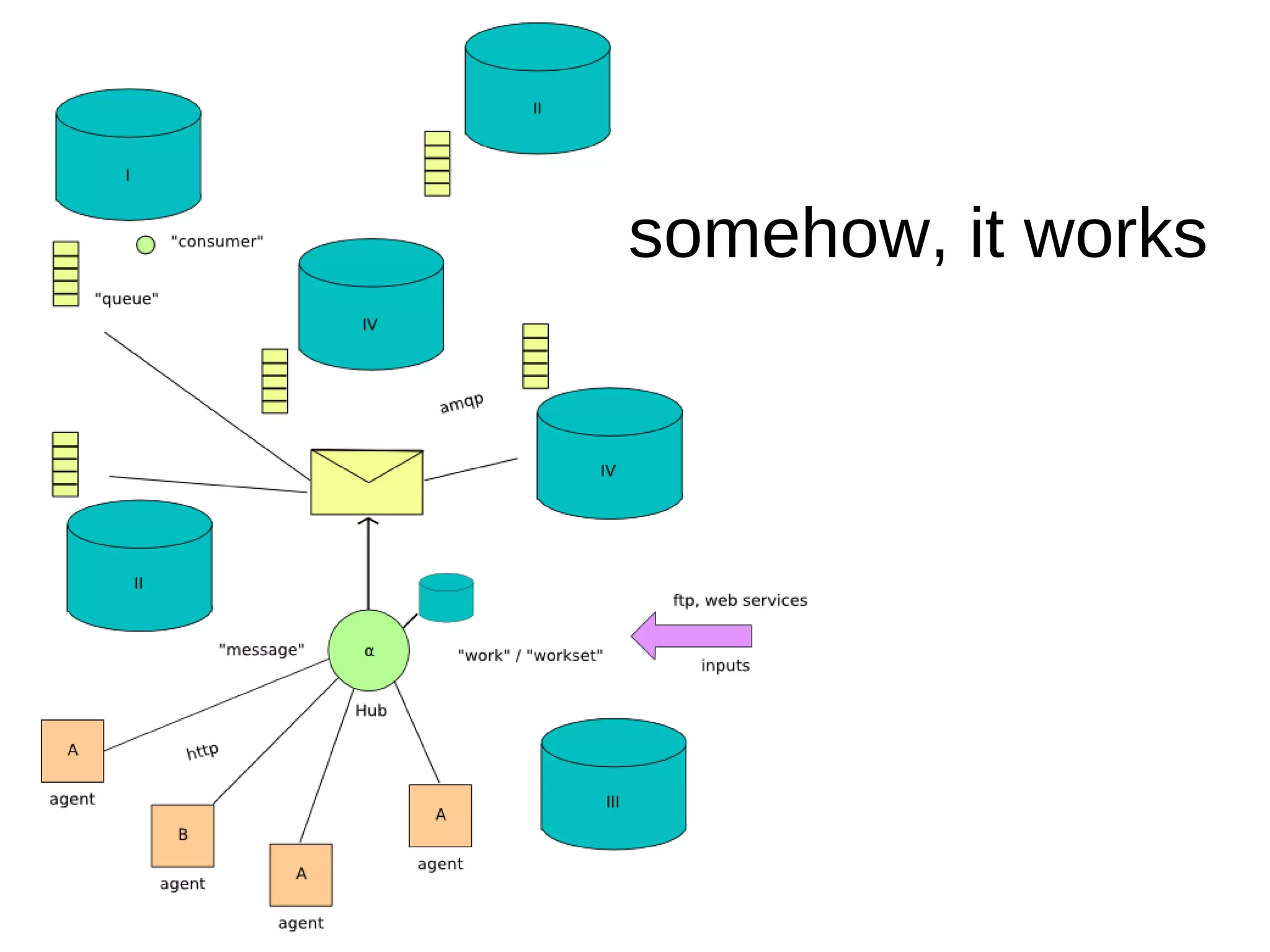
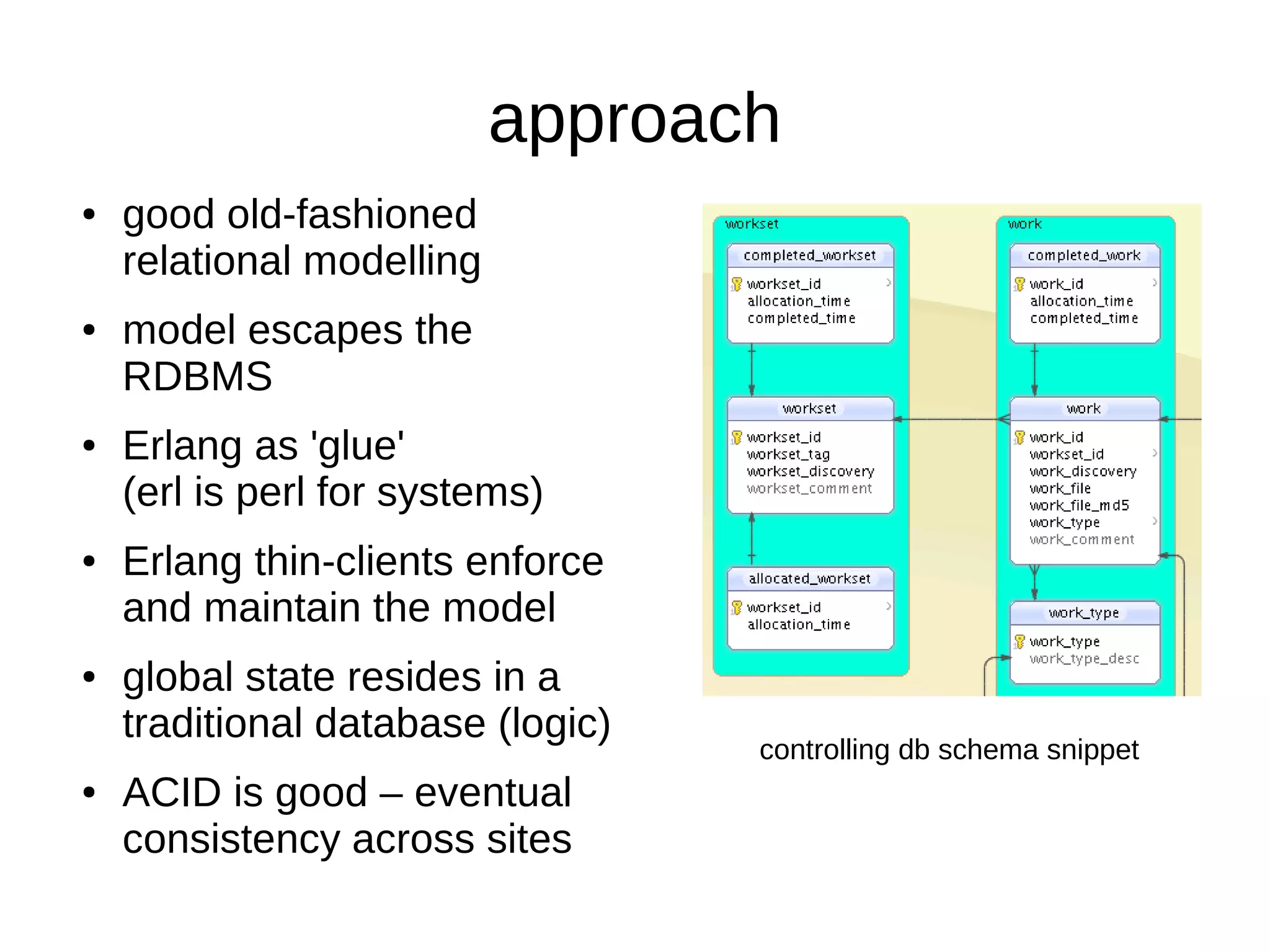
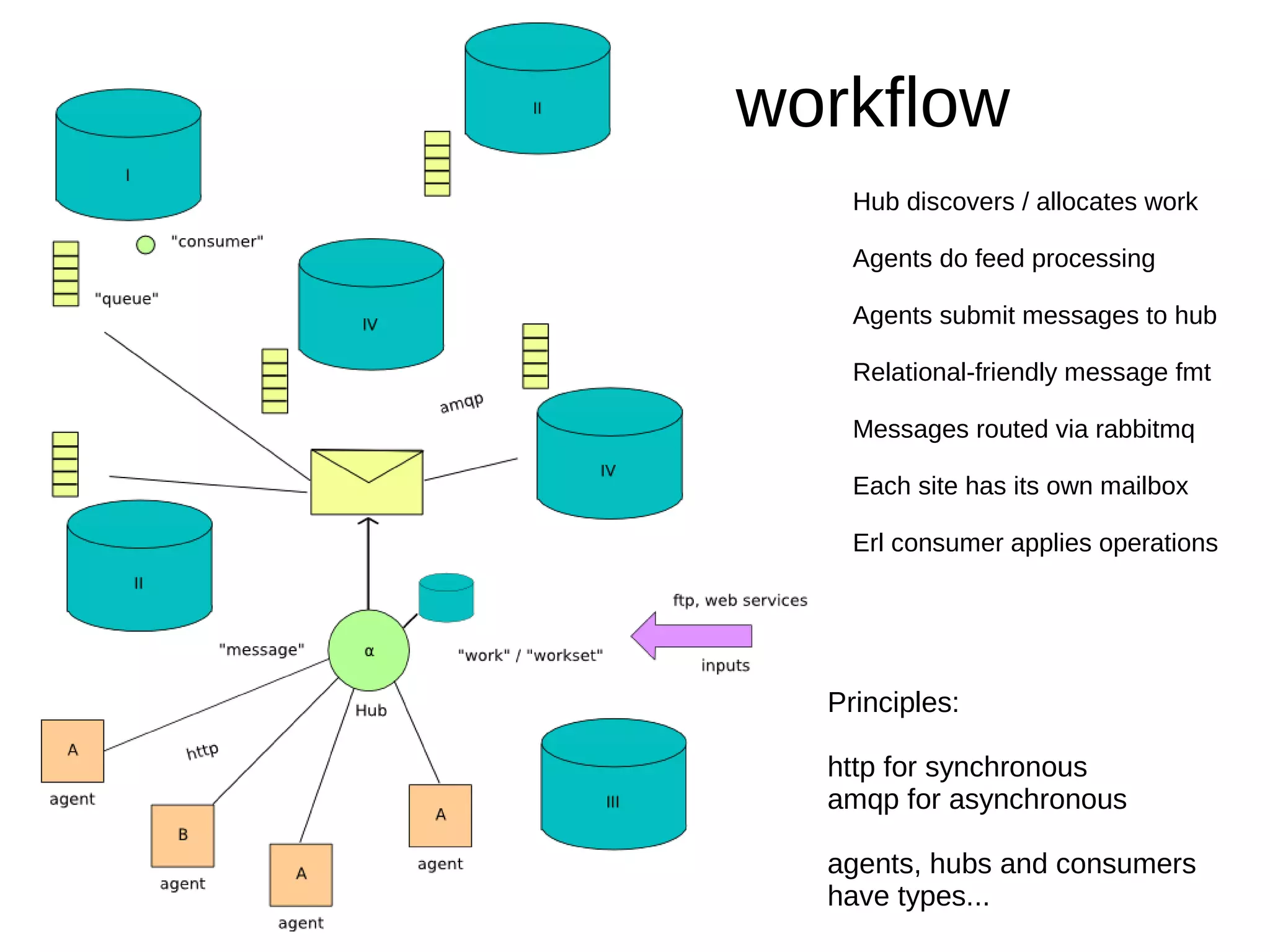
This document discusses using Erlang for data operations involving multiple relational databases with different schemas located in different locations. Erlang is well-suited for this due to its concurrency, scalability, and ability to act as "glue" between systems. An approach is described using Erlang thin clients to enforce and maintain the relational data model across databases while global state resides in a traditional database. Asynchronous message passing via RabbitMQ is used to route processing jobs between agents located at different sites.


