Downloaded 318 times








![Inserting Documents
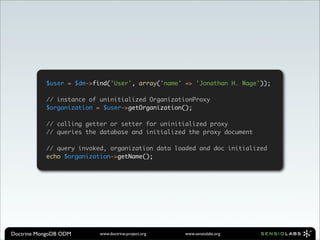
Insert a new user document and echo the newly generated id
$user = array(
'username' => 'jwage',
'password' => md5('changeme')
'active' => true
);
$coll->insert($user);
echo $user['_id'];
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-10-320.jpg)
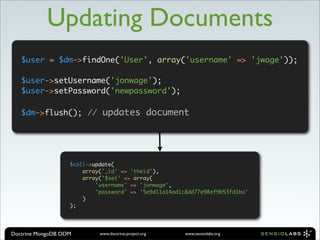
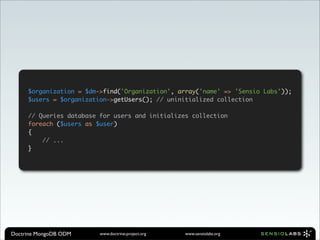
![Updating Documents
Update username and password and save the whole document
$user = $coll->findOne(array('username' => 'jwage'));
$user['username'] = 'jonwage';
$user['password'] = md5('newpassword');
$coll->save($user);
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-11-320.jpg)











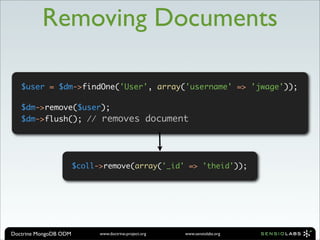





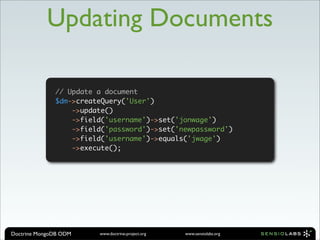
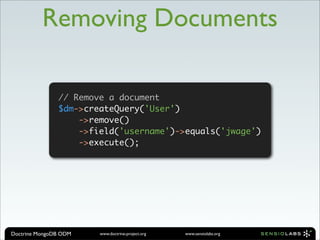

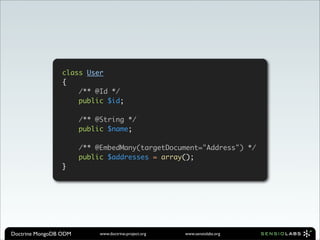

![$user = new User();
$user->name = 'Jonathan H. Wage';
$address = new Address();
$address->address = '6512 Mercomatic Ct';
$address->city = 'Nashville';
$address->state = 'Tennessee';
$address->zipcode = '37209';
$user->addresses[] = $address;
$dm->persist($user);
$dm->flush();
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-37-320.jpg)
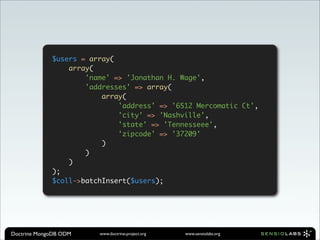

![$user = $dm->findOne('User', array('name' => 'Jonathan H. Wage'));
$user->addresses[0]->zipcode = '37205';
$dm->flush();
$coll->update(
array('_id' => 'theuserid'),
array('$set' => array('addresses.0.zipcode' => '37209'))
);
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-40-320.jpg)

![$user = $dm->findOne('User', array('name' => 'Jonathan H. Wage'));
$address = new Address();
$address->address = '475 Buckhead Ave.';
$address->city = 'Atlanta';
$address->state = 'Georgia';
$address->zipcode = '30305';
$user->addresses[] = $address;
$dm->flush();
$coll->update(
array('_id' => 'theuserid'),
array('$pushAll' => array(
'addresses' => array(
array(
'address' => '475 Buckhead Ave.',
'city' => 'Atlanta',
'state' => 'Georgia',
'zipcode' => '30305'
)
)
))
);
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-42-320.jpg)
![unset($user->addresses[0]->zipcode);
$dm->flush();
$coll->update(
array('_id' => 'theuserid'),
array(
'$unset' => array(
'addresses.0.zipcode' => 1
)
)
);
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-43-320.jpg)

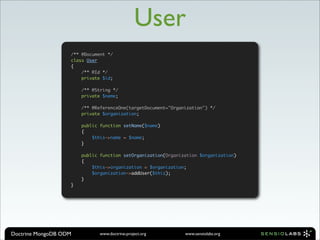
![Organization
/** @Document */
class Organization
{
/** @Id */
private $id;
/** @String */
private $name;
/** @ReferenceMany(targetDocument="User") */
private $users = array();
public function setName($name)
{
$this->name = $name;
}
public function addUser(User $user)
{
$this->users[] = $user;
}
}
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-45-320.jpg)
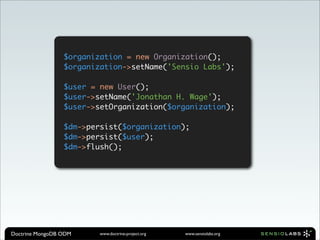

