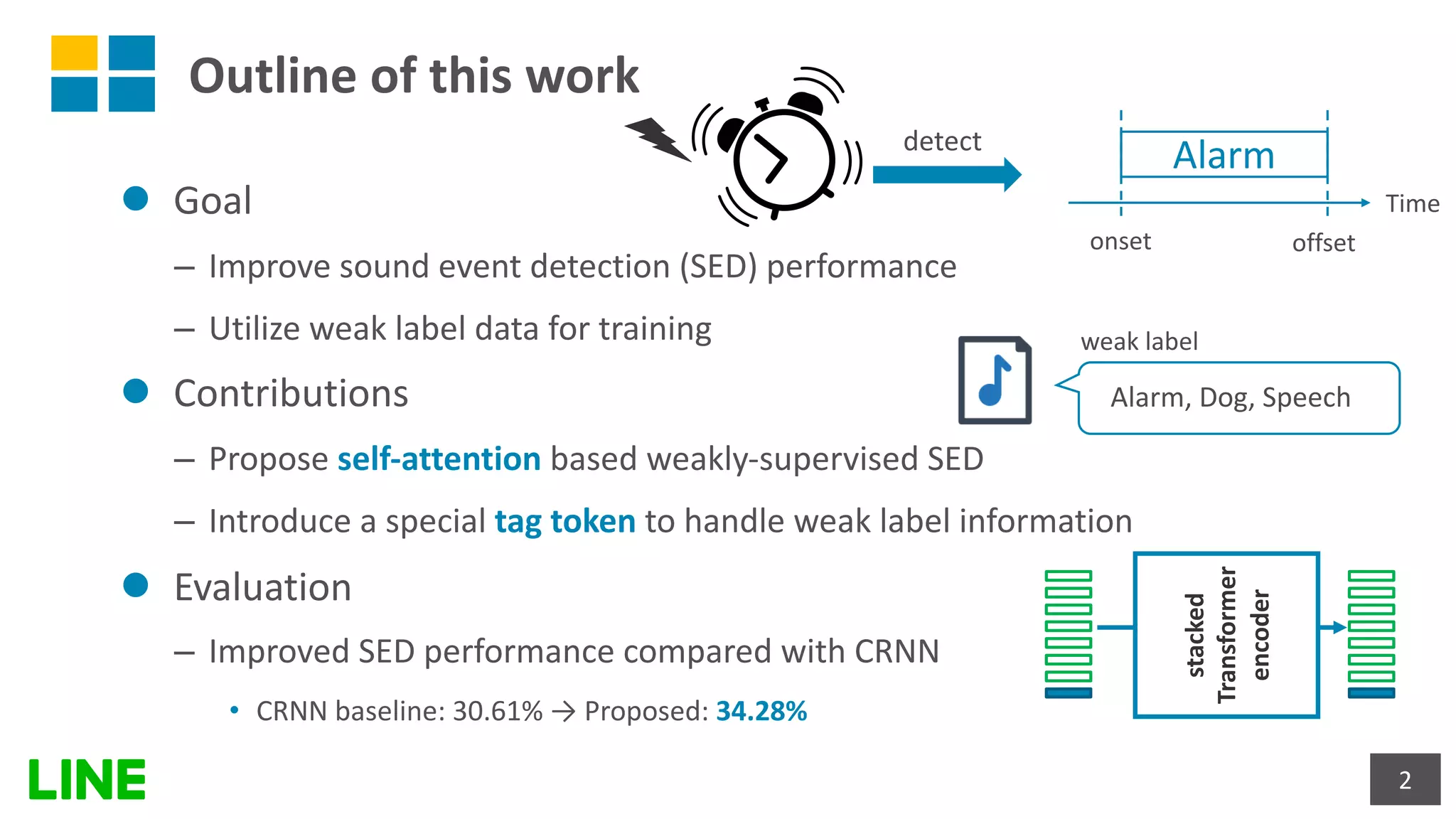
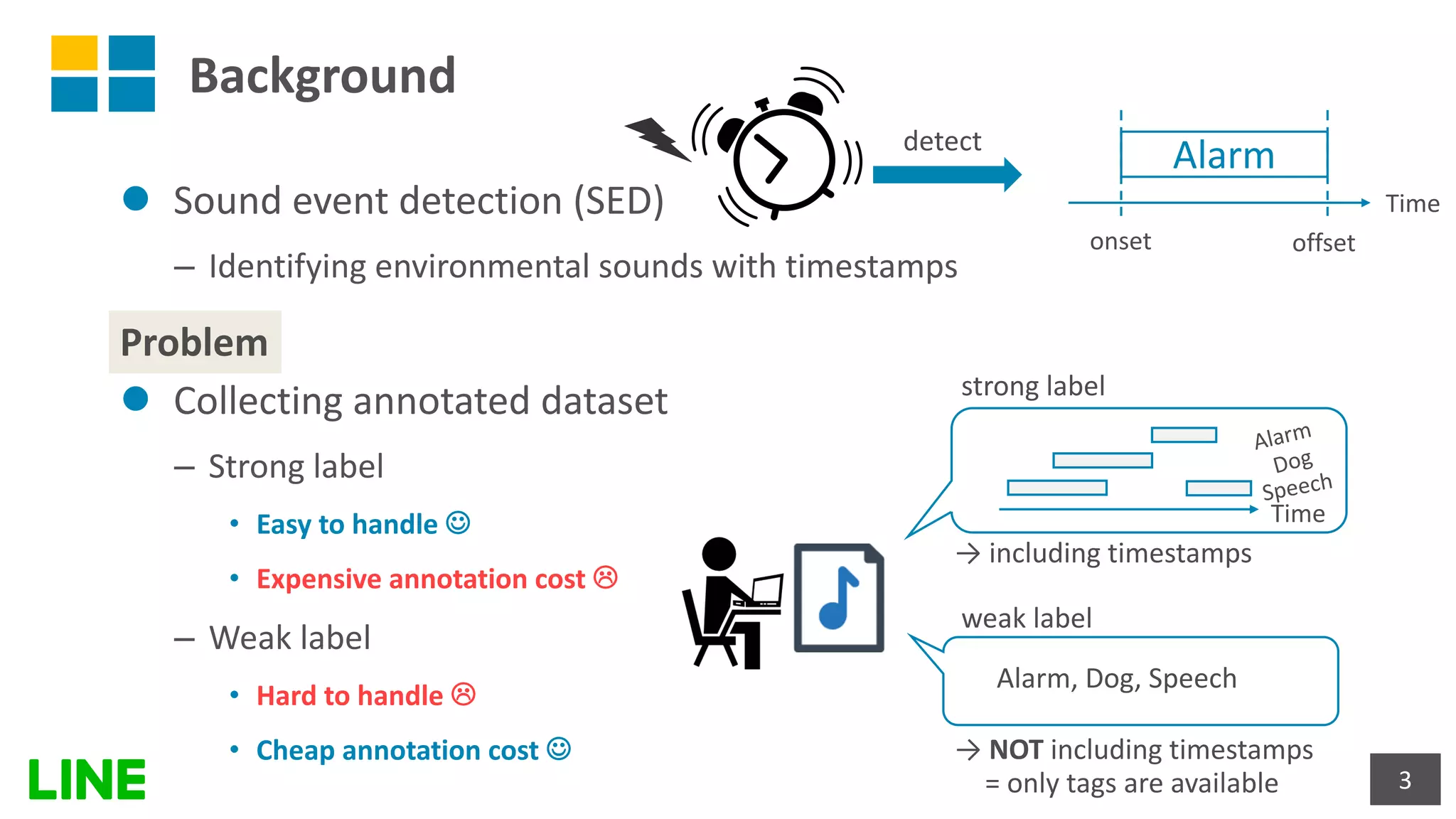
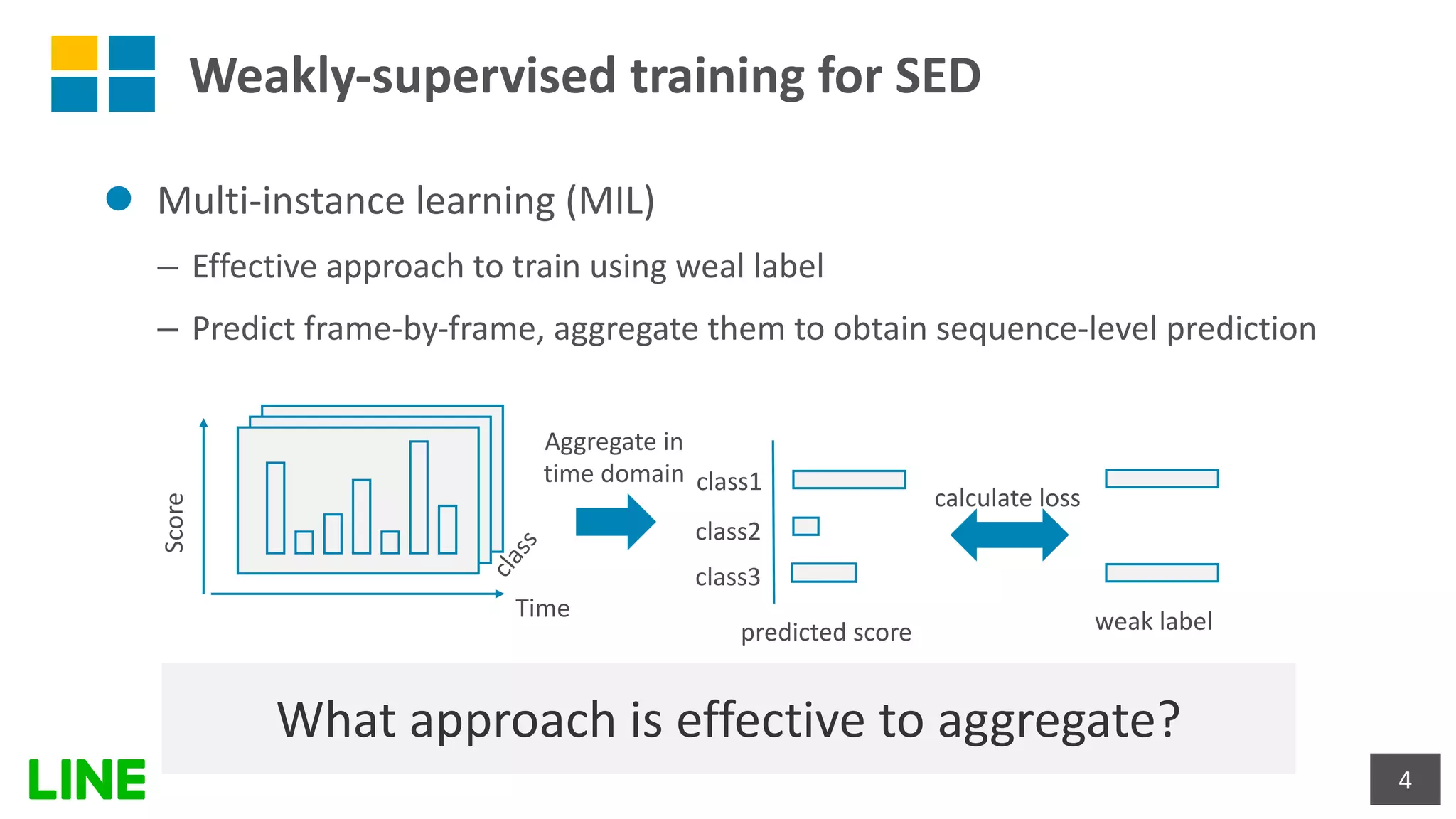
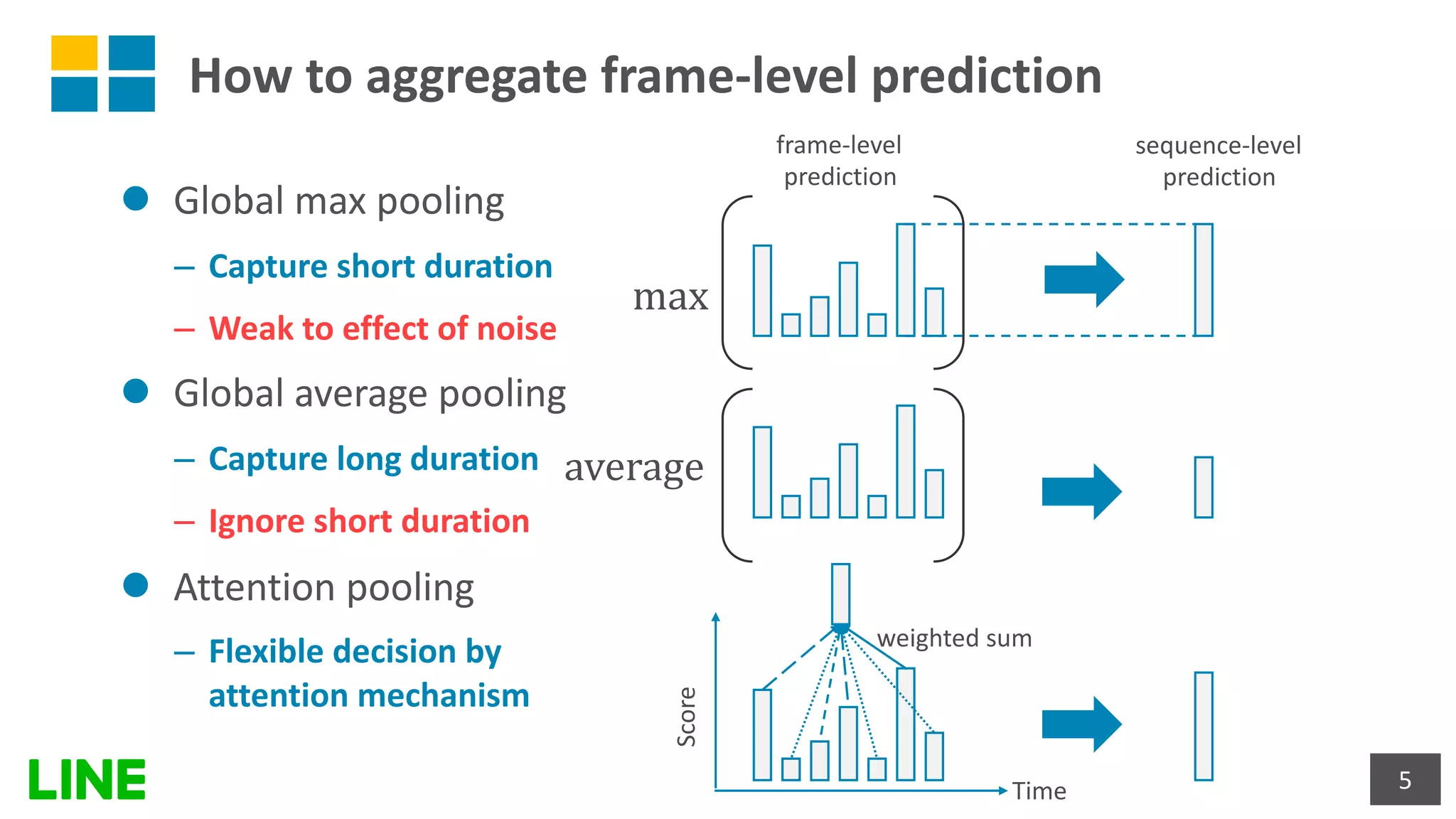
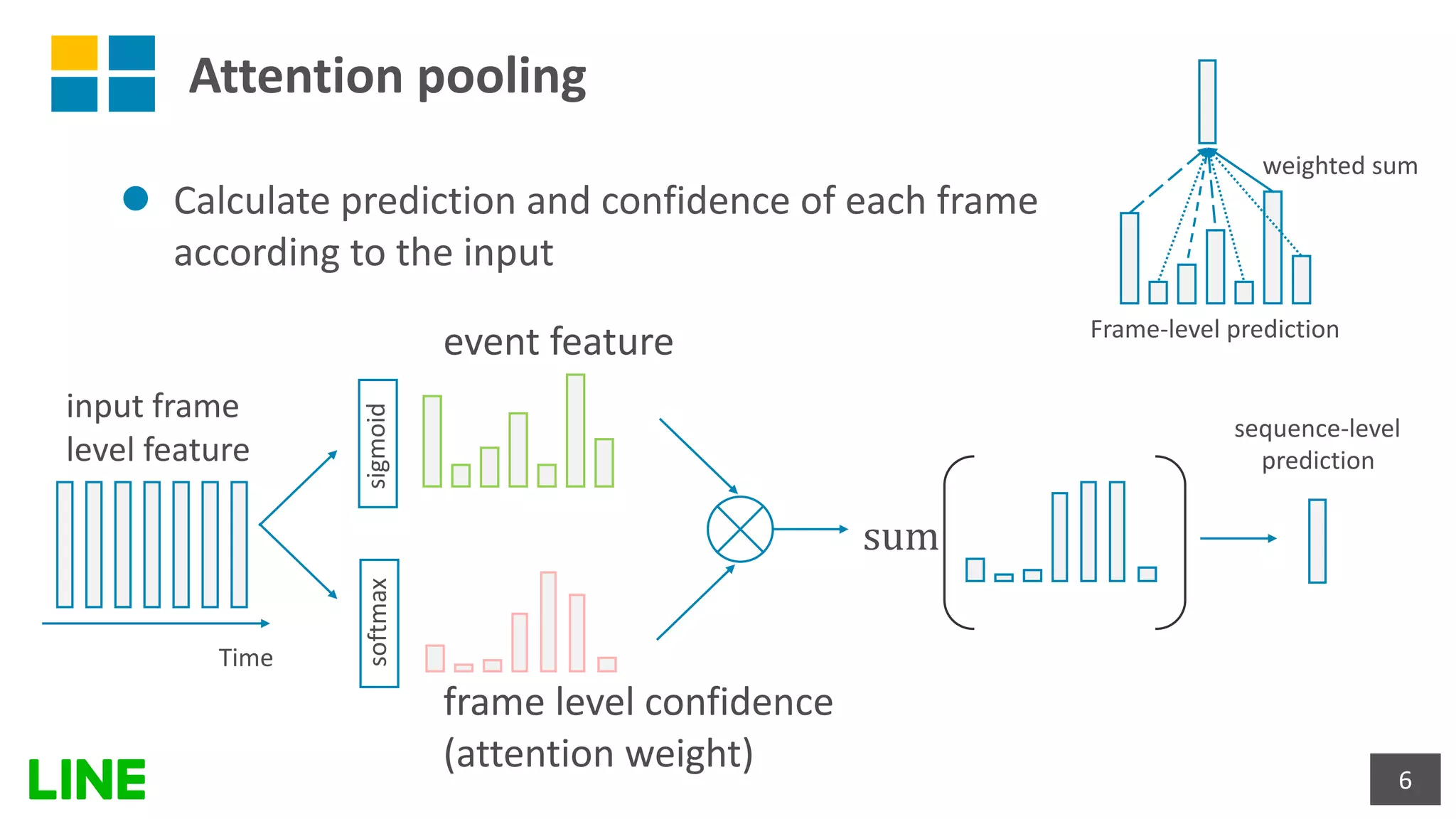
