Downloaded 33 times

















![Thanks to: Jeremy Frey & CombeChem; Carole Goble & myGrid; Iain Buchan, Sean Bechhofer & e-Laboratories; myExperiment; David Abramson; Marco Roos; Stephen Downie & SALAMI; the e-Social Science Directorate; Malcolm Atkinson [email_address] Visit wiki.myexperiment.org This presentation is in myExperiment Pack 141 and http://www.slideshare.net/dder/evolution-of-eresearch](https://image.slidesharecdn.com/dderwarwick-100825020133-phpapp02/75/Evolution-of-e-Research-27-2048.jpg)

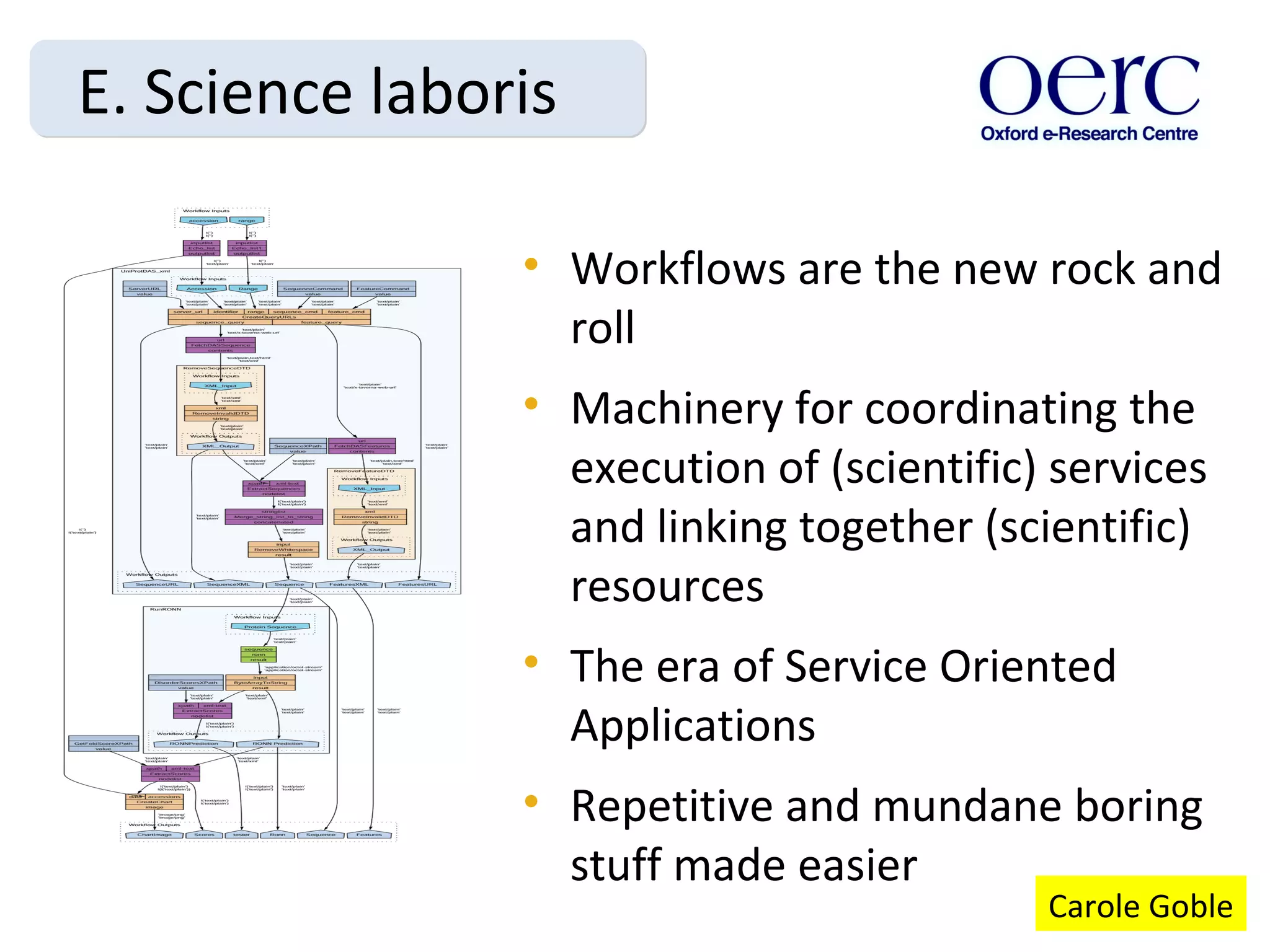
