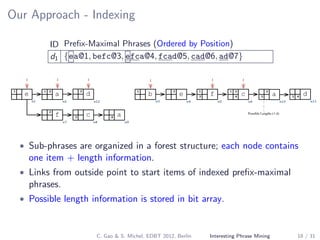
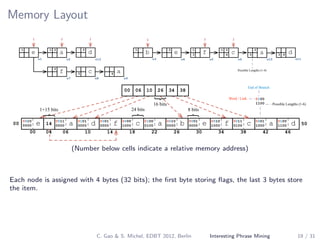
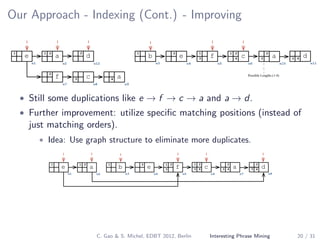
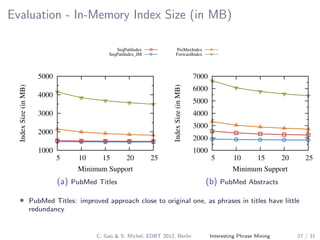
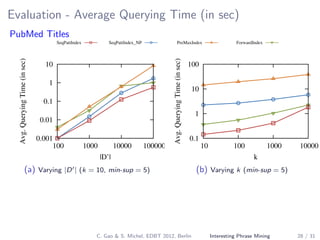
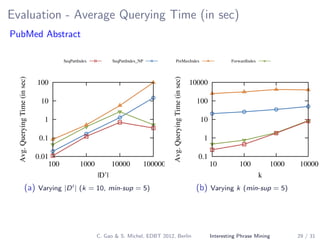
The document describes a method for mining top-k interesting phrases from ad-hoc document collections using sequence pattern indexing. It discusses existing approaches, presents the problem definition, and proposes a new approach that indexes prefix-maximal phrases ordered by position. This indexing structure allows efficient computation of top-k phrases through a merge join process combined with growing phrase patterns, enabled by optimizations like early termination and search space pruning. An evaluation compares the new approach to baseline methods.