The document discusses advancements in voice conversion (VC) techniques, focusing on its definition, necessity, methodologies, and research progress. VC is a method for altering speech to convey desired characteristics while retaining the linguistic content. It highlights various models, comparisons of techniques, training improvements, and applications in real-time communication and character voice modulation.
![Advanced Voice Conversion
Nagoya University, Japan
tomoki@icts.nagoya‐u.ac.jp
July 26th, 2018
Tomoki TODA
0
20
40
60
80
100
1990 2000 2010 201520051995
[Abe; ’90]
[Stylianou; ’98]
[Toda; ’07]
Let’s also look at
recent progress!
Let’s quickly learn
VC research history!](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-1-320.jpg)
![Advanced Voice Conversion
Nagoya University, Japan
tomoki@icts.nagoya‐u.ac.jp
July 26th, 2018
Tomoki TODA
0
20
40
60
80
100
1990 2000 2010 201520051995
[Abe; ’90]
[Stylianou; ’98]
[Toda; ’07]
Let’s also look at
recent progress!
Let’s quickly learn
VC research history!](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/75/Advanced-Voice-Conversion-1-2048.jpg)


![Excitation generation
beyond constraints
Articulation
beyond constraints
Q1. Why VC Is Needed?
Excitation
generation
Articulation Speech
VC
Converted
speech
Hello…Hello…Hello…
Hello!
Normal speech organs
would be virtually implanted!
Even if some speech
organs were lost…
Possible to augment our speech production [Toda, ’14]
by intentionally control non‐linguistic information!
• Potential to break down barriers existing in speech communication!
What’s VC?: 2](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-5-320.jpg)
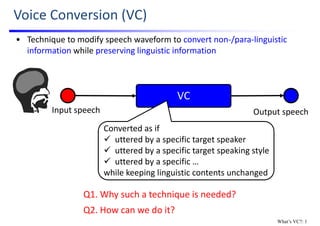
![Q2. How to Convert Speech?
Converted
speech
Input
speech
Conversion
Converted speech parameters
SynthesisAnalysis
Speech parameters
• Modify speech parameters w/ source‐filter model (i.e., vocoder)
Spectral parameter
Excitation
Pulse train
Gaussian noise
Synthetic speech
Synthesis filter
)(zH
][*][][ nenhnx
F0 & voiced/unvoiced
Speech parameters (extracted from speech signal )
][ne
What’s VC?: 3](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-6-320.jpg)
![Voice Conversion w/ Vocoder
Realtime speech modification
software (Herium)
[Prof. Banno, Meijyo Univ.]
Excitation parameters (e.g., fundamental frequency)
Shorter period
Longer period
Higher pitch!
Lower pitch!
Time
Time
Time
Extend
frequency
Shrink
frequency
Longer vocal tract!
Frequency
Power
Frequency
Power
Frequency
Power
Resonance parameters (e.g., spectral envelope)
Shorter vocal tract!
Input speech
parameters
Rule‐based conversion
(w/ time‐invariant function)
Converted speech
parameters
What’s VC?: 4](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-7-320.jpg)
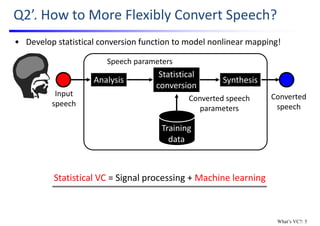
![• Described as a regression problem
• Supervised training using utterance pairs of source & target speech
Basic Framework of Statistical VC
Target speaker
Conversion model
Please say
the same thing.
Please say
the same thing.
Let’s convert
my voice.
Let’s convert
my voice.
Source speech Target speech
1. Training with parallel data (around 50 utterance pairs)
2. Conversion of any utterance while keeping linguistic contents unchanged
Source speaker
[Abe; ’90]
Example: speaker conversion
What’s VC?: 6](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-9-320.jpg)
![Demo: Character Voice Changer
• Convert my voice into specific characters’ voices
Realtime statistical VC software
[Dr. Kobayashi, Nagoya Univ.]
Famous virtual singer
Famous girl character
What’s VC?: 9](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-12-320.jpg)

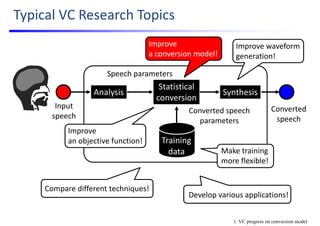
![1. Improve a Conversion Model
VQ [Abe; ’90]
Key ideas are
how to accurately model nonlinear regression!
how to model speech dynamics!
Frame‐based
discrete mapping
Trajectory conversion
w/ MLPG [Toda; ’07]
Sequence
mapping
GMM [Stylianou; ’98]
Soft clustering &
linear regression
DNN [Chen; ’14]
Deep generative
model
Unit selection [Jin; ’16]
NMF [Takashima; ’13][Wu; ’14]
GPR [Pilkington; ’11][Xu; ’14]
Exemplar / Sparsity
Bayesian formulation
Nonparametric
model
Parametric
model
Mixture model Product model
ANN [Narendranath; ’95][Desai; ’10]
Nonlinear model
RBM [Nakashika; ’14]
Distributed
representation
RNN [Sun; ’15]
Sequence mapping
CNN [Kaneko; ’17]
1. VC progress on conversion model: 1](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-18-320.jpg)
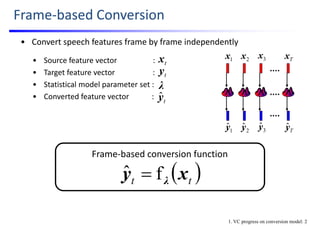
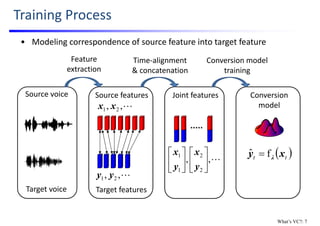
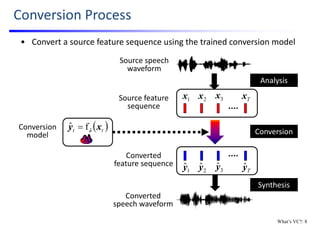
![Pioneer Work: VQ‐based Conversion
• Use Vector Quantization (VQ) to define a discrete conversion function
Source feature
sequence
1x
1
ˆy
2x
2
ˆy
Tx
Tyˆ
3x
3
ˆy
Source
codebook
Source speech
waveform
Converted
feature sequence
Converted
speech waveform
[Abe; ’90]
VQ index
sequence
𝑚 𝑚 𝑚 𝑚
Mapping
codebook
4.4
4.6
4.8
5
5.2
5.4
5.6
5.8
6
Original feature, x
4.6 4.8 5 5.2 5.4 5.6 5.8 6 6.2
Targetfeature,y
Codebook mapping
0.005
0.001
0.0001
Input feature
Target feature
Example of conversion function
1. VC progress on conversion model: 3
NOTE: only spectral parameter is
converted w/ VQ. On the other
hand, F0 is converted with time‐
invariant linear transformation
based on means & variances of
source & target F0s.](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-20-320.jpg)
![From Discontinuous to Continuous Conversion
[Stylianou; ’98]
VQ‐based conversion GMM‐based conversion
1. VC progress on conversion model: 4
• Model feature correlation more accurately
4.4
4.6
4.8
5
5.2
5.4
5.6
5.8
6
Original feature, x
4.6 4.8 5 5.2 5.4 5.6 5.8 6 6.2
Targetfeature,y
Codebook mapping
0.005
0.001
0.0001
Input feature
Target feature
4.4
4.6
4.8
5
5.2
5.4
5.6
5.8
6
Original feature, x
4.6 4.8 5 5.2 5.4 5.6 5.8 6 6.2Targetfeature,y
0.005
0.001
0.0001
Input featureTarget feature
Discrete function w/ hard
clustering
Ignore feature correlation w/
discrete mapping
Continuous function w/ soft
clustering
Directly model feature correlation
w/ linear regression](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-21-320.jpg)
![GMM‐based Conversion
M
m
yy
m
yx
m
xy
m
xx
m
y
m
x
m
t
t
m
1
)()(
)()(
)(
)(
,;
ΣΣ
ΣΣ
μ
μ
y
x
N λyx |, ttp
Parameter set
Joint feature
vector tx
ty
Mean
vector
Component weight
Covariance
matrix
m
)(x
mμ )(xx
mΣ
)( y
mμ )( yx
mΣ
)(xy
mΣ
)( yy
mΣ
M
m
xy
m
xy
tmtt
ttt
tt
tt mp
p
p
p
1
)|()|(
, ,;,|
d|,
|,
,| Σμyλx
yλyx
λyx
λxy N
Conversion w/ conditional p.d.f. (also modeled by a GMM)
Training of joint p.d.f. (modeled by a GMM) [Kain; ’98]
1. VC progress on conversion model: 5
[Stylianou; ’98]
M
m
xy
tmtttttt mpp
1
)|(
,,|d,|ˆ μλxyλxyyyMMSE estimate:](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-22-320.jpg)
![From Frame‐based to Sequence‐based Process
[Toda; ’07]
Source feature sequence
Converted feature sequence
Joint conversion
1x
1
ˆy
tt xy λfˆ
2x
2
ˆy
Tx
Tyˆ
3x
3
ˆy
1x
1
ˆy
2x
2
ˆy
Tx
Tyˆ
3x
3
ˆy
TT xxxyyy λ ,,,fˆ,,ˆ,ˆ 2121
Frame‐based conversion Sequence‐based conversion
Source feature sequence
Converted feature sequence
1. VC progress on conversion model: 6
• Conversion considering inter‐frame correlation over an utterance to
properly model speech dynamics](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-23-320.jpg)
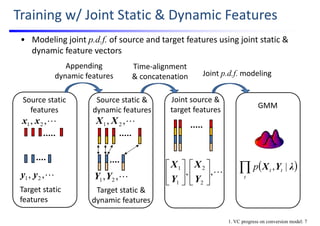
![ |(),|(,|maxargˆ,,ˆ )(
1
,,
1
1
y
tt
T
t
ttT PPP
T
vλXyλXyyy
yy
Source feature
sequence TXtX2X1X
Converted static
feature sequence Tyˆ1
ˆy 2
ˆy tyˆ
[Toda; ’07]
Conditional p.d.f.