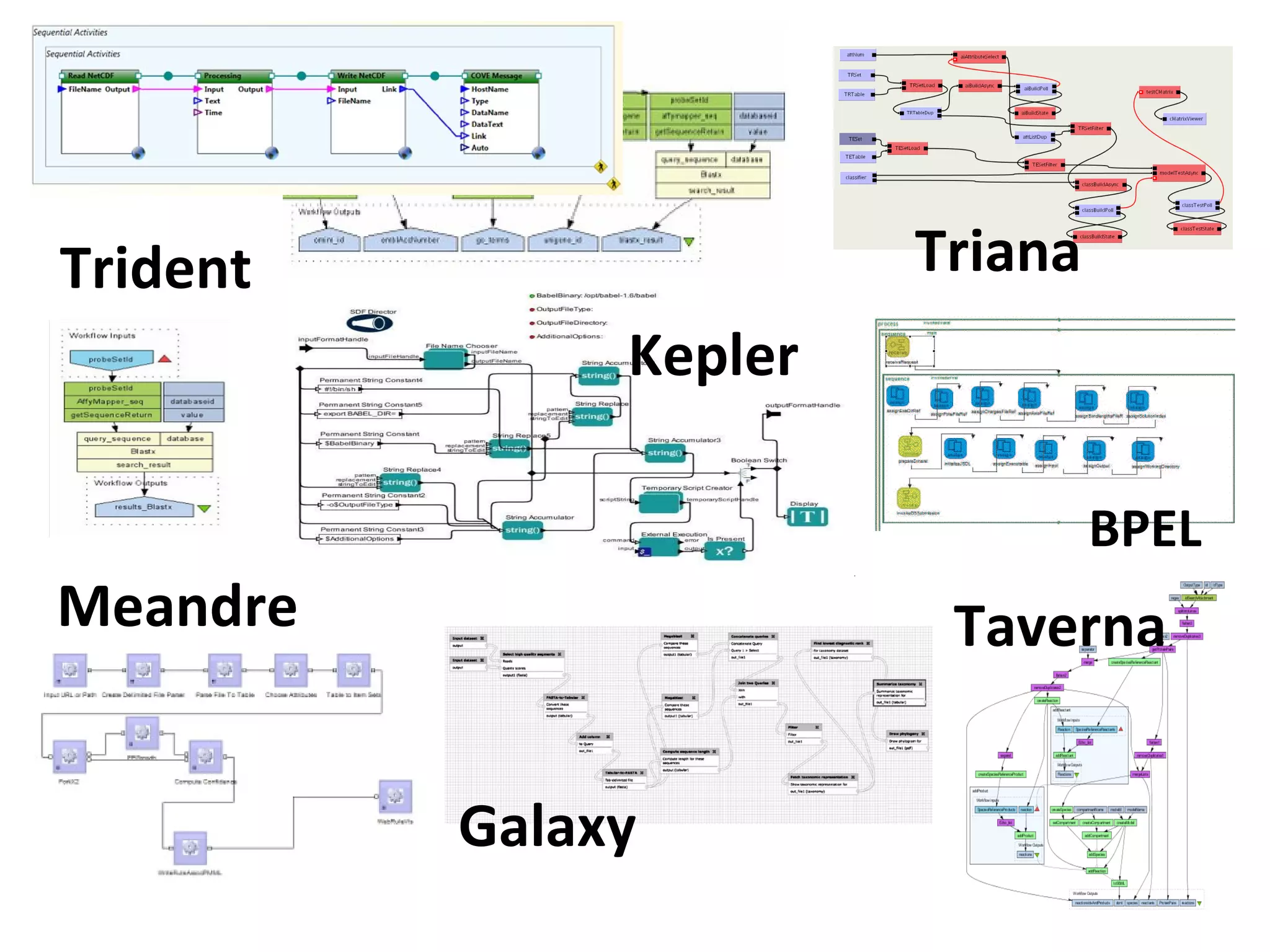
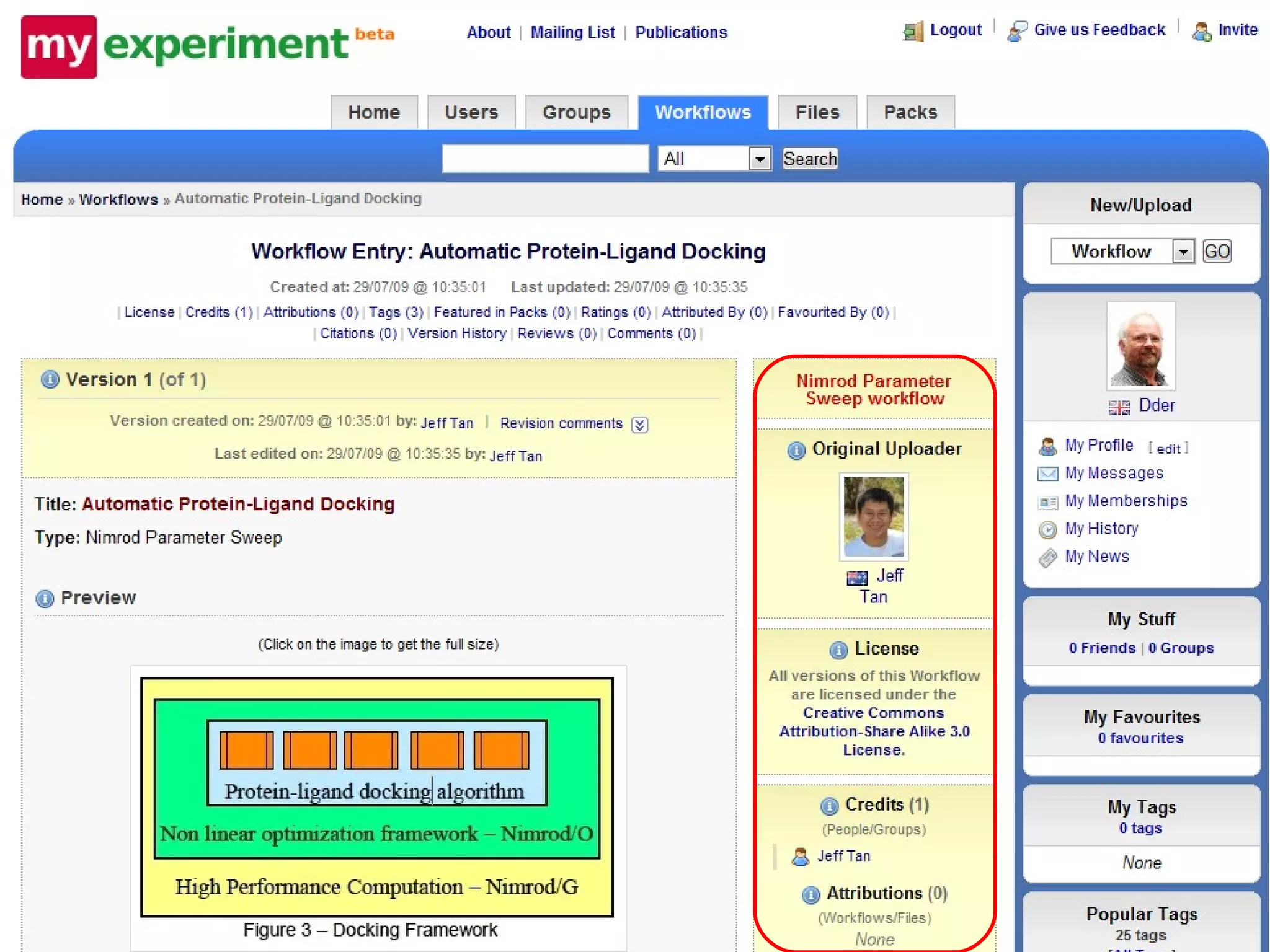
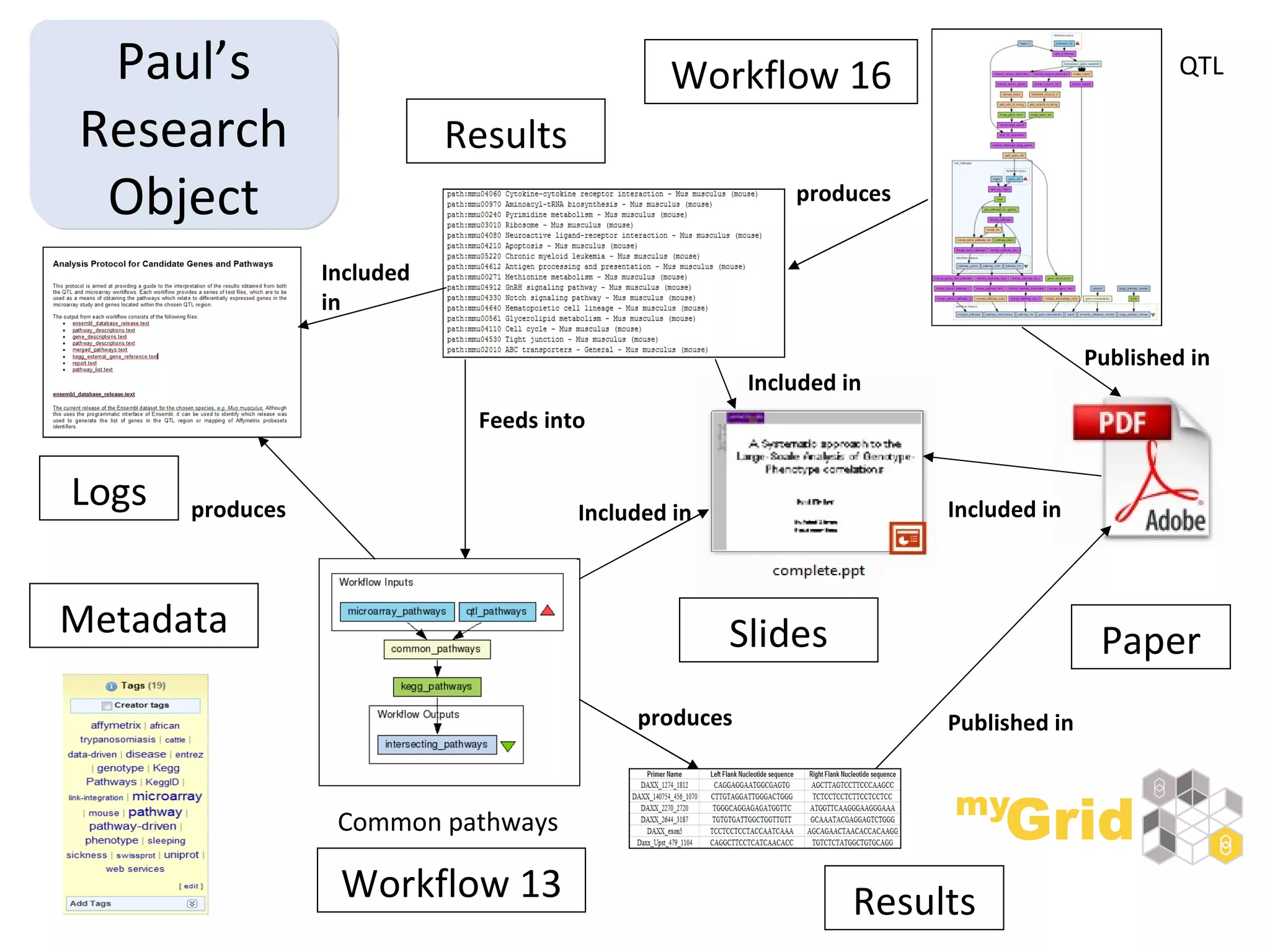
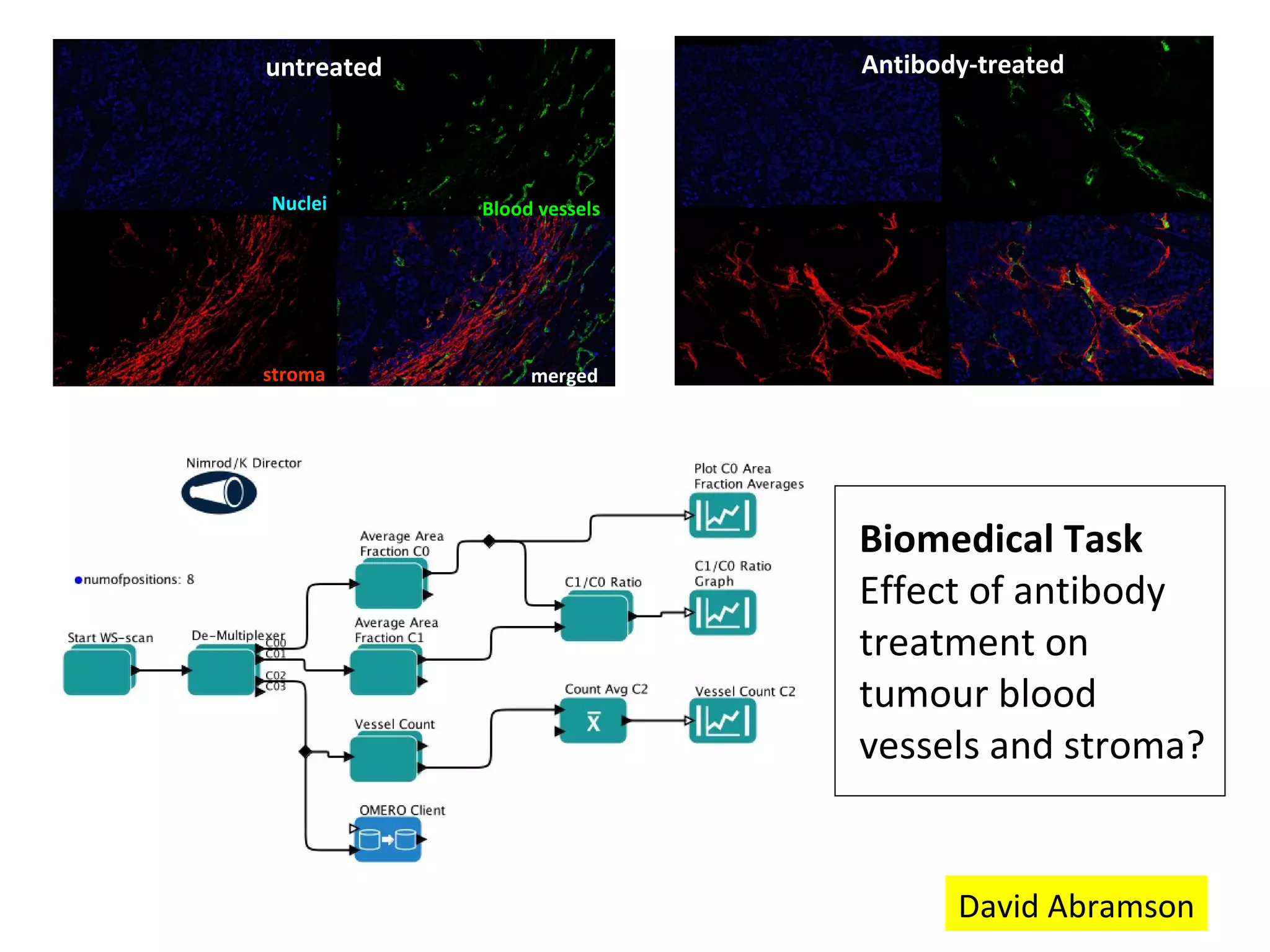