![Array
(
[_id] => 4c86acd78ead0e8759000000
[name] => Sensio Labs
[users] => Array
(
[0] => Array
(
[$ref] => User
[$id] => 4c86acd78ead0e8759010000
[$db] => doctrine_odm_sandbox
)
)
)
Array
(
[_id] => 4c86acd78ead0e8759010000
[name] => Jonathan H. Wage
[organization] => Array
(
[$ref] => Organization
[$id] => 4c86acd78ead0e8759000000
[$db] => doctrine_odm_sandbox
)
)
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-49-320.jpg)






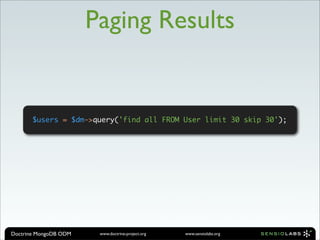
![QueryLanguage ::= FindQuery | InsertQuery | UpdateQuery | RemoveQuery
FindQuery ::= FindClause [WhereClause] [MapClause] [ReduceClause] [SortClause] [LimitClause]
[SkipClause]
FindClause ::= "FIND" all | SelectField {"," SelectField}
SelectField ::= DocumentFieldName
SortClause ::= SortClauseField {"," SortClauseField}
SortClauseField ::= DocumentFieldName "ASC | DESC"
LimitClause ::= "LIMIT" LimitInteger
SkipClause ::= "SKIP" SkipInteger
MapClause ::= "MAP" MapFunction
ReduceClause ::= "REDUCE" ReduceFunction
DocumentFieldName ::= DocumentFieldName | EmbeddedDocument "." {"." DocumentFieldName}
WhereClause ::= "WHERE" WhereClausePart {"AND" WhereClausePart}
WhereClausePart ::= ["all", "not"] DocumentFieldName WhereClauseExpression Value
WhereClauseExpression ::= "=" | "!=" | ">=" | "<=" | ">" | "<" | "in"
"notIn" | "all" | "size" | "exists" | "type"
Value ::= LiteralValue | JsonObject | JsonArray
UpdateQuery ::= UpdateClause [WhereClause]
UpdateClause ::= [SetExpression], [UnsetExpression], [IncrementExpression],
[PushExpression], [PushAllExpression], [PullExpression],
[PullAllExpression], [AddToSetExpression], [AddManyToSetExpression],
[PopFirstExpression], [PopLastExpression]
SetExpression ::= "SET" DocumentFieldName "=" Value {"," SetExpression}
UnsetExpression ::= "UNSET" DocumentFieldName {"," UnsetExpression}
IncrementExpression ::= "INC" DocumentFieldName "=" IncrementInteger {"," IncrementExpression}
PushExpression ::= "PUSH" DocumentFieldName Value {"," PushExpression}
PushAllExpression ::= "PUSHALL" DocumentFieldName Value {"," PushAllExpression}
PullExpression ::= "PULL" DocumentFieldName Value {"," PullExpression}
PullAllExpression ::= "PULLALL" DocumentFieldName Value {"," PullAllExpression}
AddToSetExpression ::= "ADDTOSET" DocumentFieldName Value {"," AddToSetExpression}
AddManyToSetExpression ::= "ADDMANYTOSET" DocumentFieldName Value {"," AddManyToSetExpression}
PopFirstExpression ::= "POPFIRST" DocumentFieldName {"," PopFirstExpression}
PopLastExpression ::= "POPLAST" DocumentFieldName {"," PopLastExpression}
InsertQuery ::= InsertClause InsertSetClause {"," InsertSetClause}
InsertSetClause ::= DocumentFieldName "=" Value
RemoveQuery ::= RemoveClause [WhereClause]
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-58-320.jpg)


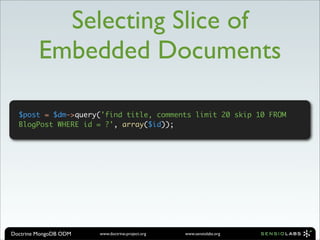





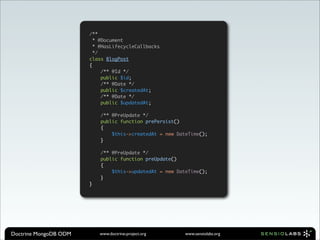



![Migrate Documents
With Old Field Name
/**
* @Document
* @HasLifecycleCallbacks
*/
class User
{
/** @Id */
public $id;
/** @String */
public $firstName;
/** @String */
public $lastName;
/** @PreLoad */
public function preLoad(array &$data)
{
if (isset($data['name']))
{
$e = explode(' ', $data['name']);
unset($data['name']);
$data['firstName'] = $e[0];
$data['lastName'] = $e[1];
}
}
Doctrine MongoDB ODM www.doctrine-project.org www.sensiolabs.org](https://image.slidesharecdn.com/mongodbodm-100907200403-phpapp01/85/Doctrine-MongoDB-Object-Document-Mapper-72-320.jpg)


Doctrine MongoDB ODM is an object document mapper for PHP that provides tools for managing object persistence with MongoDB. It allows developers to work with MongoDB documents as objects and provides a query API and change tracking functionality to make common operations like inserting, updating, and deleting documents straightforward. Doctrine abstracts away the low-level MongoDB driver to allow developers to work with documents and references between documents using familiar object-oriented patterns.




























































































