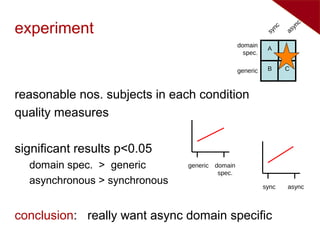
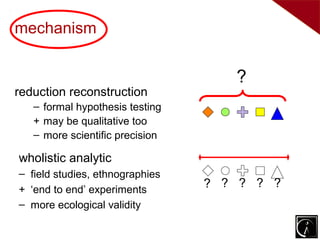
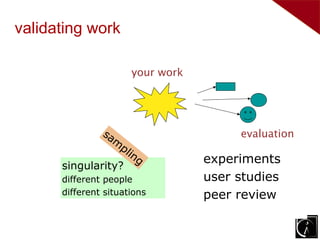
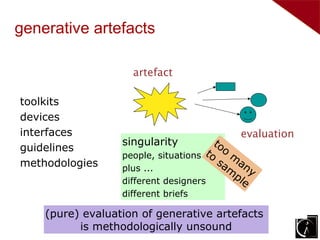
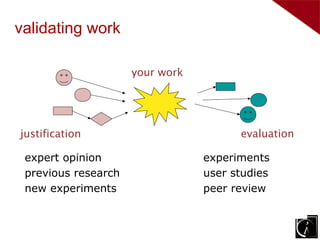
Three types of evaluation:
1) Formative evaluation aims to improve a design during development.
2) Summative evaluation determines if a design is good, often for contractual or sales purposes.
3) Investigative/exploratory evaluation aims to gain understanding, typically for research purposes.