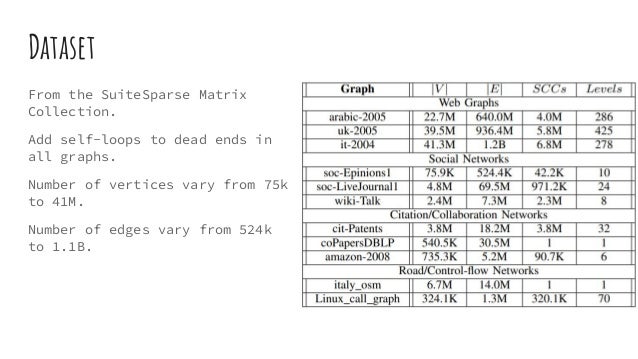
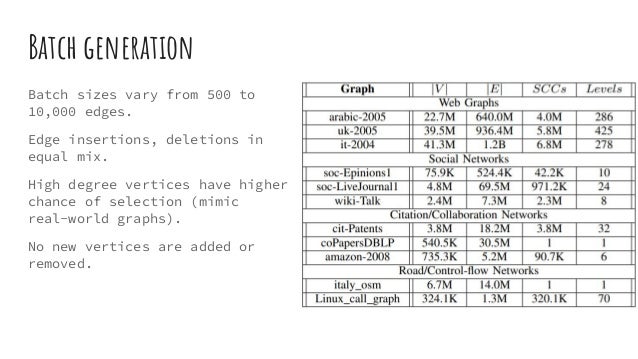
Download as PDF, PPTX









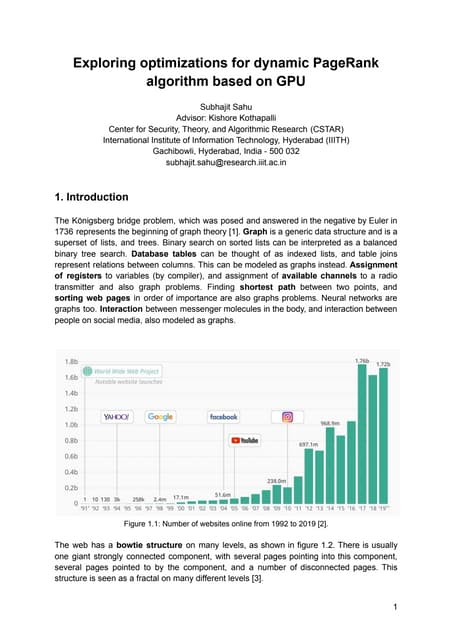
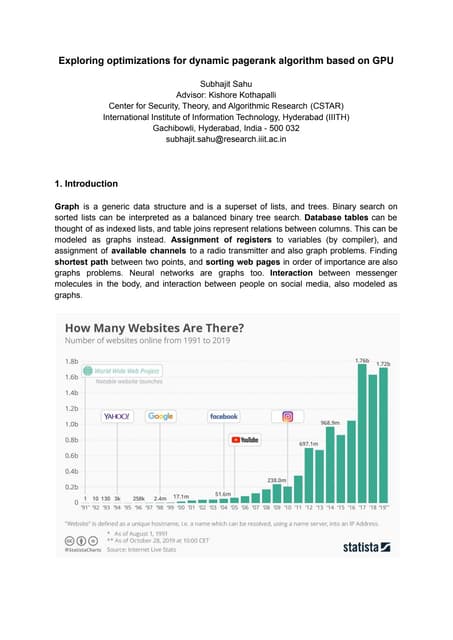
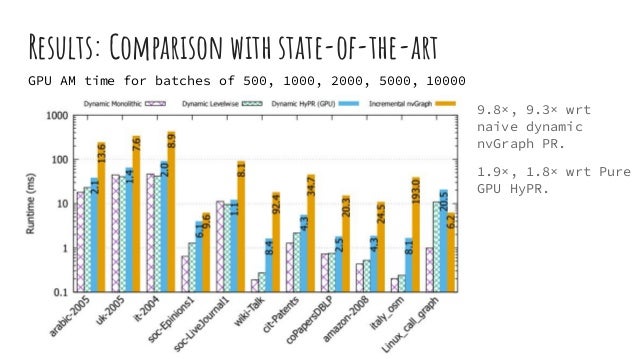
![Results: Comparison with state-of-the-art
CPU AM time for batches of 500, 1000, 2000, 5000, 10000
6.1×, 8.6× wrt
static plain STIC-D
PR [1].