![message format
"t":[ single transaction
{ "d":{"virtualdb1":"tracking data"},
"r":{"public":"mycases"},
"k":[
{"company":"6678928"} Transactions such as these
], are packaged in amqp
"z":null messages with appropriate
routing keys
},
{ "d":{"virtualdb1":"tracking data"},
"r":{"public":"mycases"},
"k":[
{"company":"6678928"}, key part
{"casenumber":"9513"}
],
"z":[
{"dateregistered":"2010-09-10"},
{"location":"LONDON"}, payload
{"statuscode":"ABCD"},
{"sum":"3983.00"}
] Each element of this transaction is
} declarative i.e. a logical assertion
] ... we use UPSERTs](https://image.slidesharecdn.com/erlang-for-data-ops-100917035303-phpapp01/75/Erlang-for-data-ops-5-2048.jpg)
![Nonterminals
json_to_erl.yrl
transaction items item
target attpairs attpair
pair key value bytearray bytes byte.
Terminals ':' atom string integer '[' ']' '{' '}' ','.
for yecc (LALR-1 Parser Generator)
% Test this code with: f(File), f(Scan), f(Status), {ok,
File} = file:read_file("new-format.json"),
yecc:yecc("json_to_erl.yrl","json_to_erl.erl"),
c(json_to_erl), {ok,Scan,Status} =
erl_scan:string(binary_to_list(File)), key -> string : unwrap('$1').
json_to_erl:parse(Scan). value -> atom : unwrap('$1').
value -> string : unwrap('$1').
Rootsymbol transaction. value -> integer : unwrap('$1').
transaction -> key ':' '[' items ']' : pack('$1','$4'). bytearray -> '[' ']' : [].
bytearray -> '[' bytes ']' : '$2'.
items -> item : ['$1']. bytes -> byte : ['$1'].
items -> item ',' items : ['$1'|'$3']. bytes -> byte ',' bytes : ['$1'|'$3'].
byte -> integer : unwrap('$1').
item -> '{' target ',' target ',' target ',' target '}' :
pack(item,['$2','$4','$6','$8']). Erlang code.
target -> key ':' '{' pair '}' : pack('$1','$4'). unwrap({_,_,V}) when is_integer(V) -> V;
target -> key ':' atom : pack('$1',null). unwrap({_,_,V}) when is_list(V) -> V;
target -> key ':' '[' ']' : pack('$1',null). unwrap({_,_,V}) -> V.
target -> key ':' '[' attpairs ']' : pack('$1','$4').
pack(Key,List) when Key == "t" -> {transaction,List};
attpairs -> attpair : ['$1']. pack(item,List) -> {item,List};
attpairs -> attpair ',' attpairs : ['$1'|'$3']. pack(Key,Tuple) when Key == "d" -> {dbvar,Tuple};
attpair -> '{' pair '}': '$2'. pack(Key,Tuple) when Key == "r" -> {relvar,Tuple};
pack(Key,List) when Key == "k" -> {key,List};
pair -> key ':' bytearray : {'$1', '$3'}. pack(Key,List) when Key == "z" -> {relation,List};
pair -> key ':' value : {'$1', '$3'}. pack(Key,List) -> {Key,List}.](https://image.slidesharecdn.com/erlang-for-data-ops-100917035303-phpapp01/75/Erlang-for-data-ops-6-2048.jpg)
![sql from our json
erl_to_sql({transaction, Items}) -> dict_to_sql(Dict) ->
items_to_sql(Items). {Targetdb, Dbver} = read_from_dict(Dict, dbvar),
{Targetsch, Targetrel} = read_from_dict(Dict, relvar),
items_to_sql(Items) -> case read_from_dict(Dict, key) of
{Sk, Sv} -> Keydefs = [Sk], Keyvals = [Sv];
items_to_sql([], Items). [{Sk, Sv}] -> Keydefs = [Sk], Keyvals = [Sv];
[] -> Keydefs = ["null"], Keyvals = ["null"];
items_to_sql(Statements, []) -> lists:reverse(Statements); null -> Keydefs = ["null"], Keyvals = ["null"];
items_to_sql(Statements, [H | T]) -> List -> {Keydefs, Keyvals} = split_keydefs_keyvals(List)
{item, Fields} = H, end,
Sql = sql_from_item(Fields), case read_from_dict(Dict, relation) of
% empty relation means DELETE
items_to_sql([Sql|Statements], T).
