Download to read offline

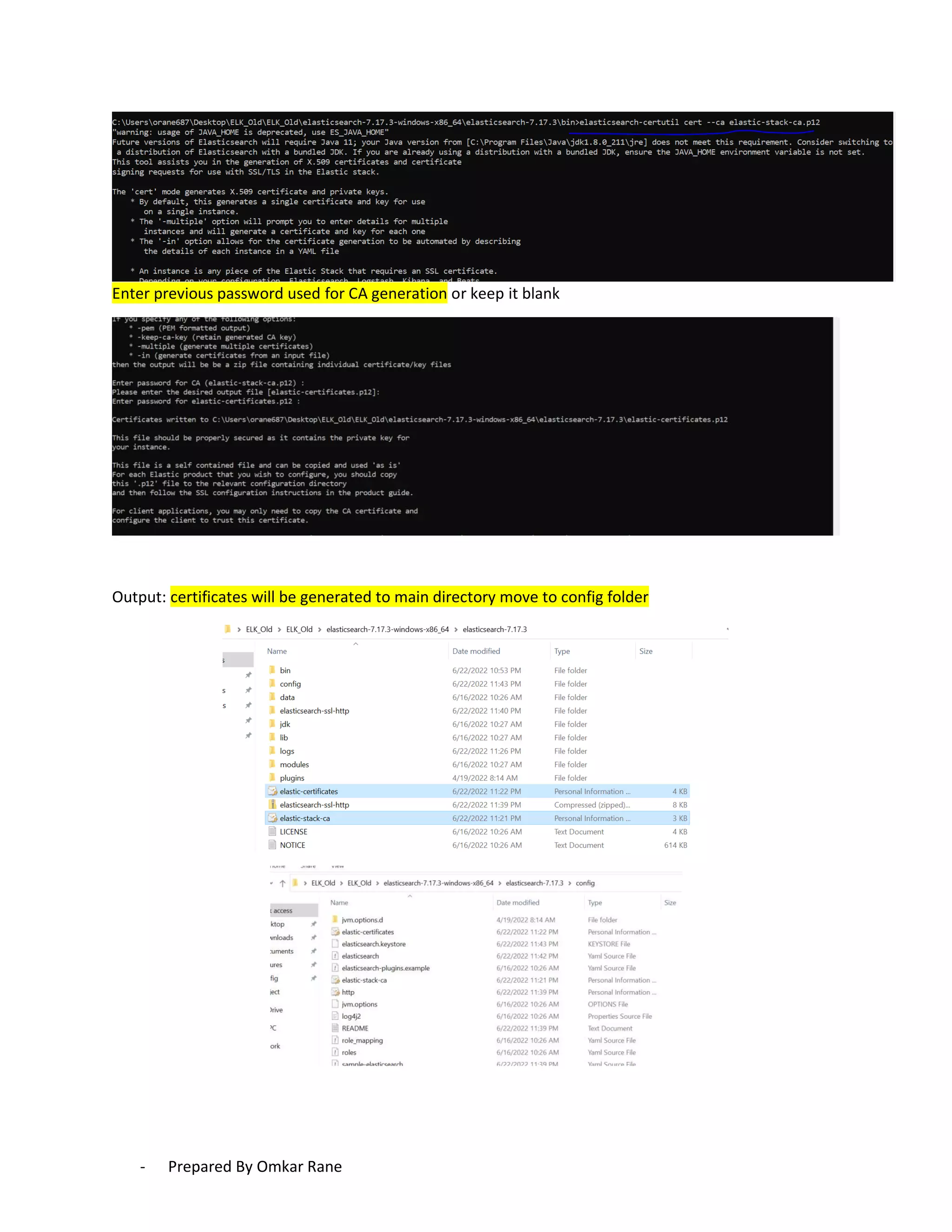
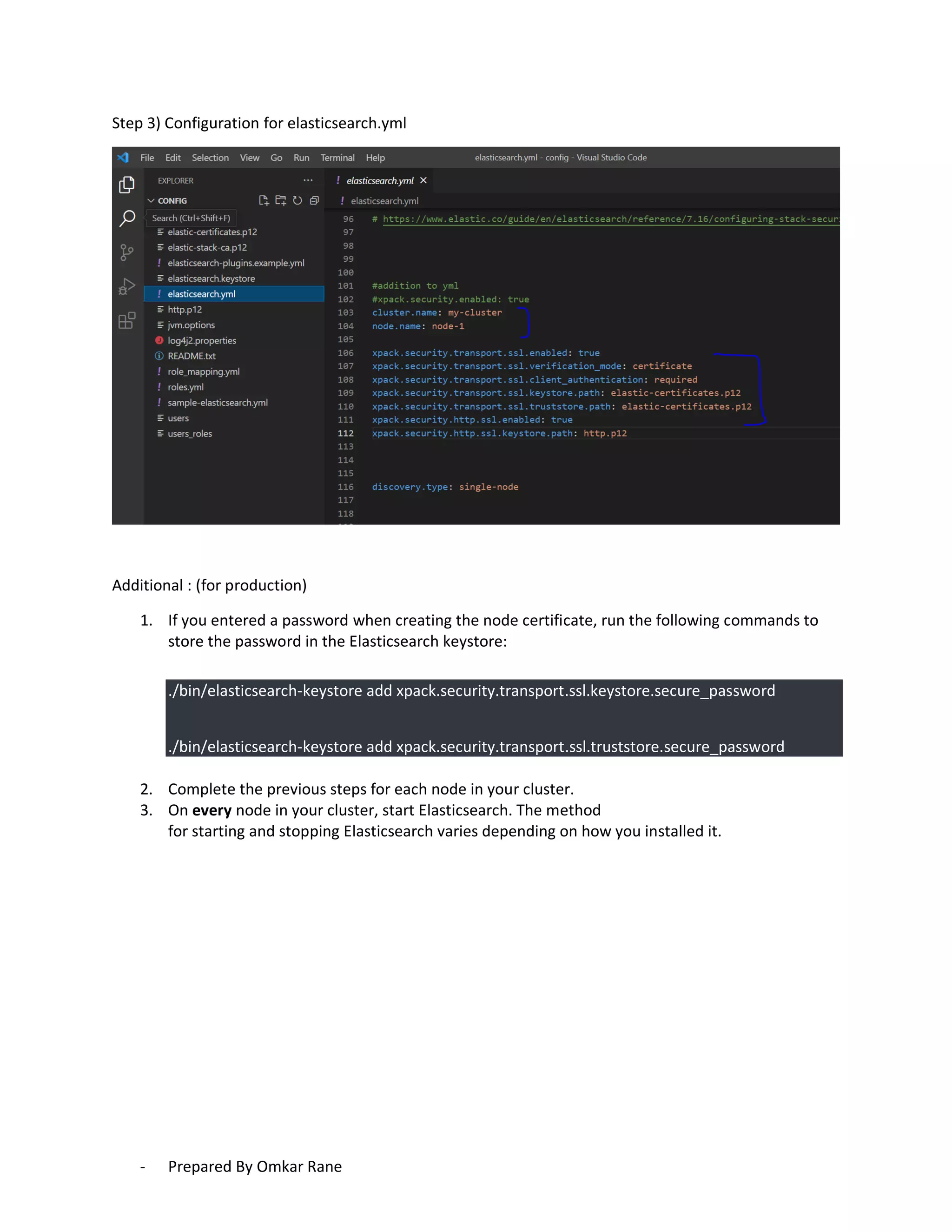


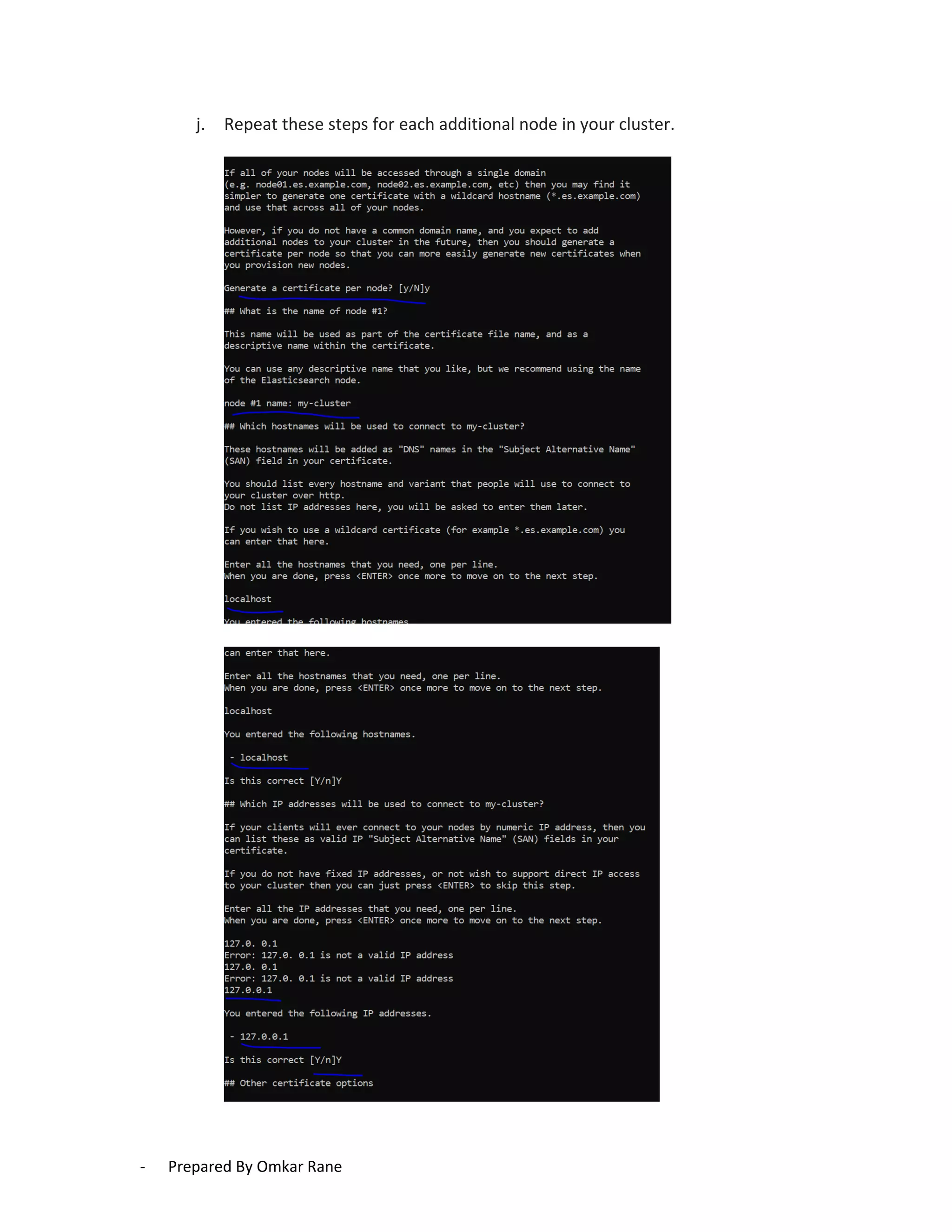
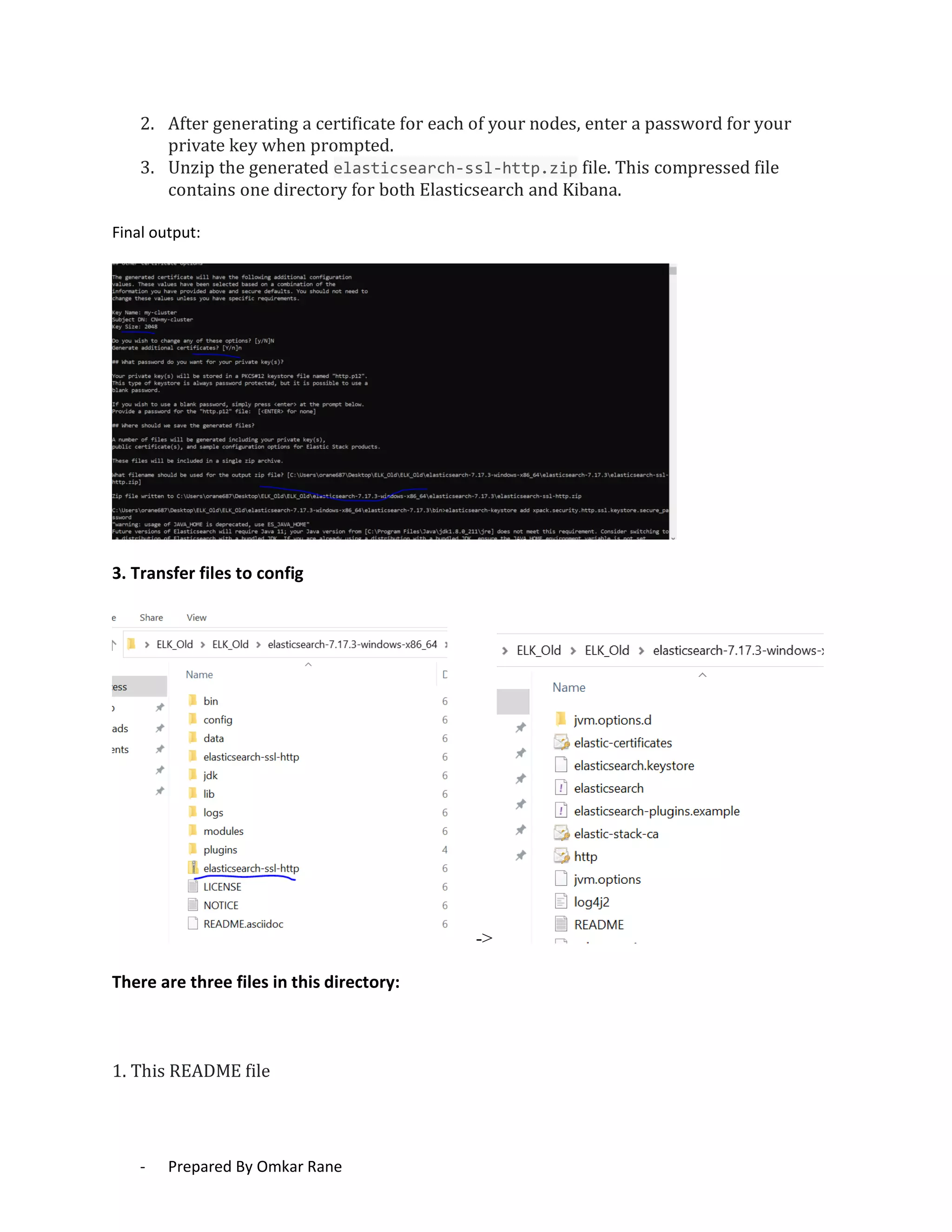