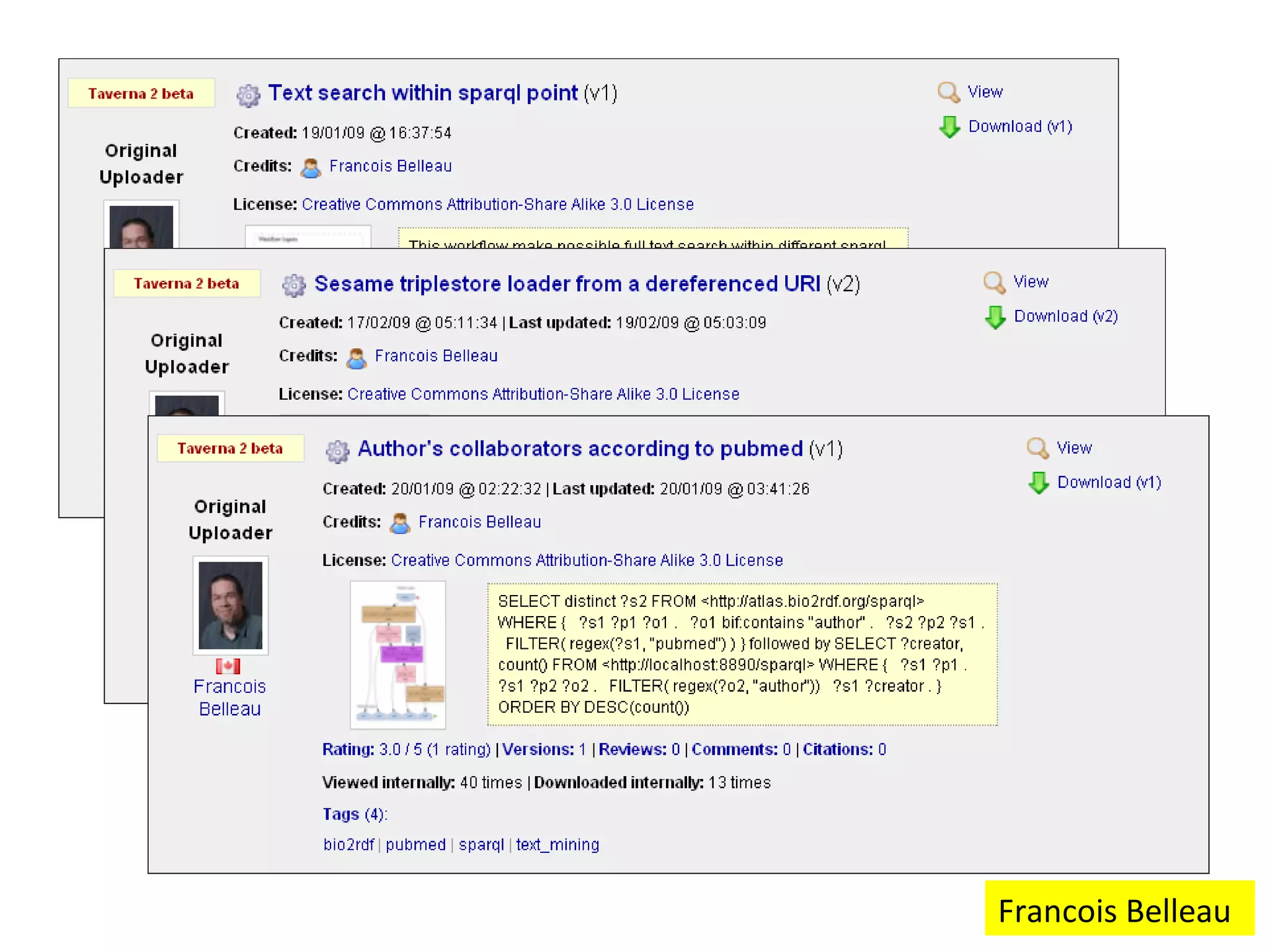
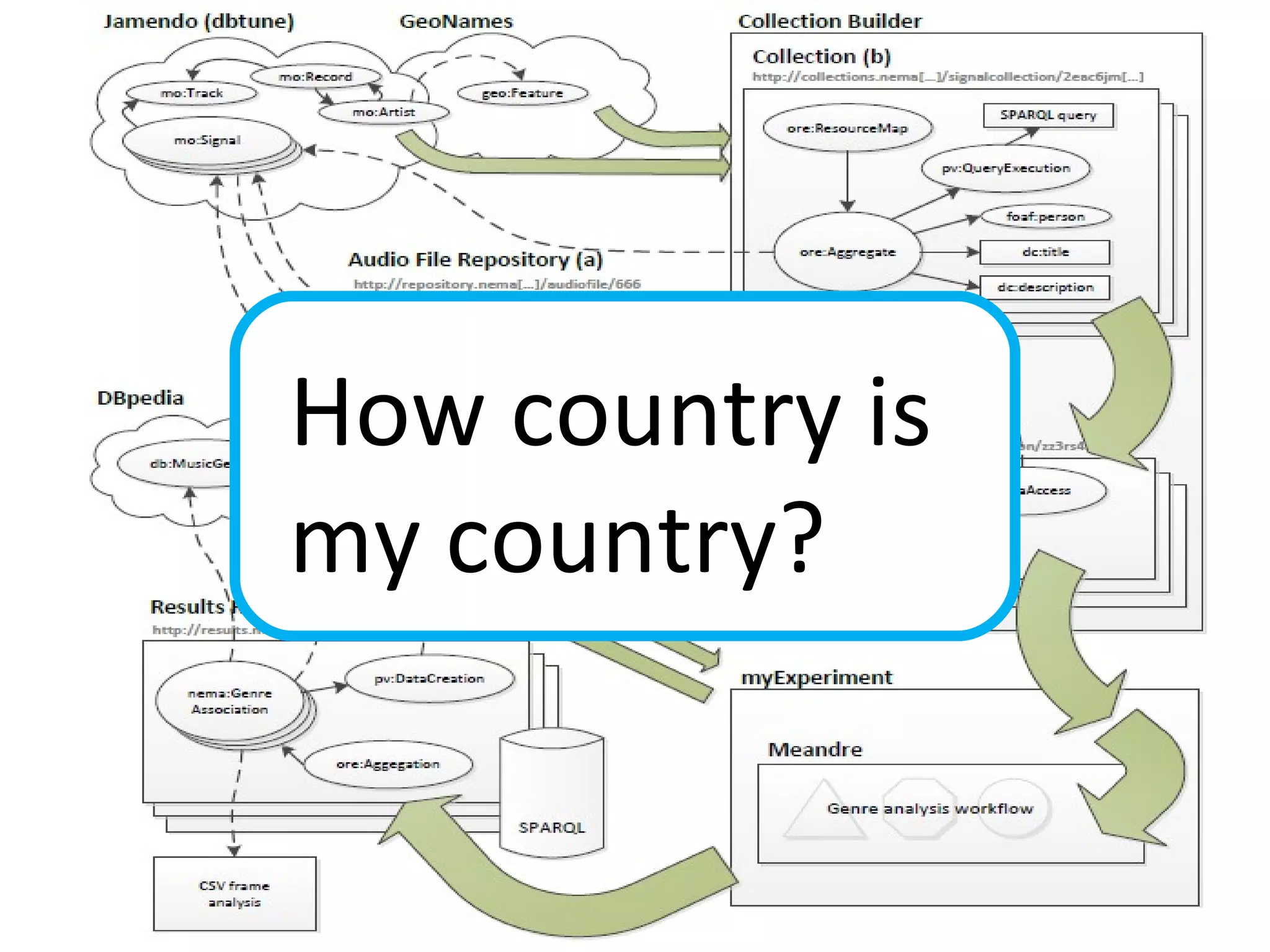
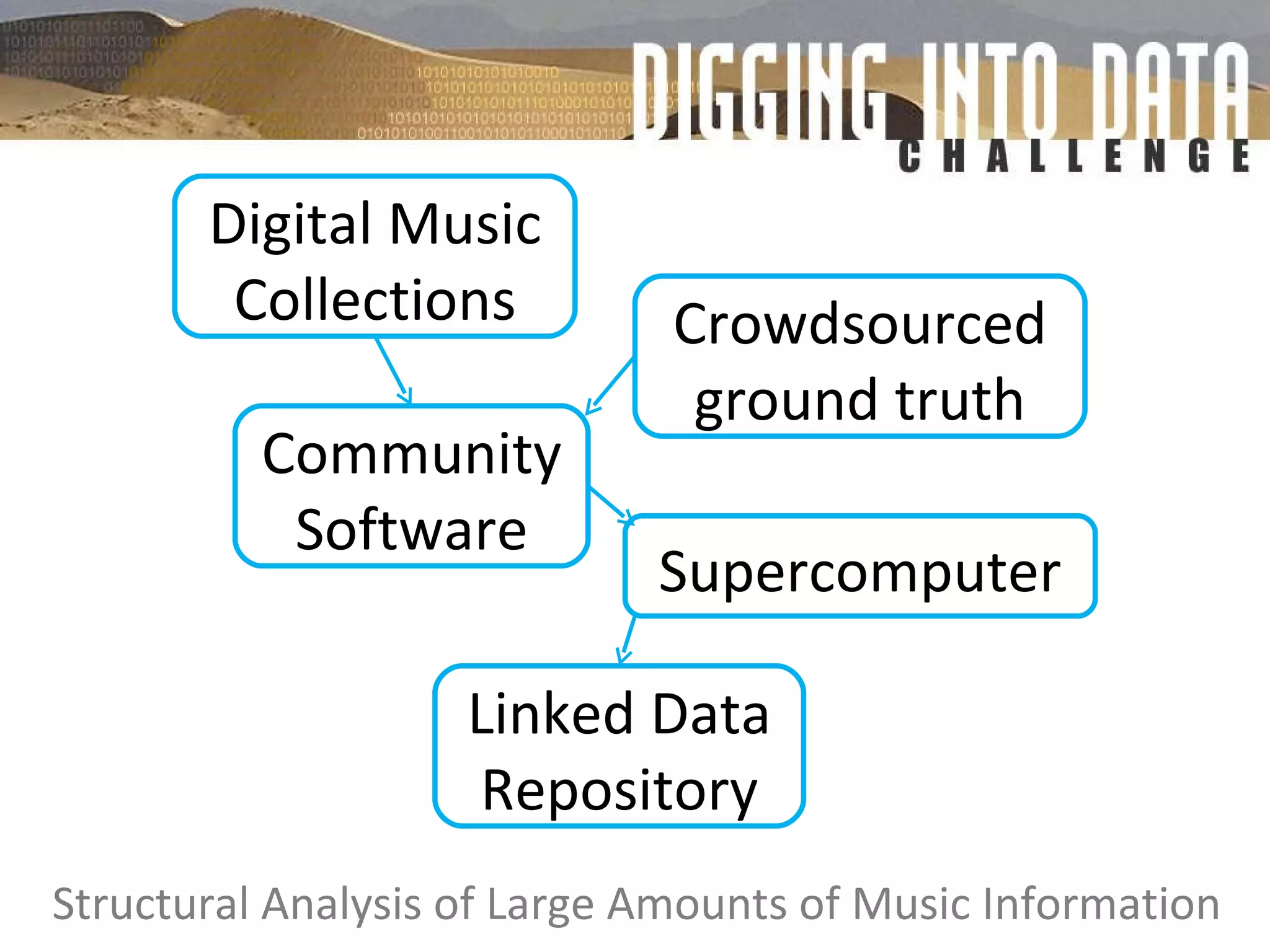
The document discusses the evolution of e-research, highlighting its journey from early adopters to the potential future characterized by global reuse and radical sharing of research tools and data. It describes the progression of e-science practices through different generations, emphasizing the shift towards automation and data-driven research methodologies. Various tools and platforms facilitating collaboration and knowledge sharing, such as myexperiment, are also mentioned as key components in this evolving landscape of e-research.





























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