for static features
Conditional p.d.f. for
dynamic features
(= linearly transformed)
Function of
static features
GMM
Converted
static features
• Simultaneously convert all frames over a time sequence (e.g., utterance)
1. VC progress on conversion model: 8
Conversion w/ MLPG(Maxim Likelihood Parameter Generation [Tokuda; ’00])](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-25-320.jpg)
![From Mixture Model to Product Model
• Use more powerful model to accurately represent nonlinear relationship
Joint p.d.f. modeling
based on GMM [Toda; ’07]
Joint p.d.f. modeling based on
RBM [Nakashika; ’14][Chen; ’14]
1. VC progress on conversion model: 9
Context info
e.g., phonemes
tYtX
Tt :1
tYtX
Tt :1
𝑧 , 𝑧 , 𝑧 ,
Mixture model
Latent variable 𝒛
one‐hot representation
Product model
Latent variable 𝒛
distributed representation
𝒛
# of mixture
components:
M Gaussians
vs
2 Gaussians](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-26-320.jpg)
![VC based on Deep Conversion Network
• Robustly train deep generative network using deep learning techniques
1. VC progress on conversion model: 10
[Chen; ’14]
Tt :1
𝑧 ,
Tt :1
tY
𝑧 , 𝑧 ,
𝑧 , 𝑧 , 𝑧 ,
1. Separately train RBMs for
source and target features
Source RBM
Target RBM
Tt :1
2. Train bidirectional
associative memory
(BAM) for using pairs of
inferred latent variables
𝑧̂ , 𝑧̂ ,
𝑧̂ , 𝑧̂ , 𝑧̂ ,
BAM
𝑧̂ ,
3. Build deep network
by combining them
𝑧 , 𝑧 , 𝑧 ,
𝑧 , 𝑧 , 𝑧 ,
tY
tY
Deep conversion network
tX
tX](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-27-320.jpg)
![Sequence‐based Conversion w/ RNN
• Use bidirectional LSTM to convert a source feature sequence into a target
feature sequence considering inter‐frame correlation over an utterance
1. VC progress on conversion model: 11
[Sun; ’15]
1x 2x Tx3xSource feature
sequence
Target feature
sequence
Forward LSTM
1st layer
Backward LSTM
1st layer
𝒉
𝒉
𝒉
𝒉
𝒚
𝒉
𝒉
𝒉
𝒉
𝒚
𝒉
𝒉
𝒉
𝒉
𝒚
𝒉
𝒉
𝒉
𝒉
𝒚
Forward LSTM
2nd layer
Backward LSTM
2nd layer](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-28-320.jpg)
![Sequence‐based Conversion w/ CNN
• Use gated CNN [van den Oord; ’16a] to model long‐term dependencies
• Training: fixed length of sequence (e.g., by cutting an utterance)
• Conversion: arbitrary length of sequence
1. VC progress on conversion model: 12
Sequence mapping
w/ deep gated CNN
1x 2x Tx3x
Source feature sequence
Target feature sequence
𝒚 𝒚 𝒚 𝒚
Gated convolution
𝑯 𝑯 ∗ 𝑾 𝒃 ⊗ 𝜎 𝑯 ∗ 𝑽 𝒄
⊗
𝜎
𝑯
𝑯 ∗ 𝑾 𝒃
𝑯 ∗ 𝑽 𝒄
𝑯
(𝑙 1)th layer 𝑙th layer
Channel
Time
Dimension
[Kaneko; ’17]](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-29-320.jpg)
![2. Improve an Objective Function
MMSE [Stylianou; ’98]
Key ideas are
how to keep or reproduce natural speech fluctuation!
how to handle errors of time alignment!
Divergence
‐based
Minimization of
regression error
Maximization of
likelihood
MLE [Toda; ’07]
GV [Toda; ’07]
Regularization w/ feature to
capture oversmoothing effects
MS [Takamichi; ’16]
More generalized features
Distance‐
based
GAN [Saito; ’18]
Data‐driven regularization
2. VC progress on objective function: 1
MLE w/ DP‐GMM
[Nankaku; ’07]
Hidden
alignment
Sequence
mapping GAN w/ Gated
CNN [Kaneko; ’17]
RobustSensitive
Misalignment](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-31-320.jpg)
![Global Variance (GV) Modeling
• Use GV of target speech parameters over an utterance as a feature to
capture oversmoothing effects
Gaussian
distribution
n
v
nP )()(
)( | λv y
p.d.f. modeling
T
t
T
ddtd y
T
y
T
v
1
2
1
,,
)( 11
y
0 1 2 3
Time [sec]
0
1
‐1
)( y
dv
dy
[Toda; ’07]
Target voices Target static
feature sequences
GV calculation
(nonlinear transformation)
)1()1(
1 1
,, Tyy
Feature extraction
)(
)1(
y
v
)(
)(
y
v N
)()(
1 ,, N
T
N
N
yy
GV vectors
2. VC progress on objective function: 2](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-32-320.jpg)
![• Use GV likelihood as a regularization term in conversion [Toda; ’07]
• Also possible to use it in training [Zen; ’12][Hwang; ’13]
• Simpler way: design postfilter to enhance GV [Toda; ’12b]
Regularization w/ GV
GV p.d.f.
)|(),|(,|maxargˆ,,ˆ )()(
1
,,
1
1
vy
tt
T
t
ttT PPP
T
λvλXyλXyyy
yy
Conditional p.d.f.
for static features
p.d.f. of GV
(= nonlinearly
transformed)
Conditional p.d.f. for
dynamic features
(= linearly transformed)
Function of
static features
GMM
Converted
static features
2. VC progress on objective function: 3
tyˆ )GV(
ˆtyPostfilter (simple linear
transformation w/ mean & var)
Converted feature w/o GV
Too small GV… GV close to natural one!