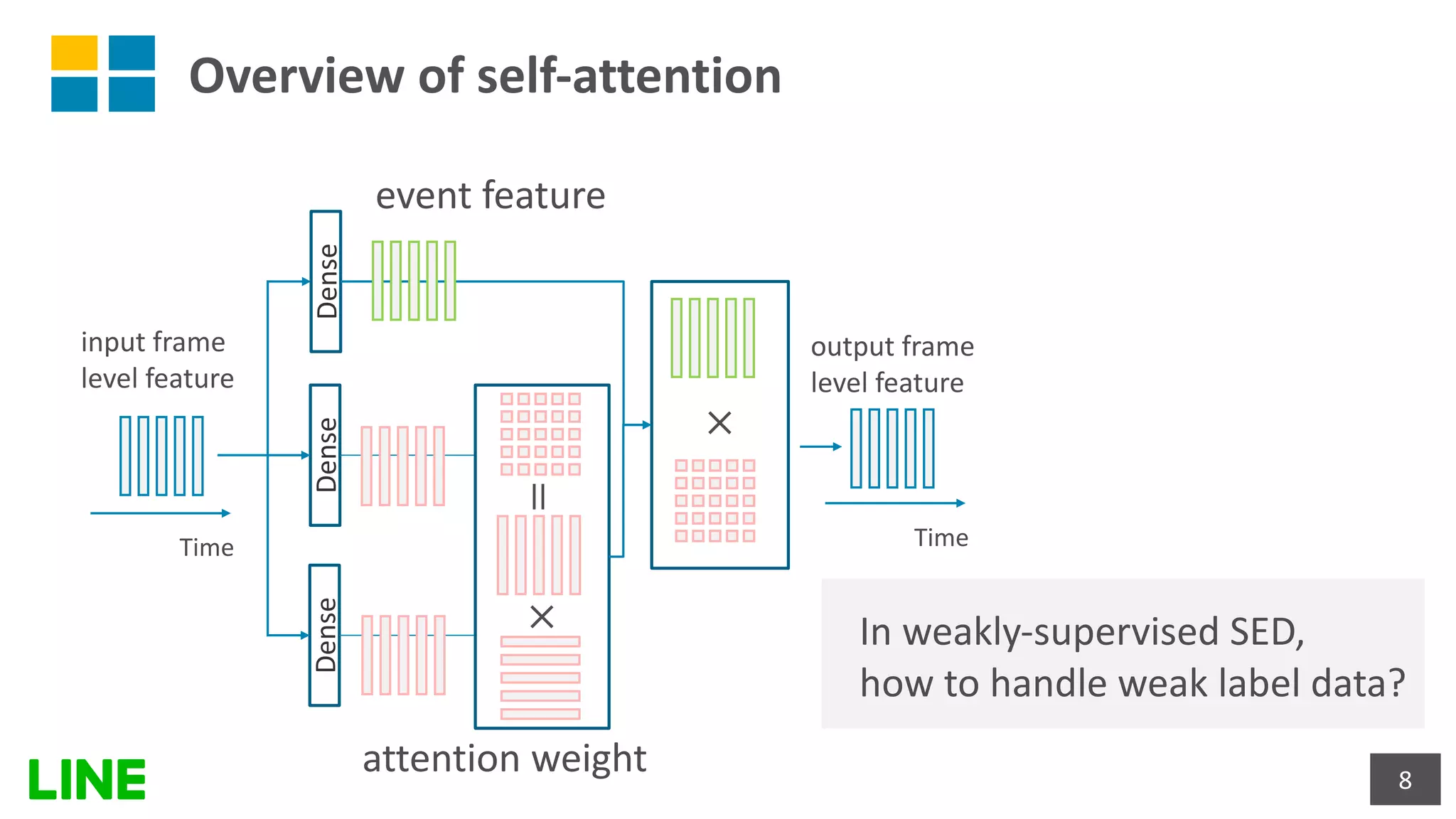
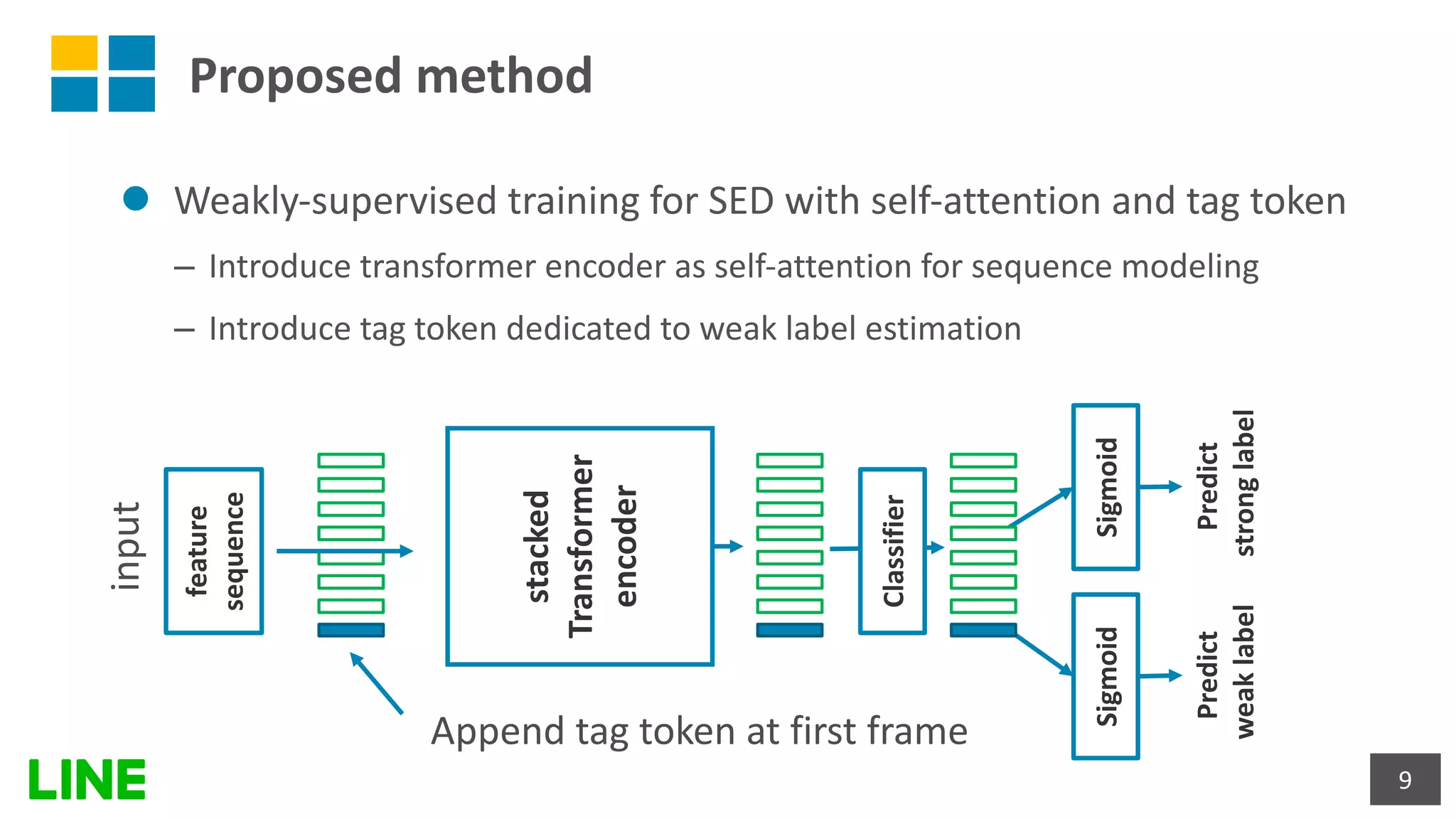
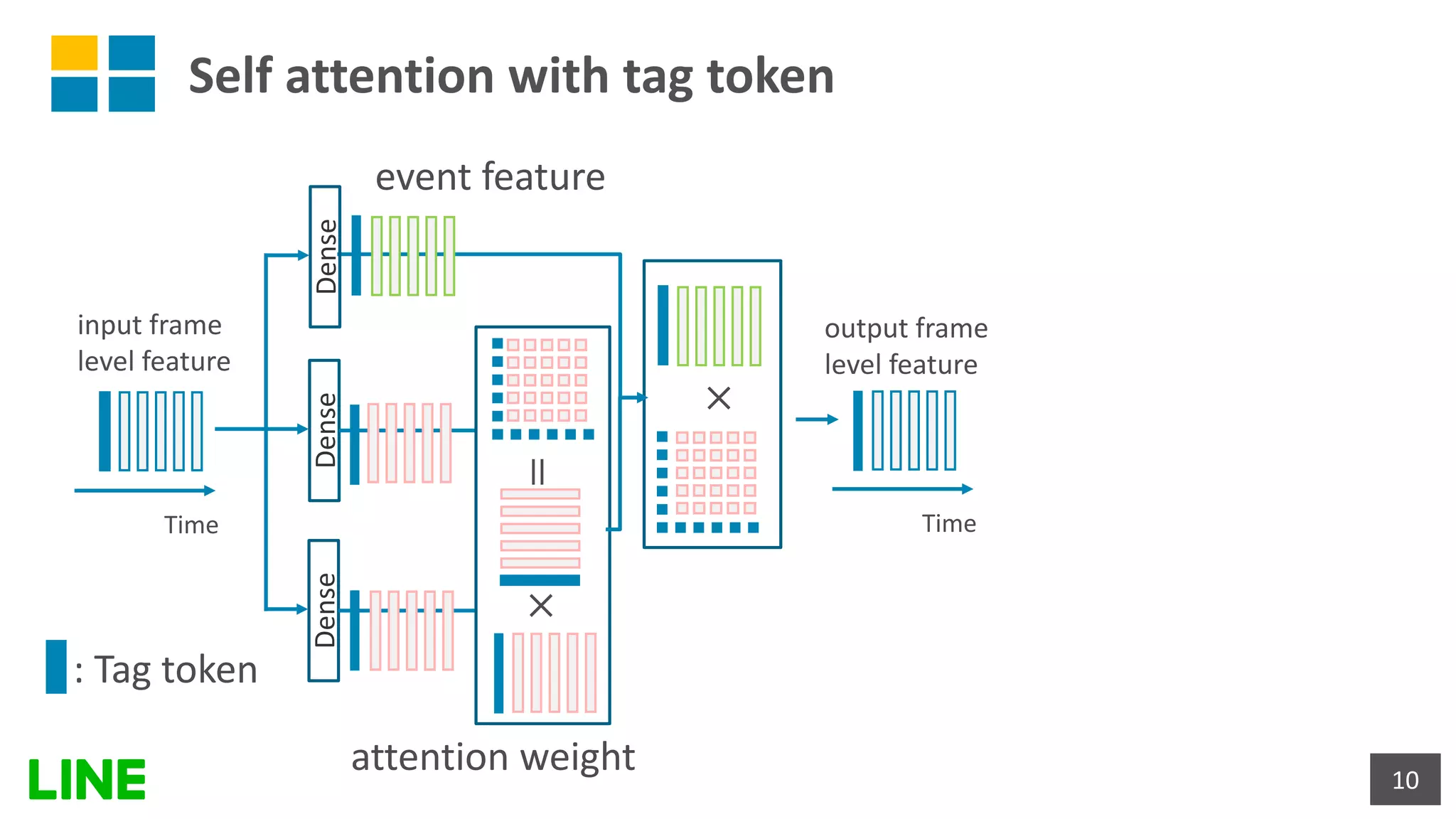
This document presents a weakly-supervised sound event detection method using self-attention, aiming to enhance detection performance through the utilization of weak label data. The proposed approach introduces a special tag token for weak label handling and employs a transformer encoder for improved sequence modeling, achieving performance improvements from a baseline CRNN model. Experimental results indicate a notable increase in sound event detection accuracy, with the new method outperforming the baseline in various evaluation metrics.