null ->
{Targetdb, lists:concat(
% storing all elements into a dict ["DELETE FROM "] ++ [Targetsch] ++ ["."] ++ [Targetrel] ++
% so that their order is not important [" WHERE "] ++ where_clause(Keydefs,Keyvals) ++ [";"]
% ---------------------------------------------------- )};
sql_from_item(Fields) -> % emtpy key means INSERT
Dict = dict:new(), Tuples when Keyvals == ["null"] ->
{Keys, Values} = split_pairs(Tuples),
sql_from_item(Dict, Fields). {Targetdb, "INSERT INTO " ++ Targetsch ++ "." ++ Targetrel ++ "
" ++
sql_from_item(Dict, []) -> dict_to_sql(Dict); commas_and_parentheses(Keys) ++ " VALUES " ++
sql_from_item(Dict, [H | T]) -> commas_and_parentheses(sql_quote(Values)) ++ ";"};
{Key,Val} = H, % if both key and relation are supplied we UPDATE
sql_from_item(dict:store(Key,Val,Dict), T). Tuples ->
{Targetdb, lists:concat(
["UPDATE "] ++ [Targetsch] ++ ["."] ++ [Targetrel] ++
[" SET "] ++ [pairs_to_sql(Tuples)] ++ [" WHERE "] ++
where_clause(Keydefs,Keyvals) ++ [";"]
)}
end.](https://image.slidesharecdn.com/erlang-for-data-ops-100917035303-phpapp01/75/Erlang-for-data-ops-7-2048.jpg)
![(simple http fileserver example)
mochiweb
-module(abstract_files,[Class]).
-behaviour(gen_server). init(Port) ->
code:add_path("deps"),
mochiweb_http:start([
{port, Port},
{loop, fun(Req) -> dispatch_requests(Req) end}
]),
{ok, []}.
%% CONTROLLER -------------------------------------------------------------------------
dispatch_requests(Req) ->
Path = Req:get(path),
Action = clean_path(Path),
erlang:apply(Class, handle, [Action, Req]).
handle(Action, Req) when Action == "/" ->
case file:read_file("lib/start.sh") of
{ok, Binary} -> ?SUPER:send_text(Req, 200, "text/plain", Binary);
{error, _} -> not_found(Req)
end;
send_file(Req, Filename, Binary) ->
Req:respond({ 200,
[
{"Content-Type", "application/octet-stream"},
{"Content-Transfer-Encoding", "base64"},
{"Content-disposition", lists:concat(["attachment; filename=",Filename])}
],
Binary
}).](https://image.slidesharecdn.com/erlang-for-data-ops-100917035303-phpapp01/75/Erlang-for-data-ops-8-2048.jpg)
![(simple consumer example)
rabbitmq
% handle call for subscribe
handle_call({subscribe, MsgCallback, QoS}, _From, State) ->
[{Conn}] = get_term(State, connection), still using 1.7 version of the client
[{Queue}] = get_term(State, queue), version 2.1 is out!
case get_term(State, consumer) of
[{_Consumer}] -> {reply, already_subscribed, State};
_ ->
try
#rabbit_queue{q=Q,passive=_P,durable=_D,exclusive=_E,auto_delete=_A} = Queue,
process_flag(trap_exit, true),
Consumer = spawn_link( own wrapper
fun() ->
process_flag(trap_exit, true), % configuration and startup example:
% opening a connection, channel and auth %
{Connection, Channel} = connect(Conn), % R = hubz_rabbit:new(abstract_rabbit, "token").
% asserting queue % C = R:connection("localhost","/","guest","guest").
assert_queue(Queue,Channel), % E = R:exchange("ONE","direct",false,true,false).
% setting QoS parameter % Q = R:queue("TWO",false,true,false,false).
set_prefetch_count(Channel,QoS), % B = R:binding("TWO","ONE","#").
% basic consume % R:start_link({C,E,Q,B}).
