1 2 34 5
0
20
40
60
80
100
MOS on naturalness
Correctrate[%]on
speakersimilarity
Target
Source
Baseline
良い
良い
A
B
C
D
E
F
G
H
I
J
K
LM
N
O
P
Q
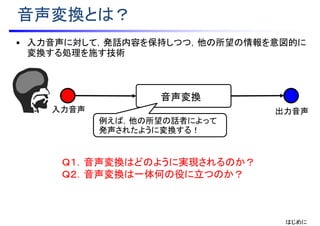
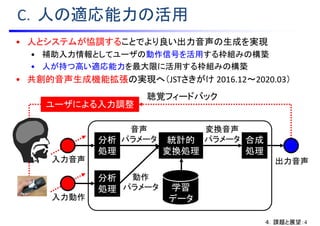
• 統計的音声変換手法の性能比較には共通の音声データセットを用いた
評価が必要不可欠
• Voice Conversion Challenge 2016 の開催 [Toda et al., 2016]
• タスク:話者変換(5話者⇒5話者,162文対で学習,別の54文を評価)
• データセット:DAPS [Mysore, 2015] を利用
• 参加チーム数:17
• 中国:4
• 日本:3
• インド:3
• 英国:2
• 香港:1
• 台湾:1
• シンガポール:1
• スペイン:1
• 米国:1
B.手法の評価
4.課題と展望:3
21.
1 2 34 5
0
20
40
60
80
100
MOS on naturalness
Correctrate[%]on
speakersimilarity
Target
Source
Baseline
良い
良い
A
B
C
D
E
F
G
H
I
J
K
LM
N
O
P
Q
• 統計的音声変換手法の性能比較には共通の音声データセットを用いた
評価が必要不可欠
• Voice Conversion Challenge 2016 の開催 [Toda et al., 2016]
• タスク:話者変換(5話者⇒5話者,162文対で学習,別の54文を評価)
• データセット:DAPS [Mysore, 2015] を利用
• 参加チーム数:17
• 中国:4
• 日本:3
• インド:3
• 英国:2
• 香港:1
• 台湾:1
• シンガポール:1
• スペイン:1
• 米国:1
B.手法の評価
正解率 = 75%
MOS = 3.5
4.課題と展望:3
22.
1 2 34 5
0
20
40
60
80
100
MOS on naturalness
Correctrate[%]on
speakersimilarity
Target
Source
Baseline
良い
良い
A
B
C
D
E
F
G
H
I
J
K
LM
N
O
P
Q
• 統計的音声変換手法の性能比較には共通の音声データセットを用いた
評価が必要不可欠
• Voice Conversion Challenge 2016 の開催 [Toda et al., 2016]
• タスク:話者変換(5話者⇒5話者,162文対で学習,別の54文を評価)
• データセット:DAPS [Mysore, 2015] を利用
• 参加チーム数:17
• 中国:4
• 日本:3
• インド:3
• 英国:2
• 香港:1
• 台湾:1
• シンガポール:1
• スペイン:1
• 米国:1
B.手法の評価
正解率 = 75%
MOS = 3.5
4.課題と展望:3



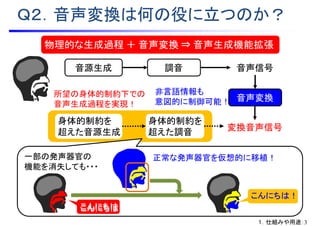
![• 確率的分析法(線形予測分析 [板倉 他],メル一般化ケプストラム分析 [徳田 他])
• 確率的生成モデルのパラメータ推定問題として定式化
• 決定的分析法(STRAIGHT [河原 他],WORLD [森勢 他],aQHM [Stylianou et al.])