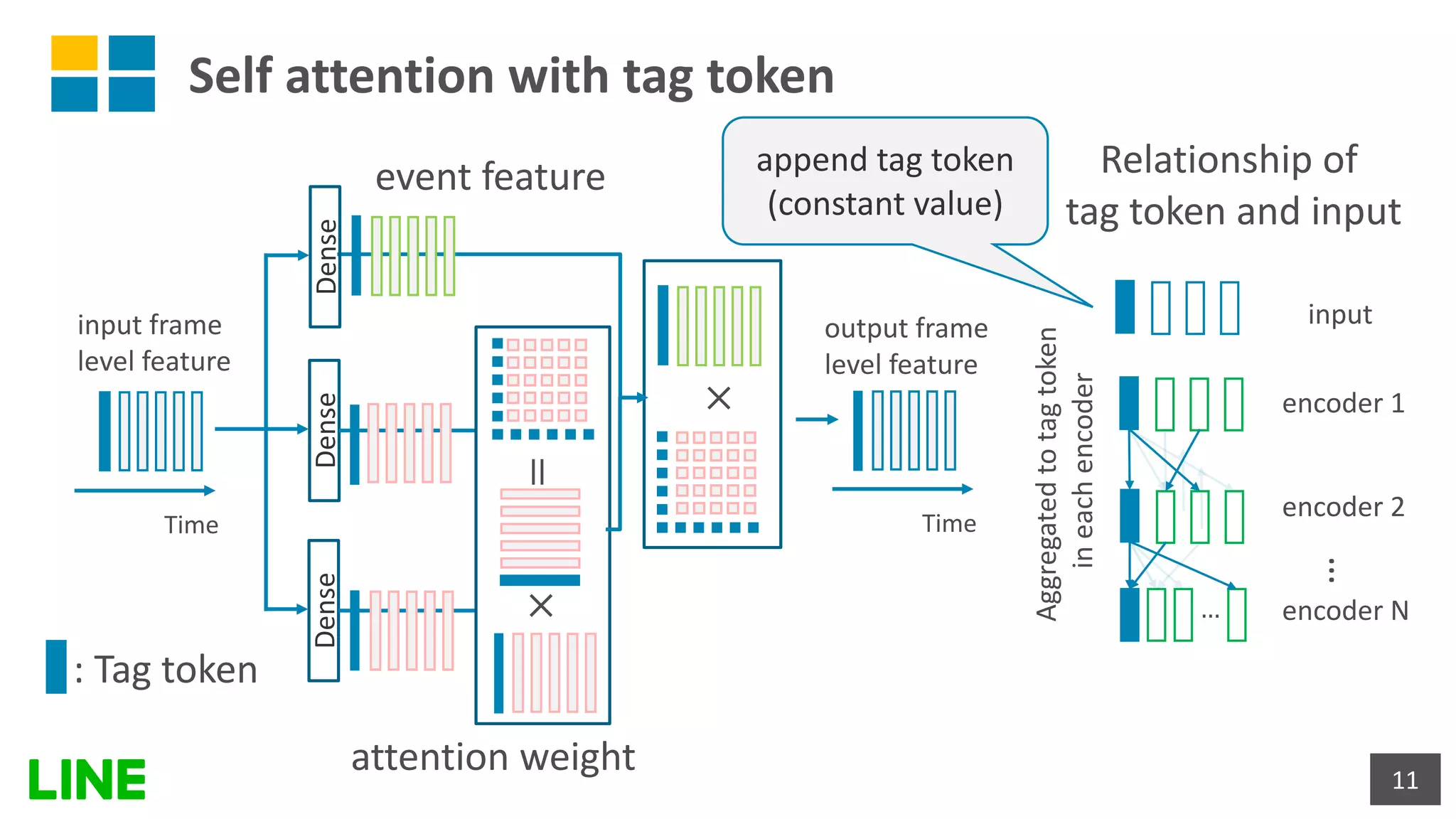
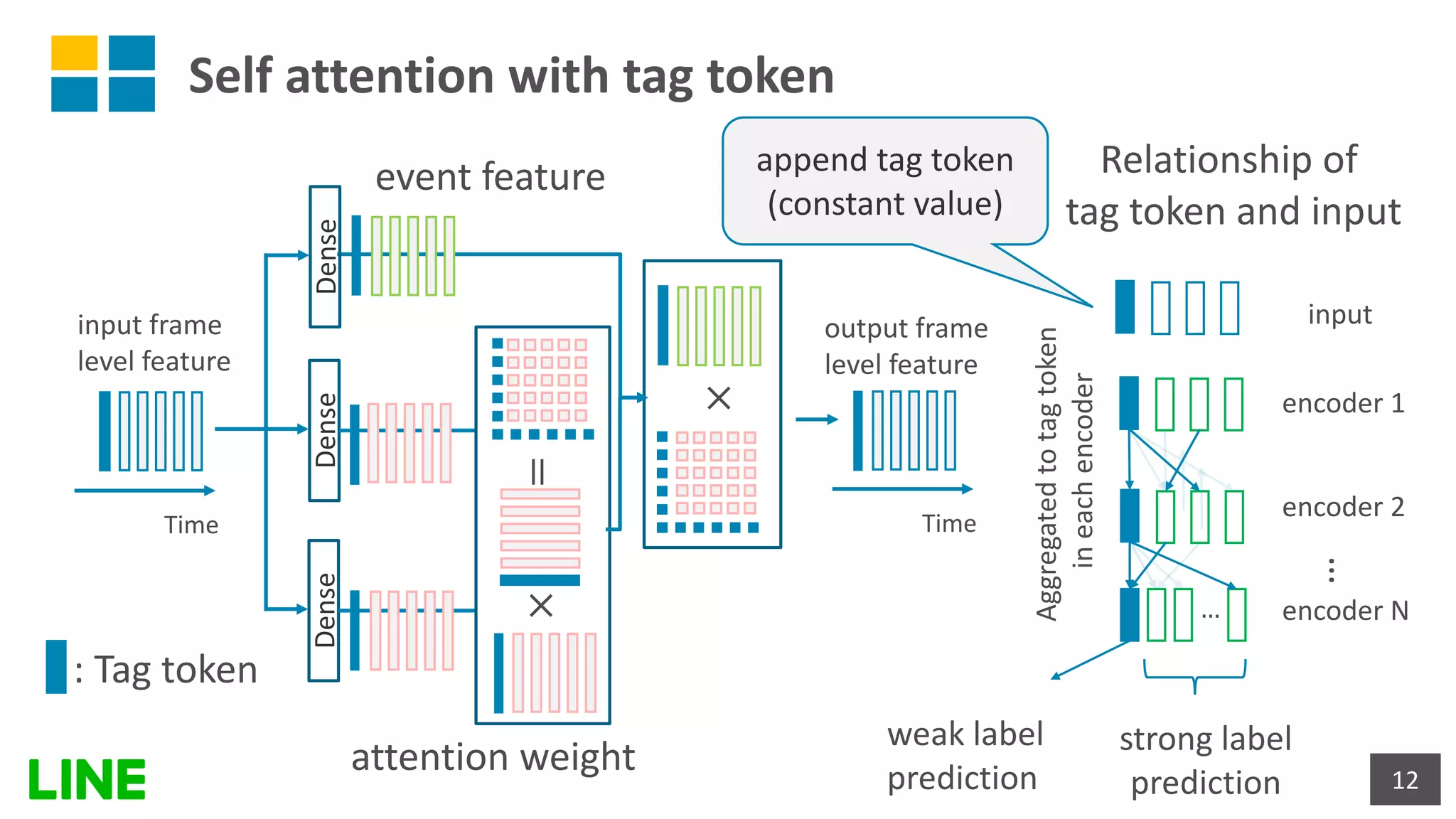
![Self-attention
l Transformer [Vaswani+17]
– Effectively use self-attention model
– Enable to capture local and global context information
– Great success in NLP, various audio/speech tasks
• ASR, speaker recognition, speaker diarization, TTS, etc..
