Downloaded 79 times






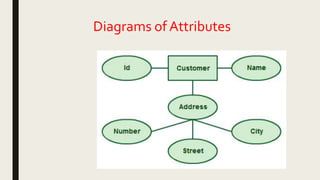




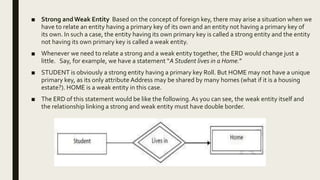


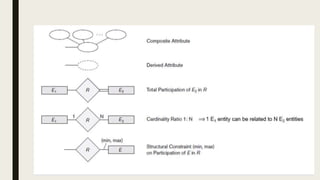
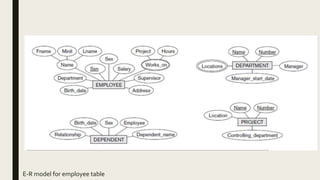

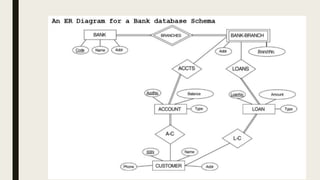
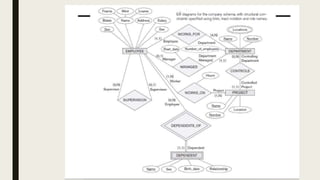

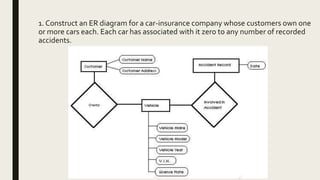
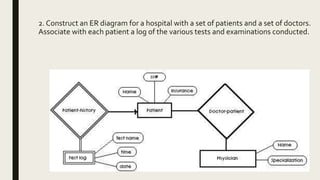
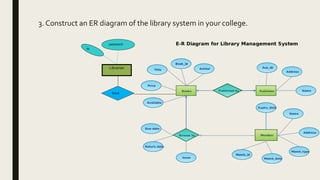
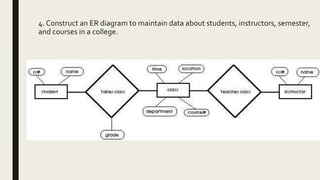
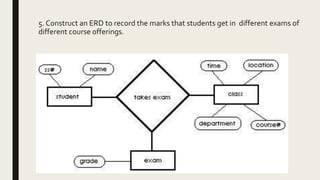

The document provides information on the key concepts of an entity-relationship (E-R) model, including: 1) Entities represent real-world objects like people, places, and things that are stored in a database. Attributes describe the properties of entities. 2) Relationships represent associations between entities. Relationships have properties like degree, cardinality, and existence. 3) Keys like primary keys and foreign keys uniquely identify entities and define relationships between entities. 4) Strong and weak entities differ in whether they have their own primary keys or rely on other entities. 5) E-R diagrams visually depict entities, attributes, relationships, keys and other concepts to model a database.






















































