4.2×, 5.8× wrt Pure
CPU HyPR [2].](https://image.slidesharecdn.com/slides-dynamic-batch-parallel-algorithms-for-updating-pagerank-220612051952-baedd2b1/95/Dynamic-Batch-Parallel-Algorithms-for-Updating-Pagerank-SLIDES-22-638.jpg)
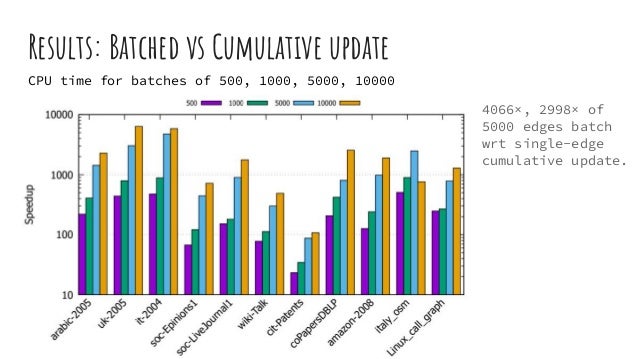
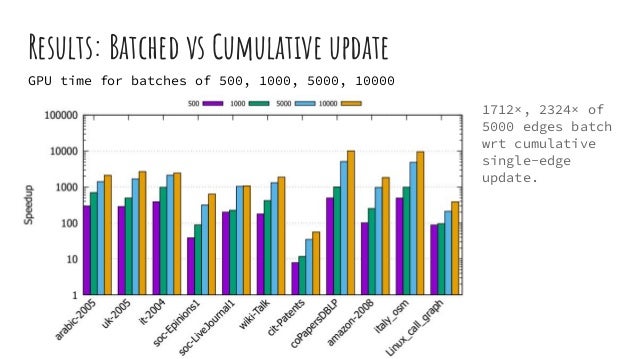