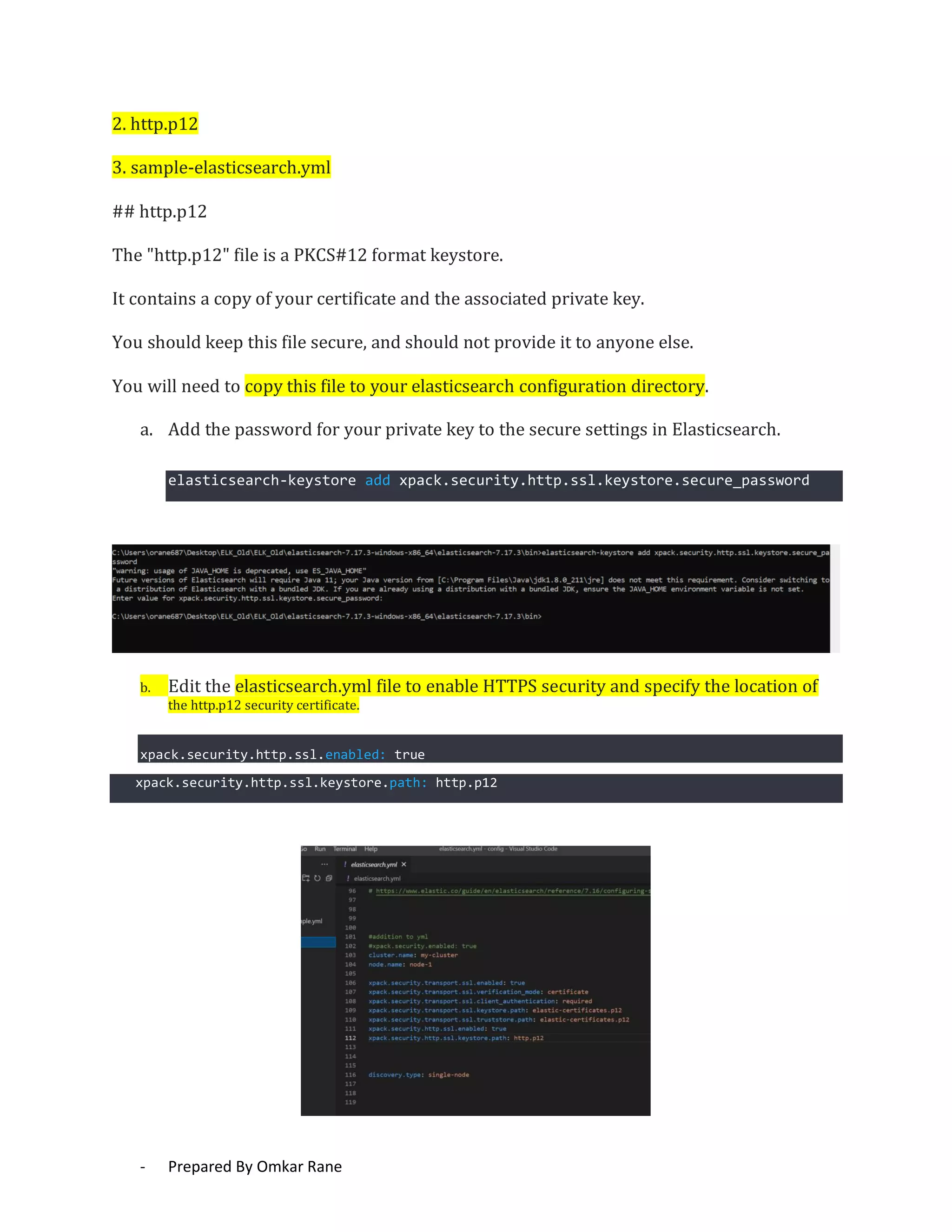
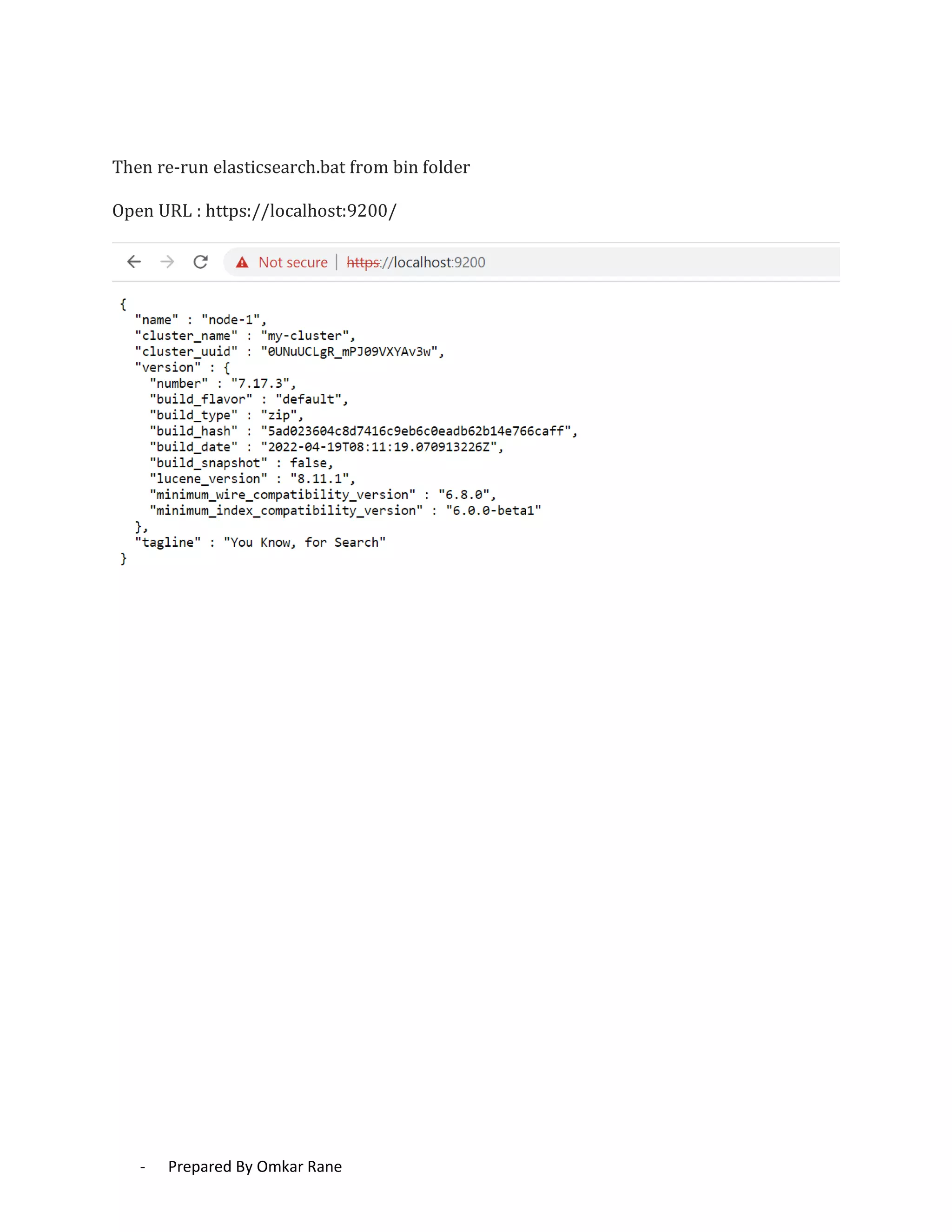

This document provides steps to enable SSL/HTTPS for an Elasticsearch