Enhanced feature](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-33-320.jpg)
![Modulation frequency
components
0 Hz
0.25 Hz
0.5 Hz
~ Hz
=
……
From GV to Modulation Spectrum
0 1 2 3
0
1
‐1
)( y
dv
dy
Decompose a parameter
sequence into individual
modulation frequency
components
Time [sec]
)(
1,
y
dv
)(
2,
y
dv
)(
,
y
fdv
)(
0,
y
dv
p.d.f. modeling of their
power values (i.e., their GVs)
Parameter
sequence
Incorporate them into
the objective function
[Takamichi; ’15] or design
postfilter [Takamichi; ’16]
[Takamichi; ’16]
2. VC progress on objective function: 4](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-34-320.jpg)
![Regularization w/ GAN [Goodfellow; ’14]
• Design a regularization term in a totally data‐driven manner instead of
using hand‐crafted features (GV and MS)
2. VC progress on objective function: 5
[Saito; ’18]
Conversion
network
𝒚
Discriminator
network
0: Converted
1: Natural target
1x 2x Tx3x
1
ˆy 2
ˆy Tyˆ3
ˆy
𝒚 𝒚 𝒚
Source
features
Target
features
Converted
features
Conversion error
𝐿 𝒚, 𝒚
Adversarial loss 𝐿 𝒚 ∝ 𝑝 0|𝒚
Trained by minimizing
𝐿 𝒚, 𝒚 𝜔 𝐿 𝒚
Trained by maximizing
1 𝐿 𝒚 𝐿 𝒚
∝ 𝑝 1|𝒚 𝑝 0|𝒚](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-35-320.jpg)
![Sequence‐based Conversion w/ GAN
• Combine the sequence‐based process (e.g., gated CNN) and GAN to
alleviate adverse effects of misalignment
2. VC progress on objective function: 6
[Kaneko; ’17]
Sequence mapping
w/ deep gated CNN
1x 2x Tx3xSource
feature
sequence
Converted
feature
sequence 𝒚 𝒚 𝒚 𝒚
𝒚 𝒚 𝒚 𝒚
Discriminator w/
deep gated CNN
Target
feature
sequence
𝑯
𝑯
0: Converted or
generated
1: Natural target
Trained by minimizing
𝐿 𝒚 𝐿 𝑯, 𝑯
Trained by maximizing
𝐿 𝒚 𝐿 𝒚 𝐿 𝒚
Trained by minimizing 𝐿 𝒚
Noise Generator
𝒚 𝒚 𝒚 𝒚
𝑯](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-36-320.jpg)
![3. Improve Waveform Generation
HNM [Stylianou, ’96]
STRAIGHT [Kawahara; ’99]
AHOCODER [Erro; ’14]
WORLD [Morise; ’16]
Key ideas are
how to leverage source waveform!
how to avoid assumptions in source‐filter model!
High‐quality vocoder
PSOLA [Valbret; ’92]
Waveform modification
Direct waveform
filtering [Kobayashi; ’18a]
Time‐variant log‐spectral
differential filter estimation
Mixed excitation
[Ohtani; ’06]
Phase modeling
[Kain; ’01][Ye; ’06]
Residual selection
[Suendermann; ’05a]
Excitation
modeling
Excitation pulse
generation
[Juvela; ’18]
GAN
WaveNet vocoder
[Kobayashi; ’17]Neural vocoder
Leverage source waveform
Directly improve vocoder
3. VC progress on waveform generation: 1](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-38-320.jpg)
![Input speech
waveform
Time-variant filter Converted speech
waveform
Direct Waveform Modification
• Apply time‐variant filtering to input speech waveform to convert its
spectral envelope only
[Kobayashi; ’18a]
)(ˆ )/(
zH xy
t
][*][*][ˆ
][*][ˆ][ˆ
)(1)()(
)()/()(
nsnhnh
nsnhns
xx
t
y
t
xxy
t
y
][)(
ns x
)(
)(ˆ
)(ˆ
)(
)(
)/(
zH
zH
zH x
t
y
txy
t
3. VC progress on waveform generation: 2
• Keep natural phase components!
• Alleviate the over‐smoothing effects!
• But hard to convert excitation parameters (e.g., F0)
Tddd ˆ,,ˆ,ˆ
21
Sequence of log‐spectral differentials
(e.g., mel‐cepstrum differentials )
Converted
parameters =
λyx |, ttp
GMM
ttt xyd
λdx |, ttp
DIFFGMM
Variable transformation](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-39-320.jpg)
![Excitation Modeling
• Hard to generate natural excitation waveforms by using traditional
excitation models of source filter!
• Two important components need to be modeled…
• Stochastic component
Parameterized as frequency‐dependent aperiodicicy and statistically
converted in a mixed‐excitation framework [Ohtani; ’06]
• Phase component
Modeled with templates [Kain; ’01] or waveform reshaping filter [Ye; ’06]
Develop one pitch residual waveform dataset and select the best one using
other speech parameters (e.g., F0 & spectral parameter) [Suendermann; ’05a]
3. VC progress on waveform generation: 3
Excitation
Pulse train
Gaussian noise
Synthetic speech
Synthesis filter
)(zH
][*][][ nenhnx
][ne](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-40-320.jpg)
![GAN for Excitation Generation
• Generate one‐pitch glottal pulse waveform by using DNN‐based
regression [Juvela; ’16] and GAN
3. VC progress on waveform generation: 4
PSOLA
Excitation
signal
Noise
Generator
network
Glottal pulse
waveform
⨁
F0 DNN
Glottal pulse
waveform
Good phase
components
Spectral parameter
Good phase &
stochastic components
Magnitude
spectrum
Discriminator
network
0: Generated
1: Natural target
Target glottal
pulse waveform
[Juvela; ’18]](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-41-320.jpg)
![VC w/ WaveNet [van den Oord; ’16b]
• Implementation of WaveNet vocoder for VC
• Target speaker‐dependent WaveNet vocoder [Tamamori; ’17] can generate
speech waveform almost indistinguishable from natural one [Hayashi; ’17]!
• Use target speaker‐dependent WaveNet vocoder to generate speech
waveform from converted speech parameters [Kobayashi; ’17]
Can significantly improve conversion accuracy on speaker identity!
Could also reduce adverse effects of some errors on converted speech
e.g., by training WaveNet vocoder w/ the converted speech parameters.
• Possible to directly use WaveNet for VC [Niwa; ’18]
Input
speech
Statistical
conversion
Converted speech
parameters
Analysis
Speech
parameters
Feature
extraction error
Conversion error Converted
speech
Synthesis w/
WaveNet
vocoder
Less affected by errors
3. VC progress on waveform generation: 5](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-42-320.jpg)
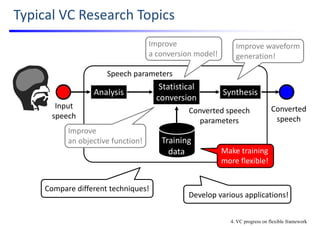
![4. Make Training More Flexible
Frame selection
[Suendermann; ’06]
Key ideas are
how to generate parallel data from nonparallel data!
how to factorize speech to speaker identity & others!
Factorization
MAP [Lee; ’06]
Linear regression
[Mouchtaris; ’06]
EVC
Use multiple speaker‐pairs
HMM state
alignment [Ye; ’06]
w/o text CycleGAN
[Kaneko; ’18][Fang; ’18]
Data generation
Parallel data
generation
[Toda; ’06]
Many‐to‐many
EVC [Ohtani; ’09]
Arbitrary
speaker pairs
VAW‐GAN
[Hsu; ’17]
GAN
PPG [Sun; ’16]
Speaker‐independent feature
VQ‐VAE
WaveNet
[van den Oord; ’17]
Model adaptation
Nonparallel training
Nonparallel
data
ARBM [Nakashika; ’16]
CVAE [Hsu; ’16]
4. VC progress on flexible framework: 1](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-44-320.jpg)
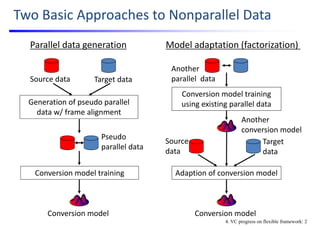
![Nonparallel Training w/ CycleGAN[Zhu; ’17]
• Simultaneously train two networks between two speakers.
