Download as PDF, PPTX







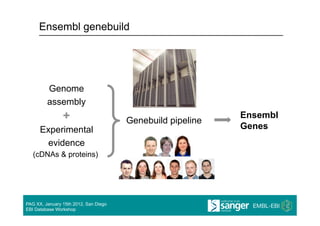















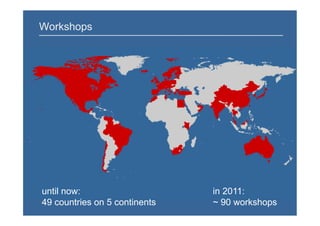








The document outlines the EBI database workshop presenting Ensembl and Ensembl Genomes, focusing on access to genome-scale data from sequenced species. It highlights developments in 2011, including new species additions and advancements in data analysis tools like the Variant Effect Predictor. Future plans for 2012 include new genome builds and the expansion of community annotation initiatives.





























































