7
Positional
Encoding
Multi-Head
Attention
Add & Norm
Feed
Forward
Add & Norm
N×
Transformerencoder
Input
Output
In this work, we use Transformer encoder](https://image.slidesharecdn.com/icassp2020slidesmiyazaki-200427005122/75/Weakly-Supervised-Sound-Event-Detection-with-Self-Attention-7-2048.jpg)
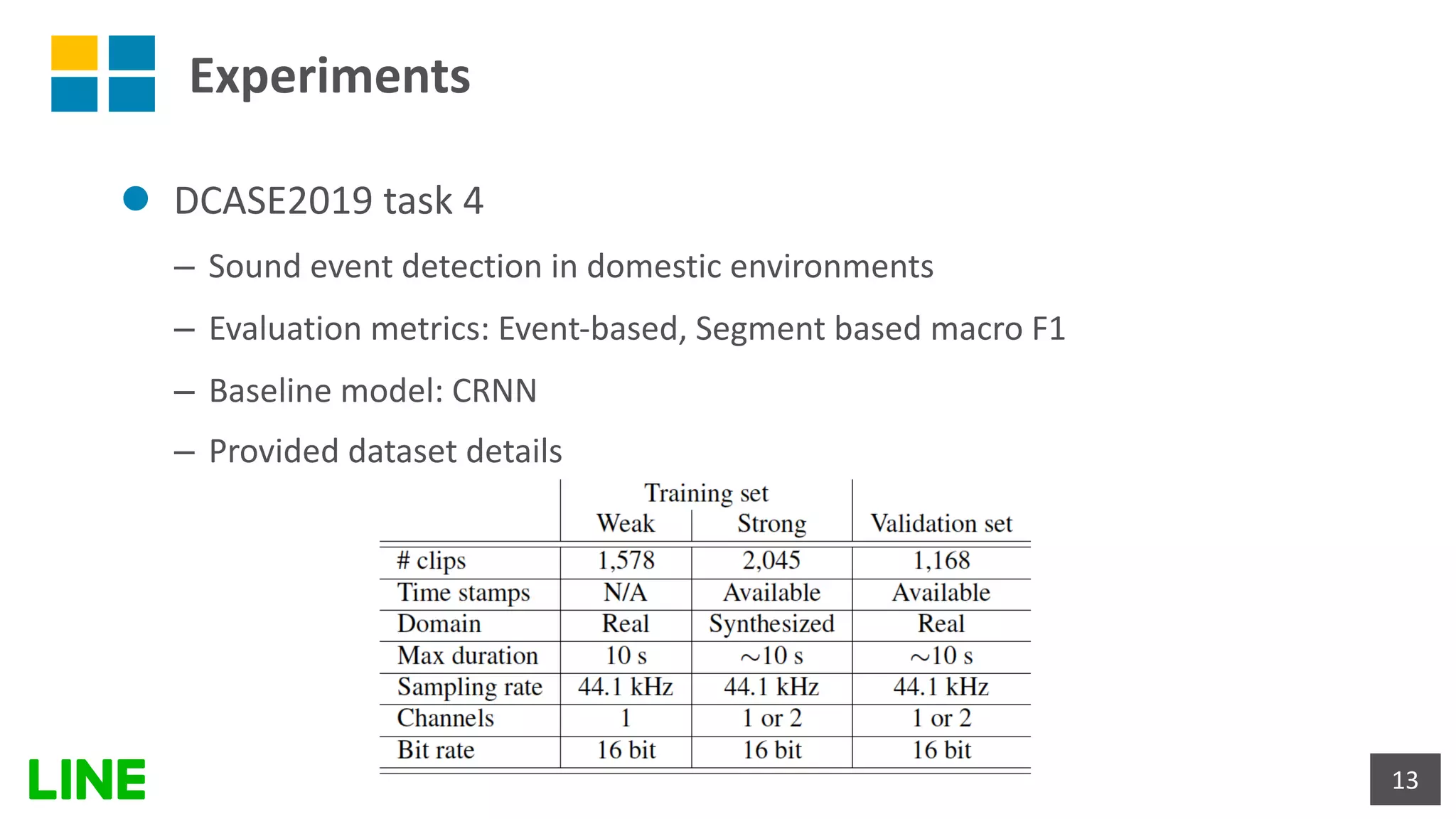
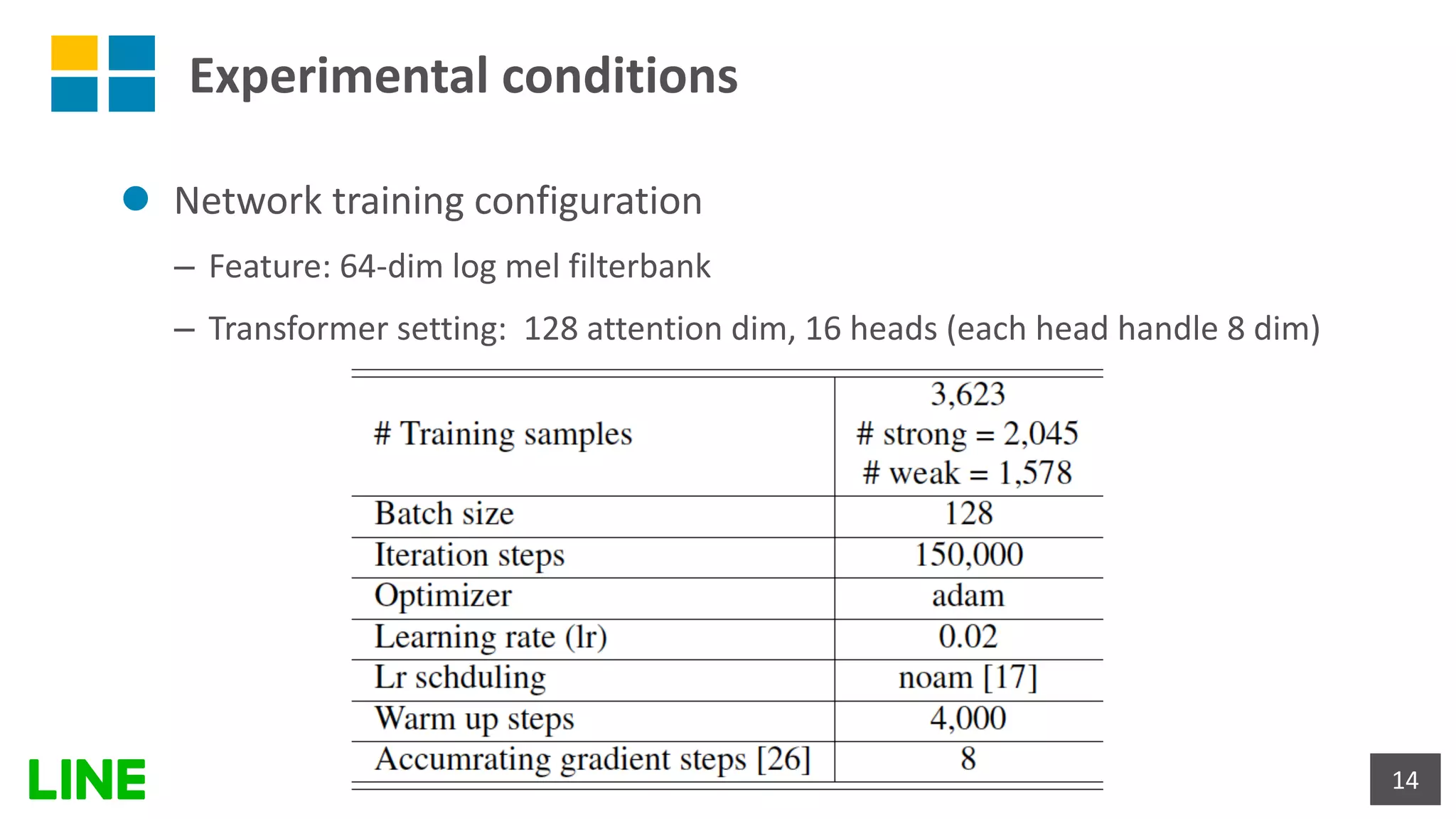
![Experimental results
15
Method Event-based[%] Segment-based[%] Frame-based[%]
CRNN(baseline) 30.61 62.21 60.94
Transformer(E=3) 34.27 65.07 61.85
Transformer(E=4) 33.05 65.14 62.00
Transformer(E=5) 31.81 63.90 60.78
Transformer(E=6) 34.28 64.33 61.26](https://image.slidesharecdn.com/icassp2020slidesmiyazaki-200427005122/75/Weakly-Supervised-Sound-Event-Detection-with-Self-Attention-15-2048.jpg)
![Experimental results
16
