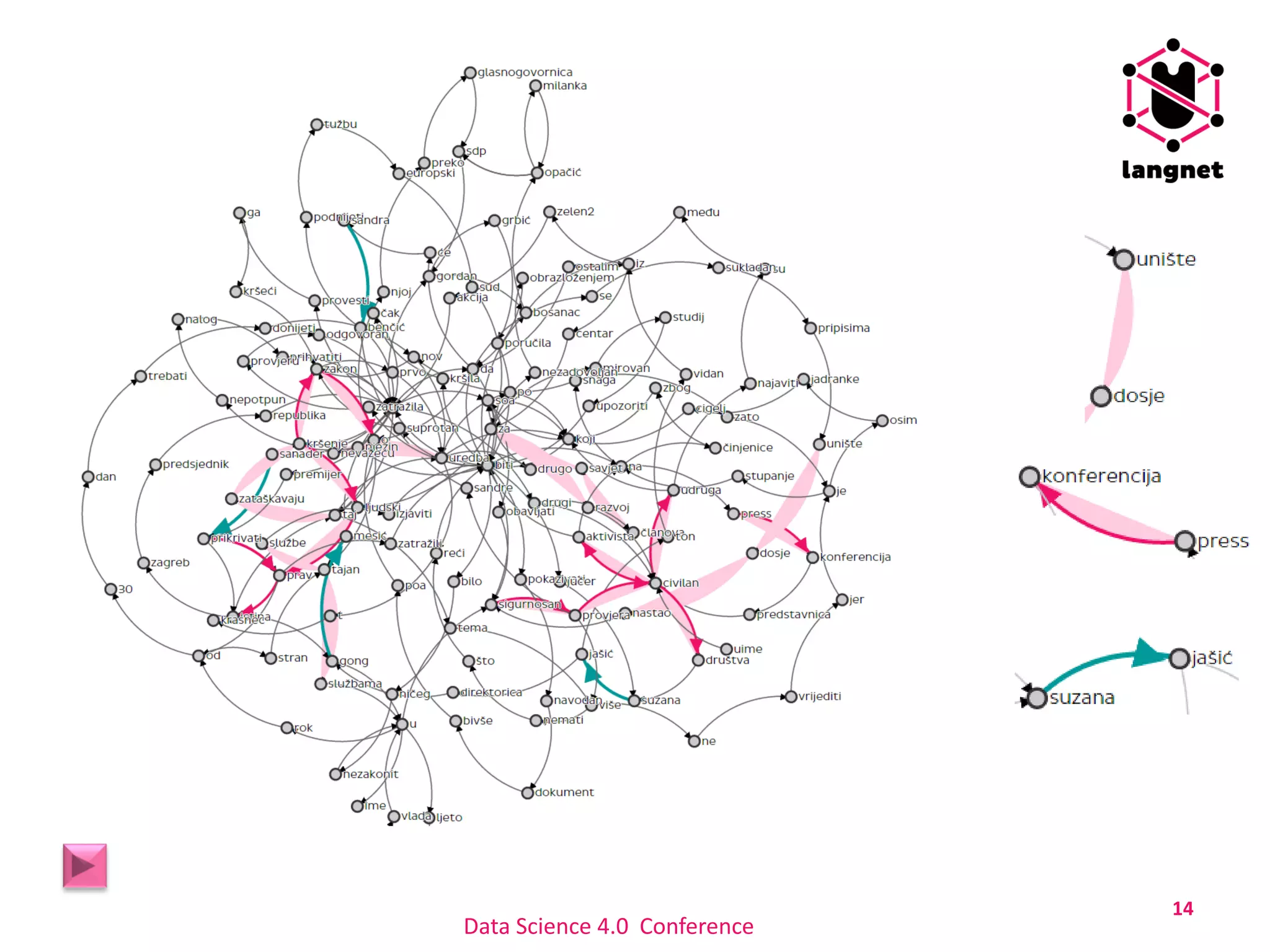

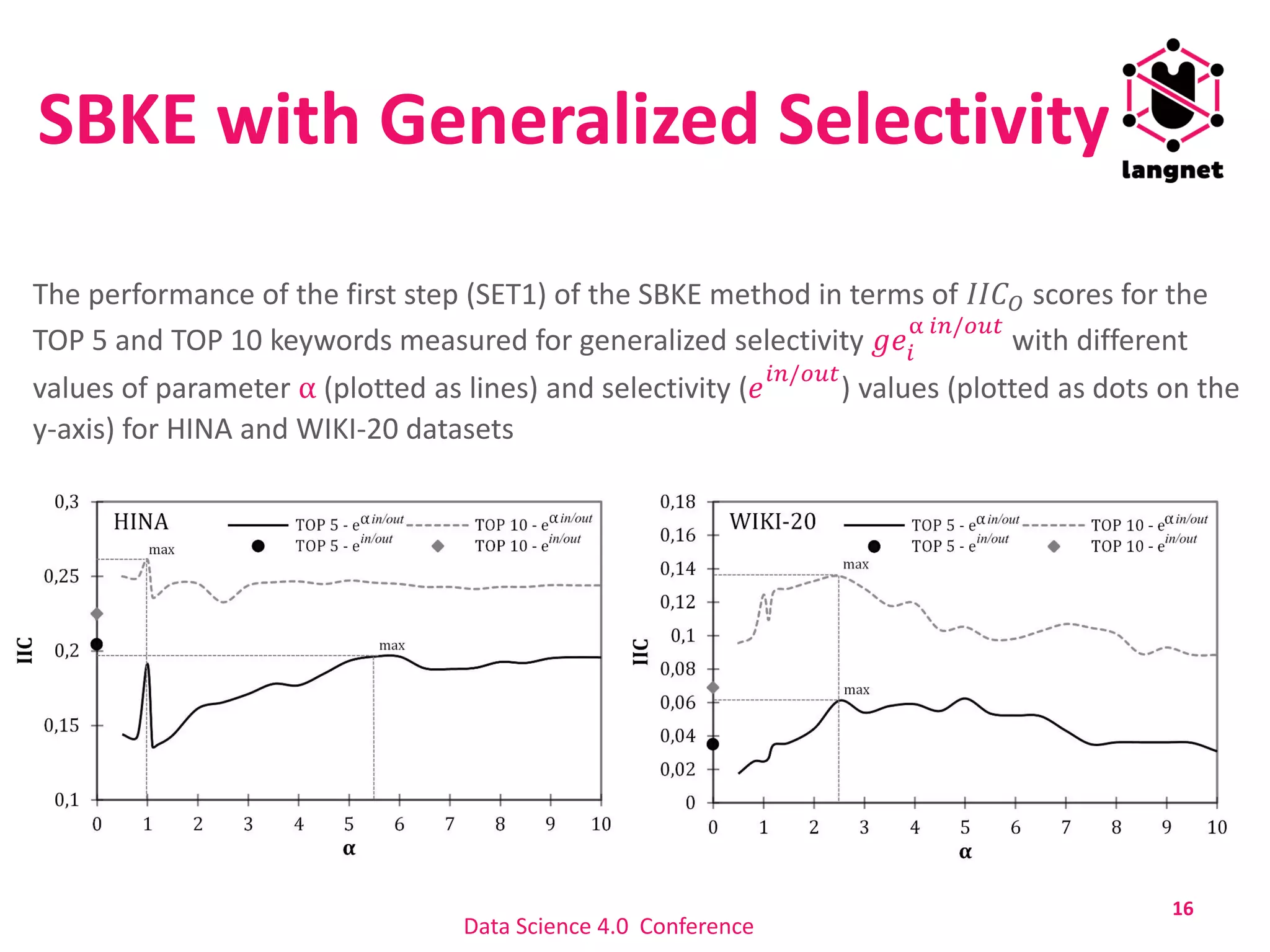








The document discusses a method for extracting keywords using a selectivity-based approach, highlighting the significance of keyword extraction in processing large textual datasets. It emphasizes the use of statistical and structural information in constructing networks of co-occurring words and details experimental findings on various datasets in Croatian and English. Additionally, it addresses challenges in keyword annotation and the method's advantages, such as portability to different languages without requiring linguistic knowledge.































![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