4. VC progress on flexible framework: 3
Target
data 𝒚
Source
data 𝒙
Conversion
network
from 𝒙 to 𝒚
Conversion
network
from 𝒚 to 𝒙
Converted
data 𝒙 ⇒ 𝒚
Converted data
𝒙 ⇒ 𝒚 ⇒ 𝒙
Converted
data 𝒚 ⇒ 𝒙
Converted data
𝒚 ⇒ 𝒙 ⇒ 𝒚
Cycle loss
𝐿 𝒙, 𝒙
Cycle loss
𝐿 𝒚, 𝒚
Adversarial loss
𝐿 𝒙
Adversarial loss
𝐿 𝒚
Trained by
minimizing
𝐿 𝒙 𝐿 𝒚
𝐿 𝒙, 𝒙
𝐿 𝒚, 𝒚
Discriminator
network for 𝒙
0: Converted, 1: Natural
Discriminator
network for 𝒚
0: Converted, 1: Natural
[Fang; ’18][Kaneko; ’18]](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-46-320.jpg)
![One‐to‐Many (or Many‐to‐One) VC
[Toda; ’06]
• Convert reference speaker’s voice into arbitrary speaker’s voice
tX )(s
tY
sTt :1
tz
)(s
w
Ss :1
Speaker
info
Context
info
Model frame‐dependent contextual
factor and utterance‐dependent speaker
factor w/ different latent variables
Factorize speaker and context using the reference speaker as an anchor point!
)1(
:1 1TY
tX )2(
:1 2TY
)(
:1
S
TS
Y
Reference
speaker
Prestored speakers
1st speaker
2nd speaker
Sth speaker
Use multiple parallel datasets
between the reference speaker &
individuals of prestored speakers
Training datasets Model training
4. VC progress on flexible framework: 4](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-47-320.jpg)
![Eigenvoice Conversion (EVC)
Super vectors
= concatenated means
(context & speaker
dependent)
)(
)(
2
)(
1
)1(
)1(
2
)1(
1
,,
J
M
J
J
M b
b
b
b
b
b
)(
)(
1
s
J
s
w
w
)0(
)0(
2
)0(
1
Mb
b
b
Bias vector
= average speaker
(context dependent)
+
Factors
(speaker
dependent)
×
Basis vectors
= typical speaker
variations
(context dependent)
=
Used as speaker‐adaptive parameters
)(
)(
2
)(
1
s
M
s
s
μ
μ
μ
= +
• Factorize GMM mean vectors into context‐ and speaker‐dependent
components using Eigenvoice technique [Kuhn; ’00]
[Toda; ’06]
4. VC progress on flexible framework: 5](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-48-320.jpg)
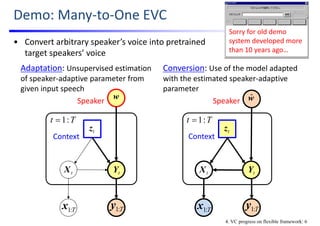
![Many‐to‐Many EVC
[Ohtani; ’09]
• Conversion between an arbitrary speaker pair
• Sequential conversion of many‐to‐one
and one‐to‐many EVC tX
)(o
tY)(i
tY
tX )(o
tY
Tt :1
tz )(o
w
Speaker
Context
)(i
tY
)(i
w
Speaker
tX )(s
tY
Tt :1
tz )(s
w
Speaker
Context
Conversion model transformation
One‐to‐many
conversion model
Many‐to‐many
conversion model
Concatenate one‐to‐many and
many‐to‐one models
Marginalize out reference features
to derive a many‐to‐many model
4. VC progress on flexible framework: 7
Speaker normalization](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-50-320.jpg)
![Speaker‐Independent Feature Extraction
• Extract phoneme posteriorgram (PPG) as speaker‐independent contextual
features and use them as input of the conversion network
4. VC progress on flexible framework: 8
Phone recognizer
1x 2x Tx3xSource feature
sequence
Target feature
sequence
𝒚 𝒚 𝒚 𝒚
𝒑 𝒑 𝒑 𝒑
PPG
Target‐dependent
conversion network
No longer need to use
parallel data!
Target
speech data
PPG data
Phone
recognizer
Conversion
network
Remove speaker‐
dependencies!
Add speaker‐
dependencies!
[Sun; ’16]](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-51-320.jpg)
![Encoder
network
tz
Decoder
network
Target
speaker
Context
tX
𝑡 1: 𝑇
Gaussian
prior 𝑁 𝟎, 𝑰
Conversion step
Unsupervised Factorization
• Use multiple nonparallel datasets to develop a factorized conversion
model (e.g. CVAE [Hsu; ’16] or ARBM [Nakashika; ’16]) without any other models
4. VC progress on flexible framework: 9
)(s
tY
Speaker
Context
Decoder
network
Encoder
network
𝑡 1: 𝑇
𝑠 1: 𝑆
Gaussian
prior 𝑁 𝟎, 𝑰
Conditional Variational Autoencoder (CVAE)
Training step
Remove speaker
dependencies
Speaker‐independent
encoder network is trained!
Speaker‐adaptive
decoder is trained!
GAN can be used in
VAW‐GAN [Hsu; ’17].
Add speaker
dependencies
tz
)(s
w
)(s
w
)(s
tY](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-52-320.jpg)
![VQ‐VAE
• Directly encode speech waveform into a discrete symbol sequence
capturing long‐term dependencies (including prosodic features!) by using
a dilated convolution network
• Generate speech waveform from it by using WaveNet as decoder
• Factorize speech waveform into speaker‐dependent components (modeled
by speaker code) and context‐dependent components (modeled by discrete
symbol sequence) using multiple nonparallel datasets
[van den Oord; ’17]
Speech waveform
Latent feature sequence
Vector
quantization
Discrete symbol
sequence
Generated speech
waveform
Encoder Decoder
Embedding
vectors
Speaker
code
Well corresponds to
linguistic information!
4. VC progress on flexible framework: 10](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-53-320.jpg)
![VC based on VQ‐VAE
• Easily perform VC by giving target speaker’s speaker code
Source speech
waveform
Converted
speech waveform
[van den Oord; ’17]
Discrete symbol
sequence
𝑚 𝑚 𝑚 𝑚
Encoder (non‐causal
dilated convolution)
Decoder
(WaveNet)
Target speaker’s
speaker code
Not only segmental
features but also prosodic
features are converted!
4. VC progress on flexible framework: 11
Embedding
vectors
Only contextual
information is modeled.
Converted voice samples are available from https://avdnoord.github.io/homepage/vqvae/](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-54-320.jpg)
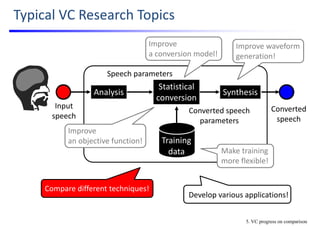
![5. Compare Different Techniques
Key ideas are
comparison using a common dataset!
provide a freely available resources for VC research!
Evaluation using
Individual datasets
Evaluation using
common datasets
TC‐STAR [Suendermann; ’05b]
Freely available resources
for standard VC framework
VCC2016 [Toda; ’16]
VCC2018 [Lorenzo‐Trueba; ’18]
Non parallel training & spoofing
5. VC progress on comparison: 1](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-56-320.jpg)
![Voice Conversion Challenge 2016 (VCC2016)
• Motivation: better understand different VC techniques by comparing their
performance using a freely‐available dataset as a common dataset
• Following a policy of Blizzard Challenge [Black; ’05]
“Evaluation campaign” rather than “competition”
• Task: parallel training
• Evaluation: naturalness and speaker similarity by listening tests
• Design of VCC 2016 dataset (using DAPS [Mysore, ’15] )
• Manually segmented into 216 sentences in each speaker
• Down‐sampled to 16 kHz
# of speakers # of sentences
Source
speakers
3 females & 2 males 162 for training & 54 for evaluation
Target
speakers
2 females & 3 males 162 for training
[Toda; ’16]
5. VC progress on comparison: 2](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-57-320.jpg)
![Overall Result of VCC2016 Listening Tests
1 2 3 4 5
0
20
40
60
80
100
Mean opinion score (MOS) on naturalness
Correct rate [%] on speaker similarity
Target
Source
Baseline A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
Better
Better
P
Q
Correct = 75%
MOS = 3.5
• 22 submitted systems + 1 baseline system were evaluated.