Method Event-based[%] Segment-based[%] Frame-based[%]
CRNN(baseline) 30.61 62.21 60.94
Transformer(E=3) 34.27 65.07 61.85
Transformer(E=4) 33.05 65.14 62.00
Transformer(E=5) 31.81 63.90 60.78
Transformer(E=6) 34.28 64.33 61.26
Transformer models outperformed CRNN model](https://image.slidesharecdn.com/icassp2020slidesmiyazaki-200427005122/75/Weakly-Supervised-Sound-Event-Detection-with-Self-Attention-16-2048.jpg)
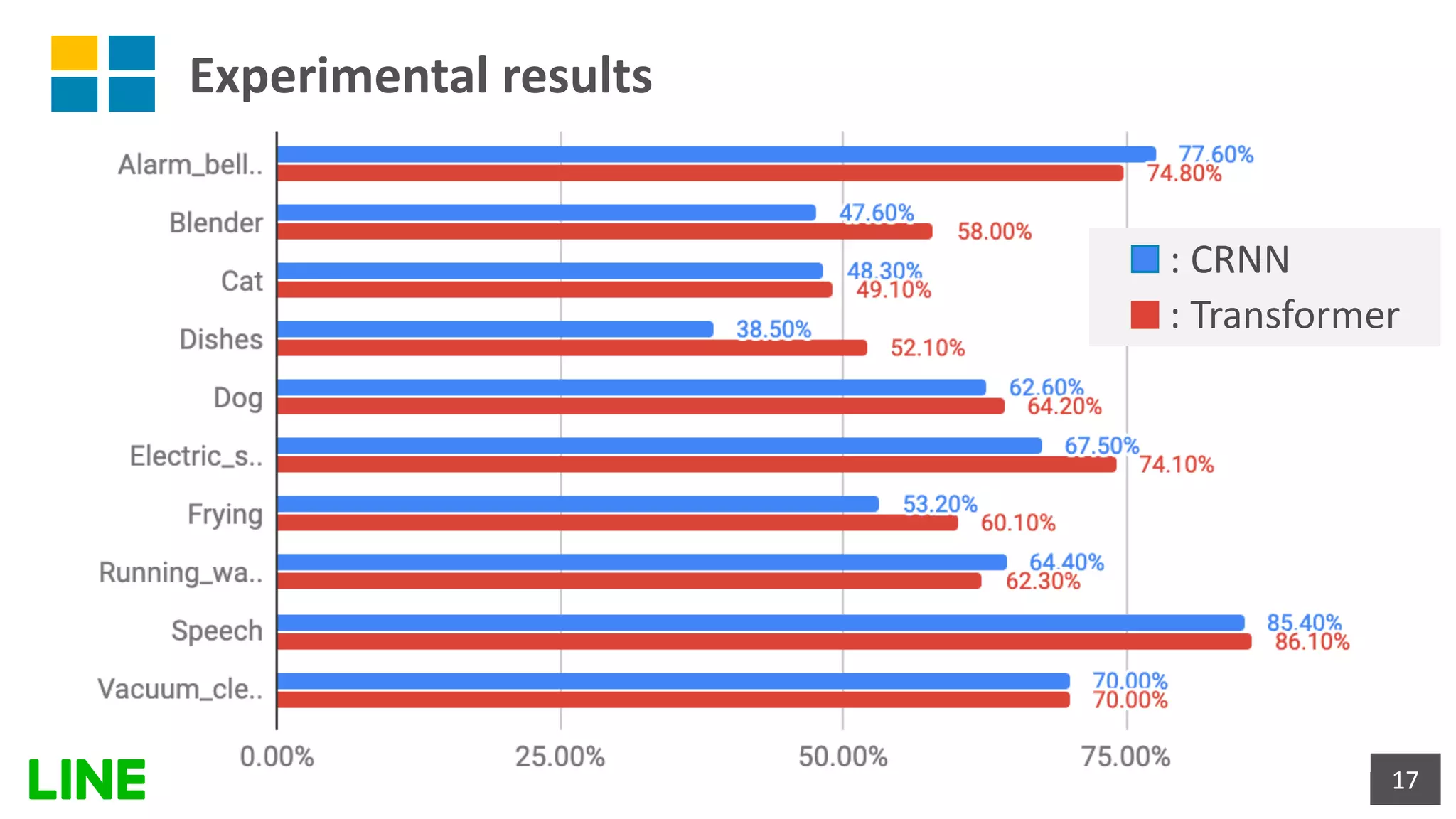
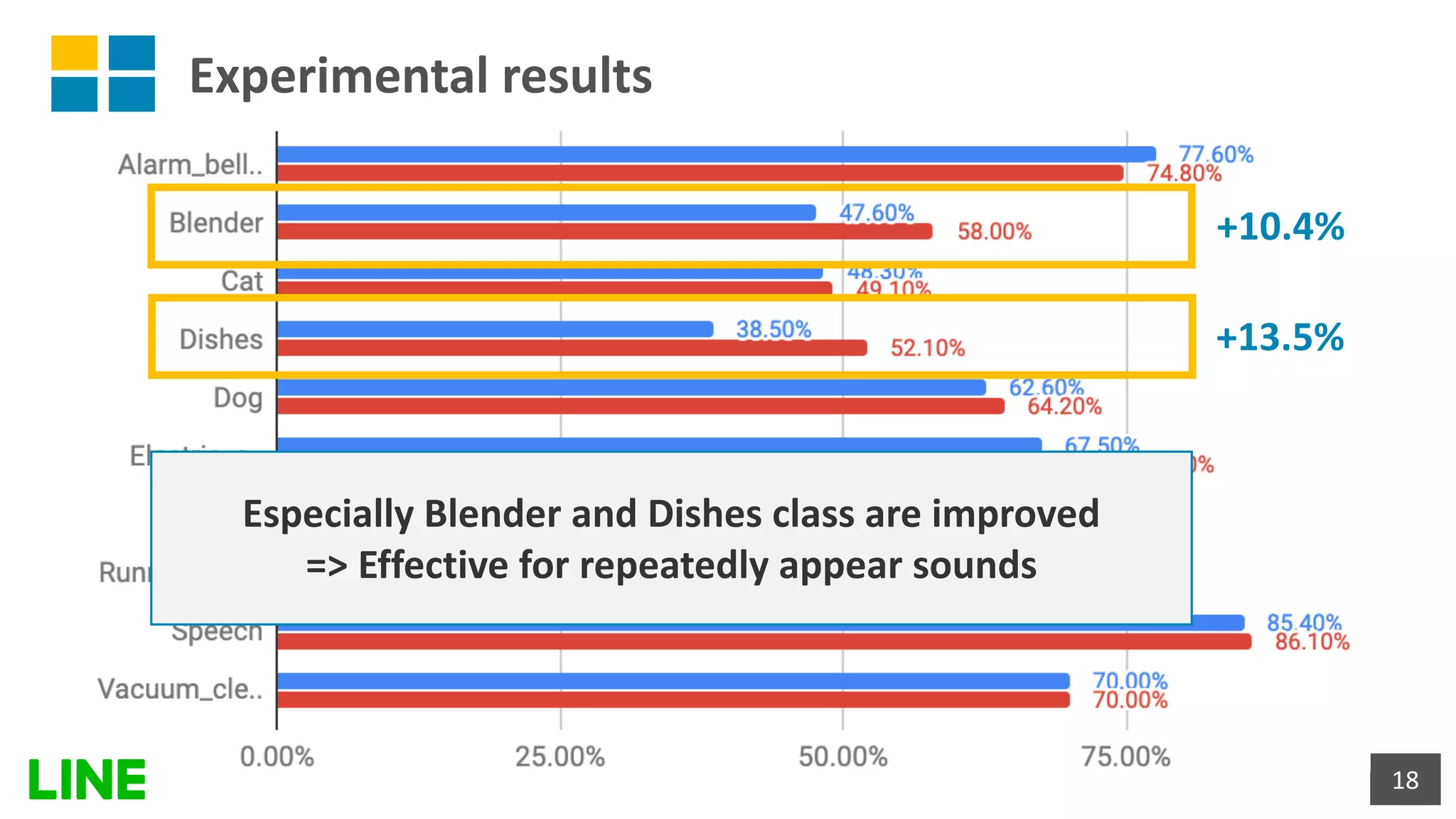
![Experimental results
19
Attention pooling vs. Tag token
Method Encoder stack
Event-
based[%]
Segment-
based[%]
Frame-
based[%]
Self-attention
+ Attention pooling
3 33.99 65.95 62.36
6 33.84 65.61 62.10
Self-attention
+ Tag token
3 34.27 65.07 61.85