server. It involves generating certificates, configuring Elasticsearch, and enabling TLS for both transport and HTTP layers. The process includes generating a CA certificate, creating node certificates signed by the CA, editing the Elasticsearch configuration file, and restarting Elasticsearch to enable HTTPS.












![Airline Management System [for presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/airlinemanagementsystem-200114162441-thumbnail.jpg?width=640&height=640&fit=bounds)

































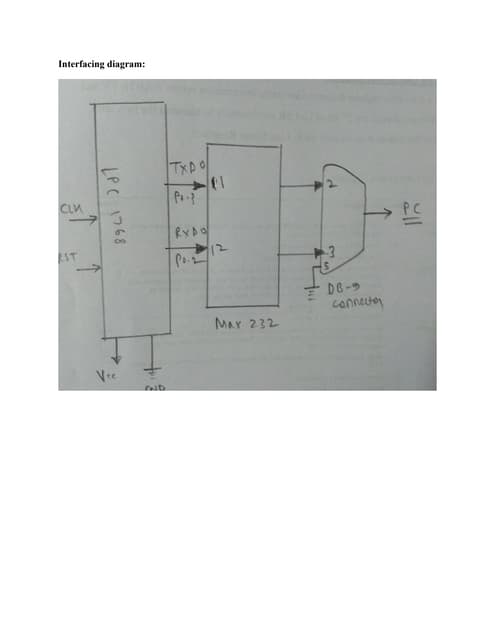

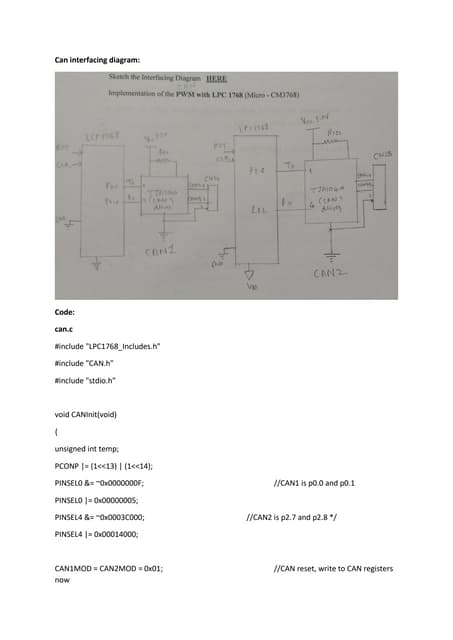















![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