5. VC progress on comparison: 3](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-58-320.jpg)
![J System: NU‐NAIST System
• Use direct waveform modification based on
log‐spectral differential
Converted
speech
Input
speech
Directed
waveform
modification
Conversion w/
MLPG & GV
Analysis
Spectral
sequence
Log‐spectral
differential
sequence
Excitation
conversion
GMM for spectrum
F0 mean & var
GMM for BAP
Vocoded waveform
Still need to use vocoder (e.g., STRAIGHT) to convert F0…
[Kobayashi; ’16]
To tell the truth…
our internal listening test showed NU‐NAIST system was comparable to our previous system
(= the VCC 2016 baseline system + STRAIGHT) developed in 2005… It disappointed us, but it
motivated us to develop a freely available baseline system based on our previous system.
5. VC progress on comparison: 4](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-59-320.jpg)
![Voice Conversion Challenge 2018 (VCC2018)
• Two tasks
• HUB task (main): Parallel training
• SPOKE task (optional): Nonparallel training
• Evaluation
• Naturalness and speaker similarity by listening tests
• Word error rate and spoofing results
• Design of VCC 2018 dataset (using DAPS [Mysore, ’15] )
• Down‐sampled to 22.05 kHz
# of speakers # of sentences
Source
speakers
2 females & 2 males 81 for training
& 35 for evaluation
Target
speakers
2 females & 2 males 81 for training
Other source
speakers
2 females & 2 males Other 81 for training
& 35 for evaluation
HUB tskSPOKE task
5. VC progress on comparison: 5
[Lorenzo‐Trueba; ’18]](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-60-320.jpg)
![Overall Results of VCC2018 Listening Tests
100
80
60
40
20
0
1 2 3 4 5
MOS on naturalness
Similarity score [%]
100
80
60
40
20
0
1 2 3 4 5
MOS on naturalness
Similarity score [%]
Results of Hub task Results of Spoke task
Baseline
system
N17 system
N10 system
Baseline
system
N17 system
N10 system
• 23 submitted systems + 1 baseline
system were evaluated in HUB task.
• 11 submitted systems + 1 baseline
system were evaluated in SPOKE task.
5. VC progress on comparison: 6](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-61-320.jpg)
![N10 System
• No need to use parallel data by using speaker‐
independent features as input of conversion
Converted
speech
Input
speech
Synthesis w/
WaveNet
Conversion
w/ LSTM
Speaker‐independent
bottleneck features
Target speech
parameters
Analysis w/
ASR
[Liu; ’18]
Speaker‐
independent
phone recognizer
Speaker‐
dependent
LSTM
Speaker‐
dependent
WaveNet
VCC2018
dataset
Hundreds of hours
of external data
80 hours of
external data
5. VC progress on comparison: 7](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-62-320.jpg)
![N17 System
• Still need to use a parallel dataset
• Use TTS to generate parallel data for SPOKE task
Converted
speech
Input
speech
Synthesis w/
WaveNet
Conversion w/
MLPG&GV
Source speech
parameters
Target speech
parameters
Analysis w/
vocoder
[Tobing; ’18]
WORLD
[Morise; ’16]
Speaker‐pair
dependent MDN
F0 mean & var
Speaker‐
dependent
WaveNet
VCC2018
dataset
2 hours of
external data
5. VC progress on comparison: 8](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-63-320.jpg)
![Baseline System: sprocket
• Still need to use a parallel dataset
• Use different source speakers for SPOKE task
Converted
speech
for same‐
gender VC
Input
speech
Synthesis w/
waveform filtering
Conversion w/
MLPG & GV
Source speech parameters
Differential filter
parametersAnalysis w/
vocoder
[Kobayashi; ’18b]
WORLD
[Morise; ’16]
Speaker‐pair
dependent GMM
F0 mean & var
VCC2018
dataset
Synthesis w/
vocoder
Target speech
parameters
Converted
speech
for cross‐
gender VC
5. VC progress on comparison: 9](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-64-320.jpg)
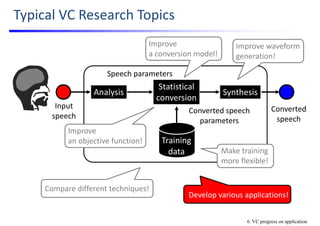
![6. Develop Various Applications
Cross‐lingual VC
[Abe; ’91]
Key ideas are
how to apply VC techniques to various mapping tasks!
development of real‐time VC (RT‐VC) applications!
Tellecommunication
Bandwidth
extension [Jax; ’03]
Speaking‐aid
Intelligibility
enhancement of
disordered speech
[Kain; ’07][Aihara; ’14]
Inversion & production
mapping [Richmond; ’03]
[Toda; ’08]
Articulatory
controllable
waveform
modification
[Tobing; ’17]
Singing VC
[Villavicencio; ’10]
[Doi; ’12]
Speech translation
[Hattori; ’11]
Entertainment
Articulatory modification
TTS
Silent speech
communication [Toda; ’12a]
Voice changer &
vocal effector [Kobayashi; ’14]
Alaryngeal speech
enhancement
[Nakamura; ’12][Doi; ’14]
Augmented speech production
[Toda, ’14]
F0‐controlled
electrolarynx [Tanaka; ’17]
RT‐VC
RT‐VC
RT‐VC
6. VC progress on application: 1
* NOTE: More applications have been studied
Accent
conversion
[Felps; ’09]](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-66-320.jpg)
![Real‐Time Statistical Voice Conversion
Source feature sequence
Converted feature sequence
Batch‐type conversion
Lttt xxxy λ ,,,,fˆ 1
1tx
1
ˆ ty
tx
tyˆ
1x
1
ˆy
2x
2
ˆy
Tx
Tyˆ
3x
3
ˆy
TT xxxyyy λ ,,,fˆ,,ˆ,ˆ 2121
Low‐delay frame‐wise
conversion
Sequence‐based conversion
Source feature sequence
Converted feature sequence
1tx2tx3tx
1
ˆ ty1
ˆ ty
• Approximate sequence‐based conversion with low‐delay conversion by
propagating all past info and also looking at near future info
2tx
6. VC progress on application: 2
[Toda; ’12b]](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-67-320.jpg)
![1. Speaking‐Aid: Alaryngeal Speech Enhancement
• Real‐time conversion from alaryngeal speech into normal speech
ES
l
spg.data
Time [s]
Frequency[Hz]
1 1.5 2 2.5 3
0
1000
2000
3000
4000
5000
6000
7000
8000
ESl
spg.data
Time [s]
Frequency[Hz]
1 1.5 2 2.5 3
0
1000
2000
3000
4000
5000
6000
7000
8000
Esophageal speech Enhanced speech
Waveform
F0 pattern
Aperiodicity
Spectral
envelope
Time Time
VC
Laryngectomee Spectrum
Aperiodicity
F0
Spectral
segment
[Doi; ’14]
6. VC progress on application: 3
Augmented speech production beyond physical constraints!](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-68-320.jpg)
![2. Silent Speech Communication
[Toda; ’12a]
6. VC progress on application: 4
Speaking side
・・・
Speak something private in
non‐audible murmur
or soft voice
Present more naturally sounding
speech to only a specific listener
My account
number is …
Listening side
VC
• Real‐time conversion from non‐audible murmur (very soft whispered voice)
[Nakajima; ’06] detected w/ body‐conductive microphone to natural voices
Augmented speech production to develop telepathy‐like communication!