• 音声信号を正確に表現/再現するパラメータを推定
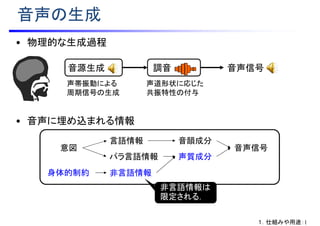
A.音声信号の分析技術
音声信号 ⇒ 音源信号 * 共振特性
e[n]:音源信号
(ガウス雑音)
H(z):共振モデル
(スペクトル包絡)
x[n]:音声信号
(観測データ)
推定
x[n]:音声信号
(観測データ)
基本周波数の抽出
音源信号の
周期成分を除去
共振特性
(スペクトル包絡)
2.要素技術:1](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-9-320.jpg)

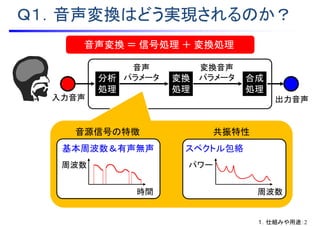
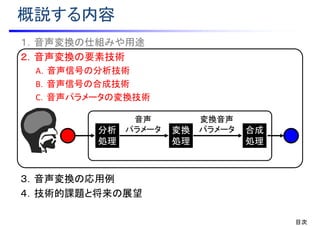
![スペクトル包絡
励振源波形
パルス列
白色雑音
再合成音声波形
合成フィルタ
)(zH
励振源生成部 共振付与部
][*][][ nenhnx
基本周波数&有声無声
音声パラメータ(音声波形 から抽出)
][ne
ボコーダ:音源信号 * 共振特性 ⇒ 音声波形
B.音声信号の合成技術
歪んだ音声パラメータ
への対応も重要!
• 利点:音声波形の特徴を容易に制御可能
• 欠点:モデリングによる近似誤差
2.要素技術:3](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-11-320.jpg)
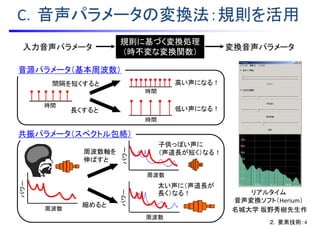
![C.音声パラメータの変換法:統計的手法
学習データ
入力音声パラメータ
統計的な変換処理
(非線形変換関数)
変換音声パラメータ
• 回帰問題として音声パラメータ変換処理を定式化
• 声質変換(Voice Conversion)技術として進展
フレーム単位の変換 [阿部 他]
代表点の対応
付け [阿部 他]
確率モデルの
導入 [Stylianou et al.]
高精度化
DNN/RNN
事例ベース
所望の特徴を変換する
変換関数が得られるように
学習データを設計
1990 1995 2000 2005 2010 2015
系列単位の変換 [戸田 他]
確率的変動/揺らぎ成分の
モデル化 [戸田 他][高道 他]
回帰問題ではあるが誤差最小が良いとは限らない!
音声信号の確率的変動/揺らぎ成分を消失させ,
変換音声の音質劣化を招く傾向あり!
2.要素技術:5](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-13-320.jpg)


![音声変換の応用例
• 統計的音声変換における学習データを適切に設計することで
様々な変換処理を実現可能
• 例:音声生成機能拡張 [戸田 他]
• 音声入力の利点(瞬時性)を活用
• リアルタイム音声変換処理を音声コミュニケーション拡張に適用
身体的制約を
超える発声補助
環境的制約を
超える通話
能力的制約を
超える表現獲得
不可能を可能として未知の体験をもたらす応用例が存在!
発声障碍者
の音声を
より自然な
音声へ
聞きとれないほど
微弱な音声を
より明瞭な
音声へ
現時点での
歌声を
若返った歌声へ
年老いた歌声へ
3.応用例](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-16-320.jpg)
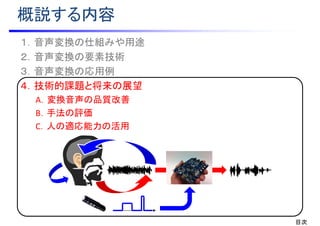
![A.変換音声の品質改善
• 音声信号の確率的揺らぎを如何に再現するか?
• DNN/RNNの生成学習 [Chen et al.]や敵対的学習 [齋藤 他][金子 他]
• 波形合成(ボコーダ)処理による劣化を如何に抑えるか?