#'basic.consume_ok'{ consumer_tag = Tag } =
amqp_channel:subscribe(Channel, #'basic.consume'{ queue = Q }, self()),
consumer_loop(Connection, Channel, Tag, MsgCallback) end ),
ets:insert(State, {consumer, {Consumer}}),
ets:insert(State, {consumer_settings, {MsgCallback, QoS}}),
{reply, ok, State}
catch
_:_ -> {reply, error, State}
end R:subscribe(fun(_Key,Data)->io:format("~p~n",[Data]) end).
end;](https://image.slidesharecdn.com/erlang-for-data-ops-100917035303-phpapp01/75/Erlang-for-data-ops-9-2048.jpg)
![start(Id) ->
spawn(fun() ->
register(Id, self()),
process_flag(trap_exit, true),
Port = open_port({spawn, "epg "++atom_to_list(Id)}, [use_stdio, {line, 4096}]),
epg
loop(Port)
end).
uses epg.c, libpq-based
collect_response(Port, RespAcc, LineAcc) -> for connecting to postgres
receive
{Port, {data, {eol, "!eod!"}}} ->
{data, lists:concat(lists:reverse(RespAcc))};
{Port, {data, {eol, "!error!"}}} ->
{error, lists:concat(lists:reverse(RespAcc))};
{Port, {data, {eol, "!connected!"}}} ->
{info, lists:concat(lists:reverse(RespAcc))};
{Port, {data, {eol, "!bye!"}}} ->
{bye, lists:concat(lists:reverse(RespAcc))};
{Port, {data, {eol, Result}}} ->
Line = lists:reverse([Result | LineAcc]),
collect_response(Port, [ [Line | "n"] | RespAcc], []);
{Port, {data, {noeol, Result}}} ->
collect_response(Port, RespAcc, [Result | LineAcc])
%% Prevent the gen_server from hanging indefinitely in case the
%% spawned process is taking too long processing the request.
after 72000000 ->
timeout
end.](https://image.slidesharecdn.com/erlang-for-data-ops-100917035303-phpapp01/75/Erlang-for-data-ops-10-2048.jpg)
![gen_event + gen_fsm + log4erl
-define(DISPATCH(Type, Data),
erlang:apply(
fun() -> ?EVENT:normal(Type, {Data, self()}, ?LINE) end, []
)
). ?DISPATCH(agent, {{Ip, SPort}, MyTag, unregistered_agent, MyEvent})
handle_event(Event, State) ->
MyName = State, gen_event:add_handler(mybus, {my_listener, Server}, Server)
% should we handle this event?
{{OriginServer,_P,_M,_C}, _E, _T} = Event,
case OriginServer of
MyName ->
% e.g. if MyName is 'my' we send it to the my_fsm handler module (gen_event)
gen_fsm:send_event(adapt(MyName,"fsm"), Event);
_ -> ok
end,
{ok, State}.
% handling messages/errors from *** agents ***
normal({{_S, _P, {_M, _L}, _C}, {_I, normal, agent, Data}, _Now}, State) -> (gen_fsm)
{EventData, _Pid} = Data,
% what differentiates agent events is the {data_validation_error, ...} part at the end
case EventData of
{_Agent, _Workfile, _Line, {data_validation_error, _Datatype, _Value}} ->
log4erl:warn(feed, "data validation error: ~p", [EventData]);
{_Agent, _Workfile, _Line, {data_validation_pkey_error, _Datatype, _Value}} ->
log4erl:error(feed, "data validation (in pkey!) error: ~p", [EventData]);
{_Agent, Workfile, Line, {no_rule_event, Code}} ->
log4erl:warn(feed, "no mapping rules for record type ~p (~s:~s)", [Code, Workfile, Line]);
{_Agent, Workfile, Line, {missing_data_event, Key}} ->
log4erl:info(feed, "missing data for mapping ~p (~s:~s)", [Key, Workfile, Line]);
% ... etc etc](https://image.slidesharecdn.com/erlang-for-data-ops-100917035303-phpapp01/75/Erlang-for-data-ops-11-2048.jpg)