6 34.28 64.33 61.26](https://image.slidesharecdn.com/icassp2020slidesmiyazaki-200427005122/75/Weakly-Supervised-Sound-Event-Detection-with-Self-Attention-19-2048.jpg)
![Experimental results
20
Method Encoder stack
Event-
based[%]
Segment-
based[%]
Frame-
based[%]
Self-attention
+ Attention pooling
3 33.99 65.95 62.36
6 33.84 65.61 62.10
Self-attention
+ Tag token
3 34.27 65.07 61.85
6 34.28 64.33 61.26
Perform comparable results
Attention pooling vs. Tag token](https://image.slidesharecdn.com/icassp2020slidesmiyazaki-200427005122/75/Weakly-Supervised-Sound-Event-Detection-with-Self-Attention-20-2048.jpg)
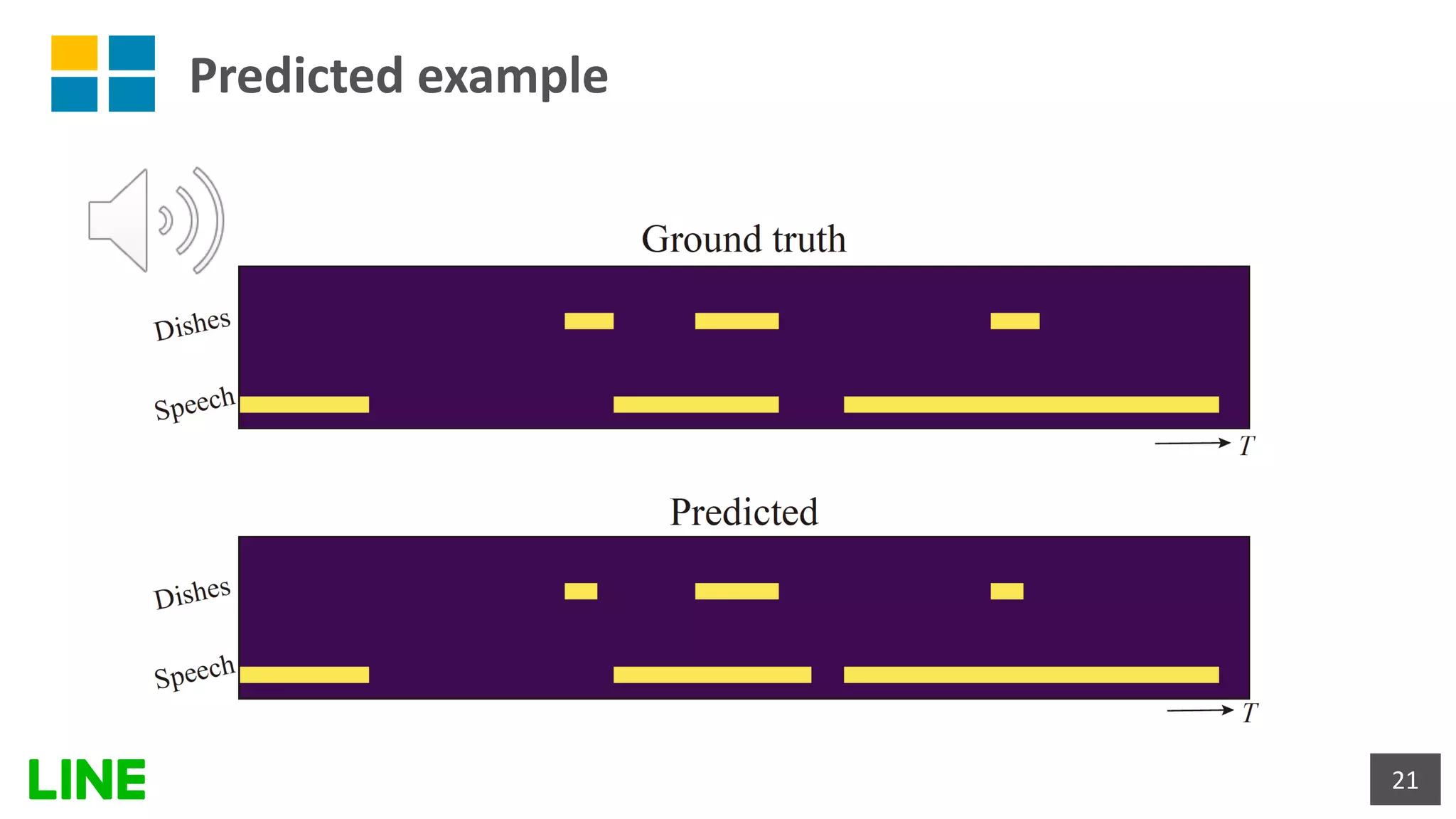
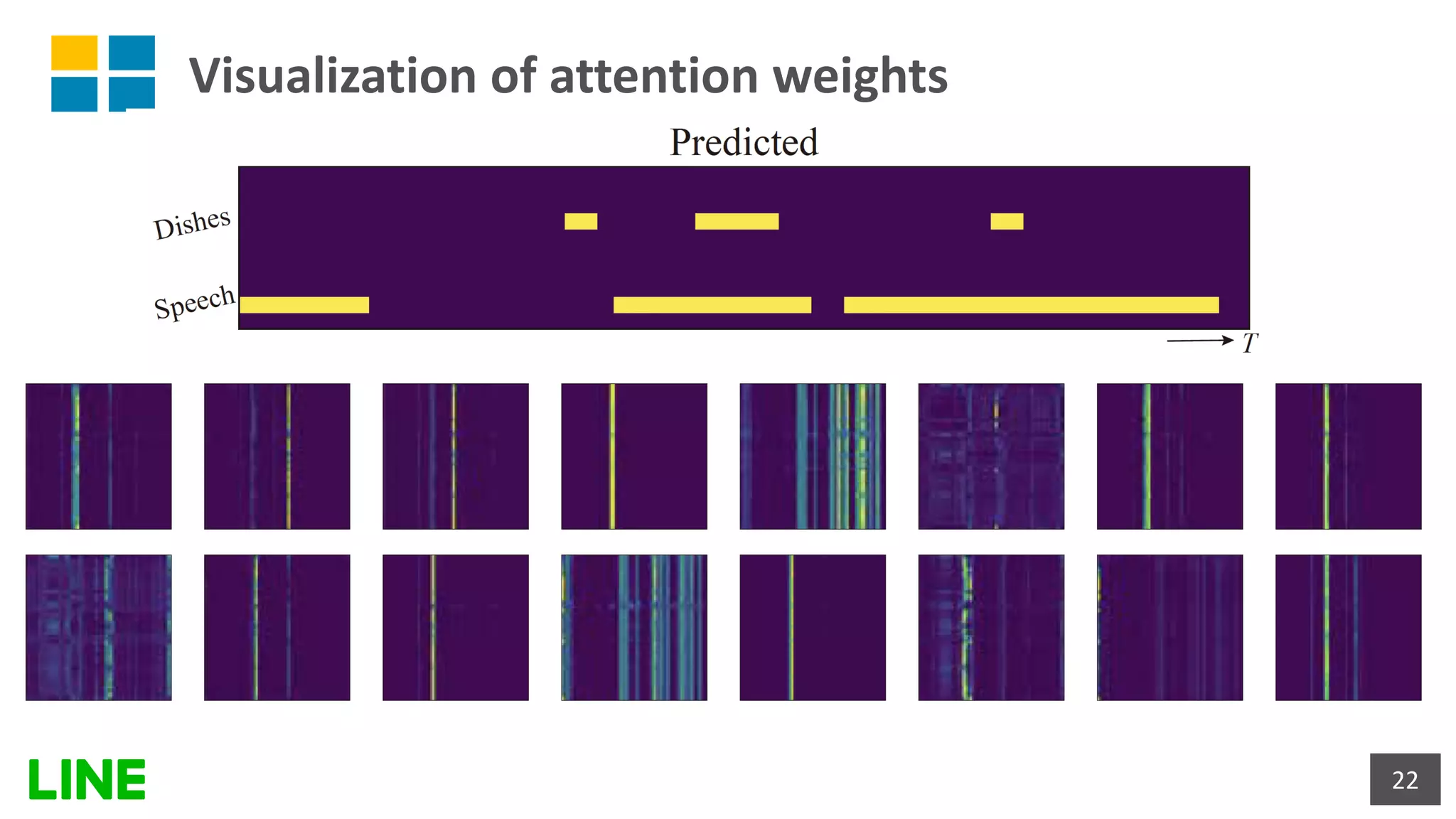


![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)






![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)


















