• 波形加工処理による脱ボコーダ [小林 他]
出力音声入力音声
学習
データ
波形加工
処理
統計的
変換処理
学習データ
分析
処理
音声
パラメータ
加工パラメータ
4.課題と展望:1](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-18-320.jpg)
![A.高品質波形生成モデルの登場
• ニューラルネットワークを用いた非線形自己回帰モデルによる波形生成法
(WaveNet [van den Oord et al., 2016],Sample RNN [Mehri et al., 2017])
• 音声波形を離散シンボル系列として表現(=波形接続型方式)
• 離散シンボル系列の確率分布をモデル化(=確率的生成モデル方式)
• 音声信号の揺らぎ成分を高精度に表現可能!
• 信号処理と統計的変換処理を統合した統計的波形変換処理の実現へ!
出力音声入力音声
学習
データ
統計的波形変換処理
学習データ
4.課題と展望:2
生成された過去の
音声波形シンボル系列
非線形自己回帰
モデル(CNN/RNN)
現時点の音声波形
シンボルをランダム生成
][ˆ nx]1[ˆ],2[ˆ, nxnx](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-19-320.jpg)
![1 2 3 4 5
0
20
40
60
80
100
MOS on naturalness
Correctrate[%]on
speakersimilarity
Target
Source
Baseline
良い
良い
A
B
C
D
E
F
G
H
I
J
K
LM
N
O
P
Q
• 統計的音声変換手法の性能比較には共通の音声データセットを用いた
評価が必要不可欠
• Voice Conversion Challenge 2016 の開催 [Toda et al., 2016]
• タスク:話者変換(5話者⇒5話者,162文対で学習,別の54文を評価)
• データセット:DAPS [Mysore, 2015] を利用
• 参加チーム数:17
• 中国:4
• 日本:3
• インド:3
• 英国:2
• 香港:1
• 台湾:1
• シンガポール:1
• スペイン:1
• 米国:1
B.手法の評価
4.課題と展望:3](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-20-320.jpg)
![1 2 3 4 5
0
20
40
60
80
100
MOS on naturalness
Correctrate[%]on
speakersimilarity
Target
Source
Baseline
良い
良い
A
B
C
D
E
F
G
H
I
J
K
LM
N
O
P
Q
• 統計的音声変換手法の性能比較には共通の音声データセットを用いた
評価が必要不可欠
• Voice Conversion Challenge 2016 の開催 [Toda et al., 2016]
• タスク:話者変換(5話者⇒5話者,162文対で学習,別の54文を評価)
• データセット:DAPS [Mysore, 2015] を利用
• 参加チーム数:17
• 中国:4
• 日本:3
• インド:3
• 英国:2
• 香港:1
• 台湾:1
• シンガポール:1
• スペイン:1
• 米国:1
B.手法の評価
正解率 = 75%
MOS = 3.5
4.課題と展望:3](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-21-320.jpg)
![1 2 3 4 5
0
20
40
60
80
100
MOS on naturalness
Correctrate[%]on
speakersimilarity
Target
Source
Baseline
良い
良い
A
B
C
D
E
F
G
H
I
J
K
LM
N
O
P
Q
• 統計的音声変換手法の性能比較には共通の音声データセットを用いた
評価が必要不可欠
• Voice Conversion Challenge 2016 の開催 [Toda et al., 2016]
• タスク:話者変換(5話者⇒5話者,162文対で学習,別の54文を評価)
• データセット:DAPS [Mysore, 2015] を利用
• 参加チーム数:17
• 中国:4
• 日本:3
• インド:3
• 英国:2
• 香港:1
• 台湾:1
• シンガポール:1
• スペイン:1
• 米国:1
B.手法の評価
正解率 = 75%
MOS = 3.5
4.課題と展望:3](https://image.slidesharecdn.com/slides201703asjtoda-170521040038/85/slide-22-320.jpg)


















![[DL輪読会]Wavenet a generative model for raw audio](https://cdn.slidesharecdn.com/ss_thumbnails/wavenetagenerativemodelforrawaudio-160920054055-thumbnail.jpg?width=640&height=640&fit=bounds)






























