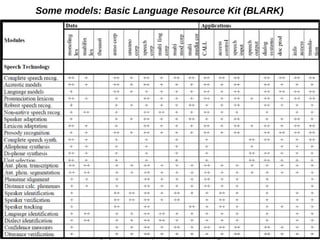
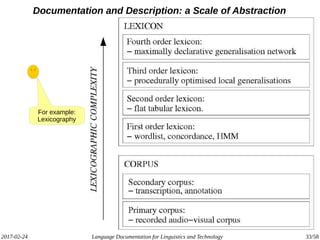
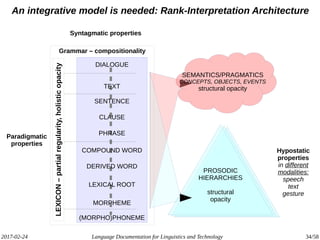
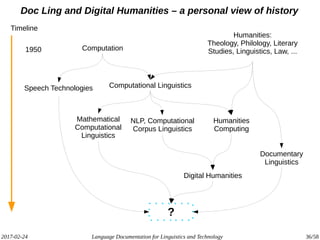
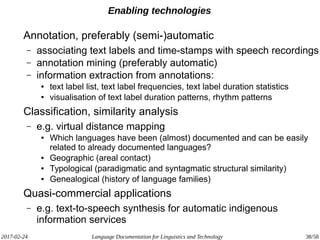
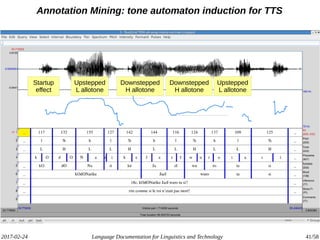
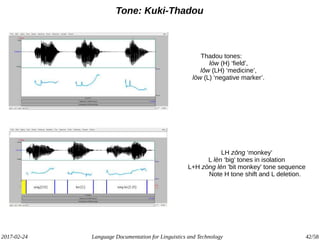
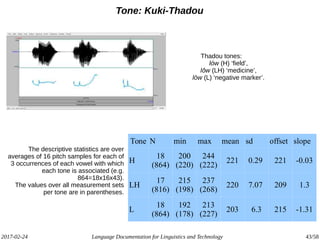
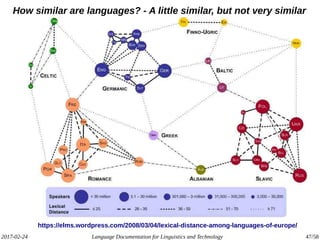
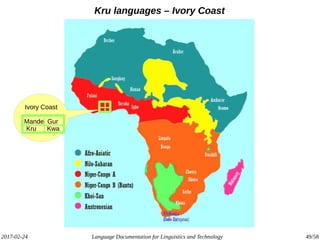
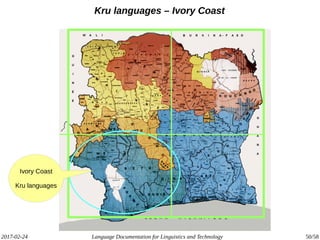
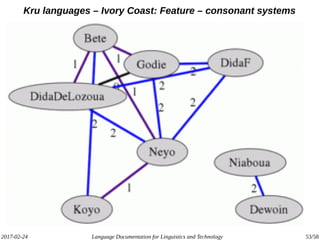
The document discusses the intersection of language documentation and technology, focusing on how endangered and less-resourced languages can inform human language engineering. It outlines various roles of computational technologies in language documentation, including documentation, enabling, and productivity technologies, along with an analysis of tools and methodologies in use. Key concepts include the multidisciplinary nature of language documentation, the necessity for resource richness in language technologies, and the importance of standards and tools for effective documentation and processing.

































































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)