Non‐audible
murmur
microphone
Converted to air‐conducted voices
from non‐audible murmur
Normal voice ( )
Whispered voice ( )
from body‐conducted soft voice
Soft voice ( )](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-69-320.jpg)
![• Statistically model a change of voice timbre caused by a change of
perceived age using multiple singers’ singing voices
• Develop statistical singing voice conversion model capable of
manually controlling perceived age while preserving singer identity
3. Vocal Effector: Perceived Age Control of Singing Voice
[Kobayashi; ’14]
Statistical VC
Original ageYounger Elder
Singer
Statistical VC
15 years old 50 years old35 years old
Develop a speaker‐independent sub‐space spanned by perceived age
on the model parameter space
6. VC progress on application: 5
Augmented speech production to create new singing expressions!](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-70-320.jpg)

![NOTE: Risk of VC
• Need to look at a possibility that statistical VC is misused for spoofing…
• Real‐time VC makes it possible for someone to speak with your voices…
• Shall we stop VC research?
No. There are many useful applications making our society better!
• What can we do?
• Collaborate with anti‐spoofing research [Wu; ’15]
• ASVspoof (automatic speaker verification spoofing and countermeasures
challenge) has been held since 2015. [Wu; ’17][Kinnunen; ’17]
• Need to widely tell people how to use statistical VC correctly!
Summary: 1
VC needs to be socially recognized as a kitchen knife.](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-72-320.jpg)

![[Abe; ’90] M. Abe, S. Nakamura, K. Shikano, H. Kuwabara. Voice conversion through vector quantization. J.
Acoust. Soc. Jpn (E), Vol. 11, No. 2, pp. 71–76, 1990.
[Abe; ’91] M. Abe, K. Shikano, H. Kuwabara. Statistical analysis of bilingual speaker's speech for cross‐
language voice conversion. J. Aoust. Soc. Am., Vol. 90, No. 1, pp. 76–82, 1991.
[Aihara; ’14] R. Aihara, R. Takashima, T. Takiguchi, Y. Ariki. A preliminary demonstration of exemplar‐based
voice conversion for articulation disorders using an individuality‐preserving dictionary. EURASIP J. Audio,
Speech & Music Process., Vol. 2014, No. 1, Article 5, 10 pages, 2014.
[Black; ’05] A.W. Black, K. Tokuda. The Blizzard Challenge – 2005: evaluating corpus‐based speech synthesis
on common datasets. Proc. INTERSPEECH, pp. 77–80, 2005.
[Chen; ’14] L.‐H. Chen, Z.‐H. Ling, L.‐J. Liu, L.‐R. Dai. Voice conversion using deep neural networks with
layer‐wise generative training. IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 22, No. 12, pp. 1859–
1872, 2014.
[Desai; ’10] S. Desai, A.W. Black, B. Yegnanarayana, K. Prahallad. Spectral mapping using artificial neural
networks for voice conversion. IEEE Trans. Audio, Speech & Lang. Process. Vol. 18, No. 5, pp. 954–964,
2010.
[Doi; ’12] H. Doi, T. Toda, T. Nakano, M. Goto, S. Nakamura. Singing voice conversion method based on
many‐to‐many eigenvoice conversion and training data generation using a singing‐to‐singing synthesis
system. Proc. APSIPA ASC, 6 pages, 2012.
[Doi; ’14] H. Doi, T. Toda, H. Saruwatari, K. Shikano. Alaryngeal speech enhancement based on one‐to‐
many eigenvoice conversion. IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 22, No. 1, pp. 172–183,
2014.
References
References: 1](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-74-320.jpg)
![[Erro; ’14] D. Erro, I. Sainz, E. Navas, I. Hernaez. Harmonics plus noise model based vocoder for statistical
parametric speech synthesis. IEEE J. Sel. Topics in Signal Process., Vol. 8, No. 2, pp. 184–194, 2014.
[Fang; ’18] F. Fang, J. Yamagishi, I. Echizen, J. Lorenzo‐Trueba. High‐quality nonparallel voice conversion
based on cycle‐consistent adversarial network. Proc. IEEE ICASSP, pp. 5279–5283, 2018.
[Felps; ’09] D. Felps, H. Bortfeld, R. Gutierrez‐Osuna. Foreign accent conversion in computer assisted
pronunciation training. Speech Commun., Vol. 51, No. 10, pp. 920–932, 2009.
[Goodfellow; ’14] I. Goodfellow, J. Pouget‐Abadie, M. Mirza, B. Xu, D. Warde‐Farley, S. Ozair, A. Courville, Y.
Bengio. Generative adversarial nets. Proc. NIPS, pp. 2672–2680, 2014.
[Hattori; ’11] N. Hattori, T. Toda, Hisashi Kawai, H. Saruwatari, K. Shikano. Speaker‐adaptive speech
synthesis based on eigenvoice conversion and language‐dependent prosodic conversion in speech‐to‐
speech translation. Proc. INTERSPEECH, pp. 2769–2772, 2011.
[Hayashi; ’17] T. Hayashi, A. Tamamori, K. Kobayashi, K. Takeda, T. Toda. An investigation of multi‐speaker
training for WaveNet vocoder. Proc. IEEE ASRU, pp. 712–718, 2017.
[Hsu; ’16] C.‐C. Hsu, H.‐T. Hwang, Y.‐C. Wu, Y. Tsao, H.‐M. Wang. Voice conversion from non‐parallel corpora
using variational auto‐encoder. Proc. APSIPA ASC, 6 pages, 2016.
[Hsu; ’17] C.‐C. Hsu, H.‐T. Hwang, Y.‐C. Wu, Y. Tsao, H.‐M. Wang. Voice conversion from unaligned corpora
using variational autoencoding Wasserstein generative adversarial networks. Proc. INTERSPEECH, pp.
3364–3368, 2017.
[Hwang; ’13] H. Hwang, Y. Tsao, H. Wang, Y. Wang, S. Chen. Incorporating global variance in the training
phase of GMM‐based voice conversion. Proc. APSIPA ASC, 6 pages, 2013.
[Jax; ’03] P. Jax, P. Vary. On artificial bandwidth extension of telephone speech. Signal Processing, Vol. 83,
pp. 1707–1719, 2003.
[Jin; ’16] Z. Jin, A. Finkelstein, S. DiVerdi, J. Lu, G.J. Mysore. CUTE: a concatenative method for voice
conversion using exemplar‐based unit selection. Proc. IEEE ICASSP, pp. 5660–5664, 2016.
References: 2](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-75-320.jpg)
![[Juvela; ’16] L. Juvela, B. Bollepalli, M. Airaksinen, P. Alku. High‐pitched excitation generation for glottal
vocoding in statistical parametric speech synthesis using a deep neural network. Proc. IEEE ICASSP, pp.
5120–5124, 2016.
[Juvela; ’18] L. Juvela, B. Bollepalli, X. Wang, H. Kameoka, M. Airaksinen, J. Yamagishi, P. Alku. Speech
waveform synthesis from MFCC sequences with generative adversarial networks. Proc. IEEE ICASSP, pp.
5679–5683, 2018.
[Kain; ’98] A. Kain and M. W. Macon. Spectral voice conversion for text‐to‐speech synthesis. Proc. IEEE
ICASSP, pp. 285–288, 1998.
[Kain; ’01] A. Kain, M.W. Macon. Design and evaluation of a voice conversion algorithm based on spectral
envelope mapping and residual prediction. Proc. IEEE ICASSP, pp. 813–816, 2001.
[Kain; ’07] A.B. Kain, J.P. Hosom, X. Niu, J.P.H, van Santen, M. Fried‐Oken, J. Staehely. Improving the
intelligibility of dysarthric speech. Speech Commun. Vol. 49, No. 9, pp. 743–759, 2007.
[Kaneko; ’17] T. Kaneko, H. Kameoka, K. Hiramatsu, K. Kashino. Sequence‐to‐sequence voice conversion
with similarity metric learned using generative adversarial networks. Proc. INTERSPEECH, pp. 1283–1287,
2017.
[Kaneko; ’18] T. Kaneko, H. Kameoka. Parallel‐data‐free voice conversion using cycle‐consistent adversarial
networks. Proc. EUSIPCO, 5 pages, 2018 (to appear).
