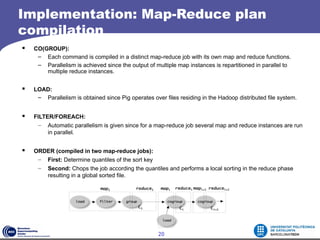
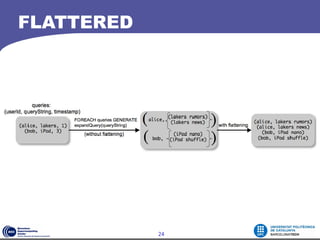
This document contains a homework assignment for a course on execution environments for distributed computing. It discusses Apache Pig, a platform for analyzing large datasets. The document outlines Pig's data model, programming model, and implementation. Key points include Pig Latin's declarative syntax, support for user-defined functions, and ability to automatically parallelize jobs by compiling Pig Latin into MapReduce programs. The conclusions discuss advantages like flexibility and leveraging Hadoop properties, as well as disadvantages like potential performance overhead. Usage scenarios involve temporal and session analysis on datasets like search logs.