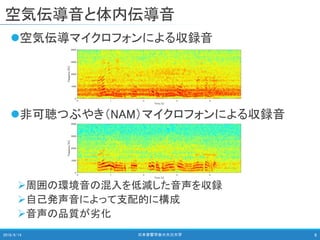
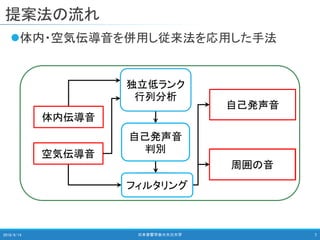
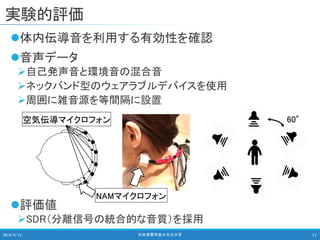
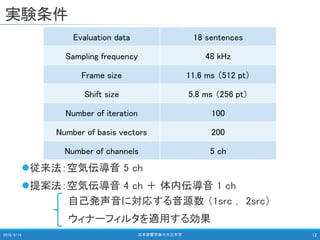
日本音響学会 2018年秋季研究発表会 高田 萌絵,関 翔悟,戸田 智基:空気/体内伝導マイクロフォンを用いた雑音環境下における自己発声音強調/抑圧法,Sep. 2018 名古屋大学 情報学研究科 知能システム学専攻 戸田研究室

![NMF
独立低ランク行列分析 [D. Kitamura+, 2016]
IVAの音源モデルにNMFを導入
線形分離フィルタと各音源の音源モデルを学習
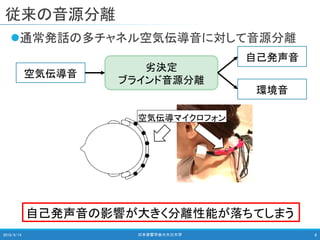
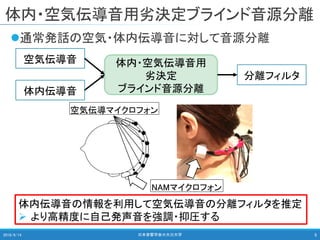
2018/9/14 日本音響学会@大分大学 8
混合信号
自己発声音
環境音
線形分離
フィルタ
時間変動
周
波
数
パ
タ
ー
ン
時間変動
周
波
数
パ
タ
ー
ン
音源モデル
IVA](https://image.slidesharecdn.com/201809asjtakada-181202052206/85/slide-8-320.jpg)
![自己発声音判別
ILRMAにより推定された複数音源を持つ多チャネルの
分離信号を自己発声音と環境音に分ける
体内伝導音に相当するチャネルにおいて信号のパワー
が最大となる信号を自己発声音とする
2018/9/14 日本音響学会@大分大学 9
独
立
低
ラ
ン
ク
行
列
分
析
分離信号
プ
ロ
ジ
ェ
ク
シ
ョ
ン
バ
ッ
ク
[N. Murata+, 2001]
体内伝導 空気伝導1 空気伝導2](https://image.slidesharecdn.com/201809asjtakada-181202052206/85/slide-9-320.jpg)

![実験結果
2018/9/14 日本音響学会@大分大学 13
-1
0
1
2
3
4
5
2src w/ WF 1src w/ WF 1src w/o WF conventional
(1src w/ WF)
conventional
(1src w/o WF)
air- and body-conducted signals air-conducted signals
SDRimprovement[dB]
Speech
Environment](https://image.slidesharecdn.com/201809asjtakada-181202052206/85/slide-13-320.jpg)
















