[Kawahara; ’99] H. Kawahara, I. Masuda‐Katsuse, A. de Cheveigne. Restructuring speech representations
using a pitch‐adaptive time‐frequency smoothing and an instantaneous‐frequency‐based F0 extraction:
possible role of a repetitive structure in sounds. Speech Commun., Vol. 27, No. 3–4, pp. 187–207, 1999.
[Kinnunen; ’17] T. Kinnunen, M. Sahidullah, H. Delgado, M. Todisco, N. Evans, J. Yamagishi, K.A. Lee. The
ASVspoof 2017 Challenge: assessing the limits of replay spoofing attack detection. Proc. INTERSPEECH, pp.
2‐‐6, 2017.
References: 3](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-76-320.jpg)
![[Kobayashi; ’14] K. Kobayashi, T. Toda, H. Doi, T. Nakano, M. Goto, G. Neubig, S. Sakti, S. Nakamura. Voice
timbre control based on perceived age in singing voice conversion. IEICE Trans. Inf. & Syst., Vol. E97‐D, No.
6, pp. 1419–1428, 2014.
[Kobayashi; ’16] K. Kobayashi, S. Takamichi, S. Nakamura, T. Toda. The NU‐NAIST voice conversion system
for the Voice Conversion Challenge 2016. Proc. INTERSPEECH, pp. 1667–1671, 2016.
[Kobayashi; ’17] K. Kobayashi, T. Hayashi, A. Tamamori, T. Toda. Statistical voice conversion with WaveNet‐
based waveform generation. Proc. INTERSPEECH, pp. 1138–1142, 2017.
[Kobayashi; ’18a] K. Kobayashi, T. Toda, S. Nakamura. Intra‐gender statistical singing voice conversion with
direct waveform modification using log‐spectral differential. Speech Commun., Vol. 99, pp. 211–220, 2018.
[Kobayashi; ’18b] K. Kobayashi, T. Toda. sprocket: open‐source voice conversion software. Proc. Odyssey,
pp. 203–210, 2018.
[Kuhn; ’00] R. Kuhn, J. Junqua, P. Nguyen, N. Niedzielski. Rapid speaker adaptation in eigenvoice space.
IEEE Trans. Speech & Audio Process., Vol. 8, No. 6, pp. 695–707, 2000.
[Lee; ’06] C.‐H. Lee, C.‐H. Wu. MAP‐based adaptation for speech conversion using adaptation data
selection and non‐parallel training. Proc. INTERSPEECH, pp. 2446–2449, 2006.
[Liu; ’18] L.‐J. Liu, Z.‐H. Ling, Y. Jiang, M. Zhou, L.‐R. Dai. WaveNet Vocoder with Limited Training Data for
Voice Conversion. Proc. INTERSPEECH, 5 pages, 2018 (to appear).
[Lorenzo‐Trueba; ’18] J. Lorenzo‐Trueba, J. Yamagishi, T. Toda, D. Saito, F. Villavicencio, T. Kinnunen, Z. Ling.
The voice conversion challenge 2018: promoting development of parallel and nonparallel methods. Proc.
Odyssey, pp. 195–202, 2018.
[Morise; ’16] M. Morise, F. Yokomori, K. Ozawa. WORLD: a vocoder‐based high‐quality speech synthesis
system for real‐time applications. IEICE Trans. Inf. & Syst., Vol. E99‐D, No. 7, pp. 1877–1884, 2016.
[Mouchtaris; ’06] A. Mouchtaris, J.V. der Spiegel, P. Mueller. Nonparallel training for voice conversion based
on a parameter adaptation approach. IEEE Trans. Audio, Speech & Lang. Process., Vol. 14, No. 3, pp. 952–
963, 2006.
References: 4](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-77-320.jpg)
![[Mysore, ’15] G. J. Mysore. Can we automatically transform speech recorded on common consumer
devices in real‐world environments into professional production quality speech? – a dataset, insights, and
challenges. IEEE Signal Process. Letters, Vol. 22, No. 8, pp. 1006–1010, 2015.
[Nakajima; ’06] Y. Nakajima, H. Kashioka, N. Cambell, K. Shikano. Non‐Audible Murmur (NAM) recognition.
IEICE Trans. Inf. & Syst., Vol. E89‐D, No. 1, pp. 1–8, 2006.
[Nakamura; ’12] K. Nakamura, T. Toda, H. Saruwatari, K. Shikano. Speaking‐aid systems using GMM‐based
voice conversion for electrolaryngeal speech. Speech Commun., Vol. 54, No. 1, pp. 134–146, 2012.
[Nakashika; ’14] T. Nakashika, T. Takiguchi, Y. Ariki. Voice conversion based on speaker‐dependent
restricted Boltzmann machines. IEICE Trans. Inf. & Syst., Vol. E67‐D, No. 6, pp. 1403–1410, 2014.
[Nakashika; ’16] T. Nakashika, T. Takiguchi, Y. Minami. Non‐parallel training in voice conversion using an
adaptive restricted Boltzmann machine. IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 24, No. 11,
pp. 2032–2045, 2016.
[Nankaku; ’07] Y. Nankaku, K. Nakamura, T. Toda, K. Tokuda. Spectral conversion based on statistical models
including time‐sequence matching. Proc. ISCA SSW6, pp. 333–338, 2007.
[Narendranath; ’95] M. Narendranath, H.A. Murthy, S. Rajendran, B. Yegnanarayana. Transformation of
formants for voice conversion using artificial neural networks. Speech Commun., Vol. 16, No. 2, pp. 207–
216, 1995.
[Niwa; ’18] J. Niwa, T. Yoshimura, K. Hashimoto, K. Oura, Y. Nankaku, K. Tokuda. Statistical voice conversion
based on WaveNet. Proc. IEEE ICASSP, pp. 5289–5293, 2018.
[Ohtani; ’06] Y. Ohtani, T. Toda, H. Saruwatari, K. Shikano. Maximum likelihood voice conversion based on
GMM with STRAIGHT mixed excitation. Proc. INTERSPEECH, pp. 2266–2269, 2006.
[Ohtani; ’09] Y. Ohtani, T. Toda, H. Saruwatari, K. Shikano. Many‐to‐many eigenvoice conversion with
reference voice. Proc. INTERSPEECH, pp. 1623–1626, 2009.
[Pilkington; ’11] N. Pilkington, H. Zen, M.J.F. Gales. Gaussian process experts for voice conversion. Proc.
INTERSPEECH, pp. 2761–2764, 2011.
References: 5](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-78-320.jpg)
![[Richmond; ’03] K. Richmond, S. King, P. Taylor. Modelling the uncertainty in recovering articulation from
acoustics. Computer Speech & Lang., Vol. 17, No. 2, pp. 153–172, 2003.
[Saito; ’18] Y. Saito, S. Takamichi, H. Saruwatari. Statistical parametric speech synthesis incorporating
generative adversarial networks. IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 26, No. 1, pp. 84–96,
2018.
[Stylianou, ’96] Y. Stylianou. Harmonic plus noise models for speech, combined with statistical methods,
for speech and speaker modification. Ph.D thesis, Ecole Nationale Superieure des Telecommunications,
1996.
[Stylianou; ’98] Y. Stylianou, O. Cappe, E. Moulines. Continuous probabilistic transform for voice conversion.
IEEE Trans. Speech & Audio Process., Vol. 6, No. 2, pp. 131–142, 1998.
[Suendermann; ’05a] D. Suendermann, A. Bonafonte, H. Ney, H. Hoege. A study on residual prediction
techniques for voice conversion. Proc. IEEE ICASSP, Vol. 1, pp. 13–16, 2005.
[Suendermann; ’05b] D. Suendermann, A. Bonafonte, H. Duxans, H. Hoege. TC‐STAR: evaluation plan for
voice conversion technology. Proc. DAGA, pp. 737–738, 2005.
[Suendermann; ’06] D. Suendermann, H. Hoege, A. Bonafonte, H. Ney, A. Black, S. Narayanan. Text‐
independent voice conversion based on unit selection. Proc. IEEE ICASSP, pp. 81–84, 2006.
[Sun; ’15] L. Sun, S. Kang, K. Li, H.M. Meng. Voice conversion using deep bidirectional long short‐term
memory based recurrent neural networks. Proc. IEEE ICASSP, pp. 4869–4873, 2015.
[Sun; ’16] L. Sun, K. Li, H. Wang, S. Kang, H.M. Meng. Phonetic posteriorgrams for many‐to‐one voice
conversion without parallel data training. Proc. IEEE ICME, 6 pages, 2016.
[Takamichi; ’15] S. Takamichi, T. Toda, A.W. Black, S. Nakamura. Modulation spectrum‐constrained
trajectory training algorithm for HMM‐based speech synthesis. Proc. INTERSPEECH, pp. 1206–1210, 2015.
[Takamichi; ’16] S. Takamichi, T. Toda, A.W. Black, G. Neubig, S. Sakti, S. Nakamura. Post‐filters to modify
the modulation spectrum for statistical parametric speech synthesis. IEEE/ACM Trans. Audio, Speech &
Lang. Process., Vol. 24, No. 4, pp. 755–767, 2016.
References: 6](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-79-320.jpg)
![[Takashima; ’13] R. Takashima, T. Takiguchi, Y. Ariki. Exemplar‐based voice conversion using sparse
representation in noisy environments. IEICE Trans. Inf. & Syst., Vol. E96‐A, No. 10, pp. 1946–1953, 2013.
[Tamamori; ’17] A. Tamamori, T. Hayashi, K. Kobayashi, K. Takeda, T. Toda. Speaker‐dependent WaveNet
vocoder. Proc. INTERSPEECH, pp. 1118–1122, 2017.
[Tanaka; ’17] K. Tanaka, T. Toda, S. Nakamura. A vibration control method of an electrolarynx based on
statistical F0 pattern prediction. IEICE Trans. Inf. & Syst., Vol. E100‐D, No. 9, pp. 2165–2173, 2017.
[Tobing; ’17] P.L. Tobing, K. Kobayashi, T. Toda. Articulatory controllable speech modification based on
statistical inversion and production mappings. IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 25, No.
12, pp. 2337–2350, 2017.
[Tobing; ’18] P.L. Tobing, Y. Wu, T. Hayashi, K. Kobayashi, T. Toda. NU voice conversion system for the voice
conversion challenge 2018. Proc. Odyssey, pp. 219–226, 2018.
[Toda; ’06] T. Toda, Y. Ohtani, K. Shikano. Eigenvoice conversion based on Gaussian mixture model. Proc.
INTERSPEECH, pp. 2446–2449, 2006.
[Toda; ’07] T. Toda, A.W. Black, K. Tokuda. Voice conversion based on maximum likelihood estimation of
spectral parameter trajectory. IEEE Trans. Audio, Speech & Lang. Process., Vol. 15, No. 8, pp. 2222–2235,
2007.
[Toda; ’08] T. Toda, A.W. Black, K. Tokuda. Statistical mapping between articulatory movements and
acoustic spectrum using a Gaussian mixture model. Speech Commun., Vol. 50, No. 3, pp. 215–227, 2008.
[Toda; ’12a] T. Toda, M. Nakagiri, K. Shikano. Statistical voice conversion techniques for body‐conducted
unvoiced speech enhancement. IEEE Trans. Audio, Speech & Lang. Process., Vol. 20, No. 9, pp. 2505–2517,
2012.
[Toda; ’12b] T. Toda, T. Muramatsu, H. Banno. Implementation of computationally efficient real‐time voice
conversion. Proc. INTERSPEECH, 4 pages, 2012.
[Toda, ’14] T. Toda. Augmented speech production based on real‐time statistical voice conversion. Proc.
GlobalSIP, pp. 755–759, 2014.
References: 7](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-80-320.jpg)
![[Toda; ’16] T. Toda, L.‐H. Chen, D. Saito, F. Villavicencio, M. Wester, Z. Wu, J. Yamagishi. The Voice
Conversion Challenge 2016. Proc. INTERSPEECH, pp. 1632–1636, 2016.
[Tokuda; ’00] K. Tokuda, T. Yoshimura, T. Masuko, T. Kobayashi, T. Kitamura. Speech parameter generation
algorithms for HMM‐based speech synthesis. Proc. IEEE ICASSP, pp. 1315–1318, 2000.
[Valbret; ’92] H. Valbret, E. Moulines and J. P. Tubach. Voice transformation using PSOLA technique. Speech
Commun., Vol. 11, No. 2–3, pp. 175–187, 1992.
[van den Oord; ’16a] A. van den Oord, N. Kalchbrenner, O. Vinyals, L. Espeholt, A. Graves, K. Kavukcuoglu.
Conditional image generation with PixelCNN decoders. arXiv preprint, arXiv:1606.05328, 13 pages, 2016.
[van den Oord; ’16b] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N.
Kalchbrenner, A. W. Senior, and K. Kavukcuoglu. WaveNet: a generative model for raw audio. arXiv preprint,
arXiv:1609.03499, 15 pages, 2016.
[van den Oord; ’17] A. van den Oord, O. Vinyals, K. Kavukcuoglu. Neural discrete representation learning.
arXiv preprint, arXiv:1711.00937, 11 pages, 2017.
[Villavicencio; ’10] F. Villavicencio, J. Bonada. Applying voice conversion to concatenative singing‐voice
synthesis. Proc. INTERSPEECH, pp. 2162–2165, 2010.
[Wu; ’14] Z. Wu, T. Virtanen, E. Chng, H. Li. Exemplar‐based sparse representation with residual
compensation for voice conversion. IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 22, No. 10, pp.
1506–1521, 2014.
[Wu; ’15] Z. Wu, N. Evans, T. Kinnunen, J. Yamagishi, F. Alegre, H. Li. Spoofing and countermeasures for
speaker verification: A survey. Speech Commun. Vol. 66, pp. 130–153, 2015.
[Wu; ’17] Z. Wu, J. Yamagishi, T. Kinnunen, C. Hanilci, M. Sahidullah, A. Sizov, N. Evans, M. Todisco, H.
Delgado. ASVspoof: the automatic speaker verification spoofing and countermeasures challenge. IEEE J.
Sel. Topics in Signal Process., Vol. 11, No. 4, pp. 588–604, 2017.
[Xu; ’14] N. Xu, Y. Tang, J. Bao, A. Jiang, X. Liu, Z. Yang. Voice conversion based on Gaussian processes by
coherent and asymmetric training with limited training data. Speech Commun., Vol. 58, pp. 124–138, 2014.
References: 8](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-81-320.jpg)
![[Ye; ’06] H. Ye, S. Young. Quality‐enhanced voice morphing using maximum likelihood transformations.
IEEE Trans. Audio, Speech & Lang. Process., Vol. 14, No. 4, pp. 1301–1312, 2006.
[Zen; ’12] H. Zen, M.J.F. Gales, Y. Nankaku, K. Tokuda. Product of experts for statistical parametric speech
synthesis. IEEE Trans. Audio, Speech & Lang. Process., Vol. 20, No. 3, pp. 794–805, 2012.
[Zhu; ’17] J.‐Y. Zhu, T. Park, P. Isola, A.A. Efros. Unpaired image‐to‐image translation using cycle‐consistent
adversarial networks. Proc. ICCV, pp. 2223–2232, 2017.
<Special issues>
• E. Moulines, Y. Sagisaka, Voice conversion: state of the art and perspectives. Speech Commun., Vol. 16,
No. 2, 1995.
• Y. Stylianou, T. Toda, C.‐H. Wu, A. Kain, O. Rosec. The special section on voice transformation. IEEE
Trans. Audio, Speech & Lang., Vol. 18, No. 5, 2010.
<Survey>
• H. Mohammadi, A. Kain. An overview of voice conversion systems. Speech Commun. Vol. 88, pp. 65–82,
2017.
References: 9](https://image.slidesharecdn.com/lectureslidesspcc2018tomokitoda-180730011904/85/Advanced-Voice-Conversion-82-320.jpg)






















































































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)