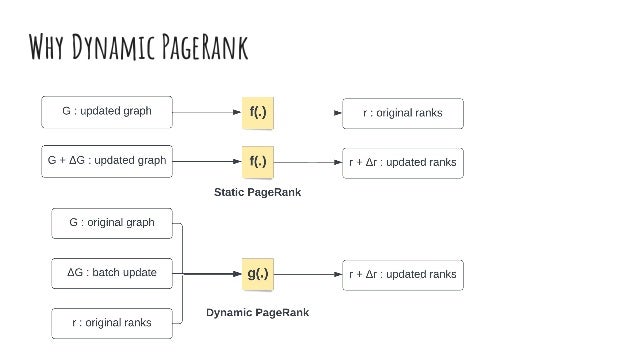
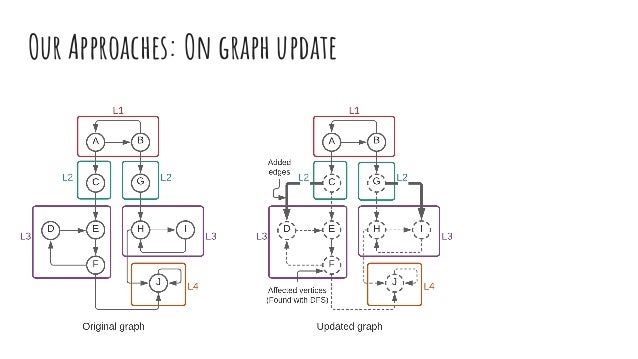
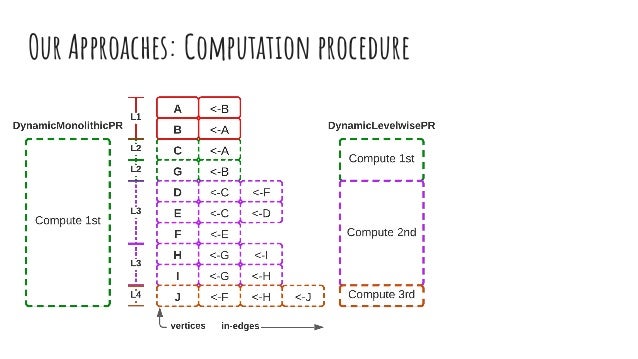
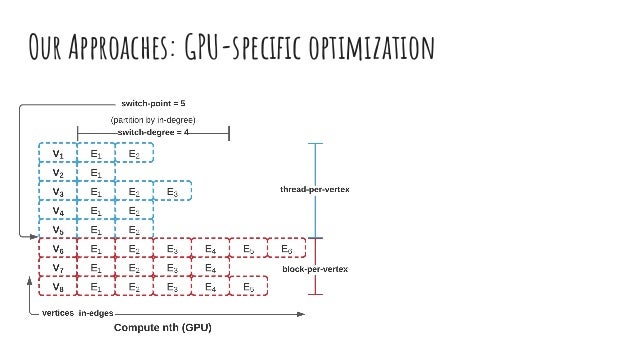
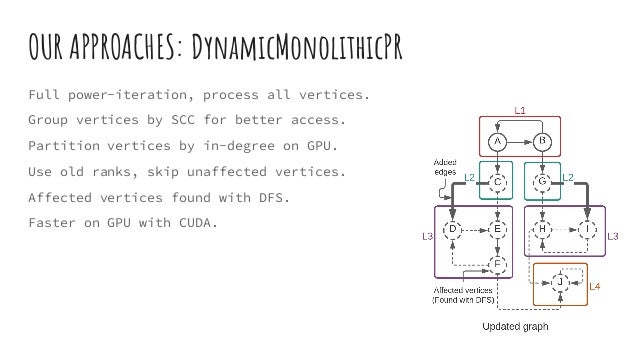
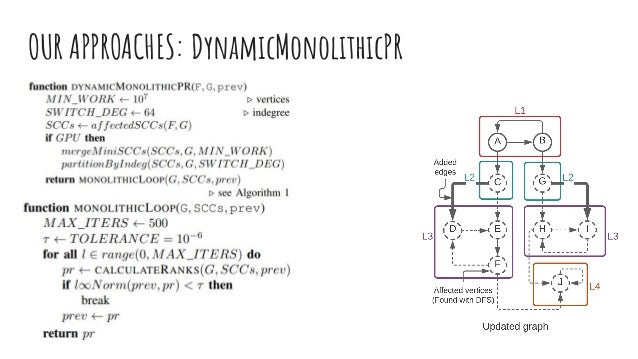
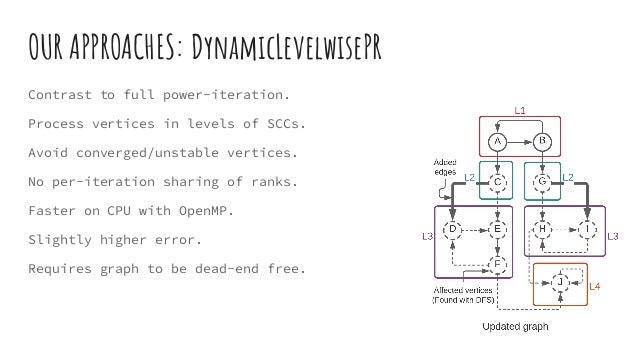
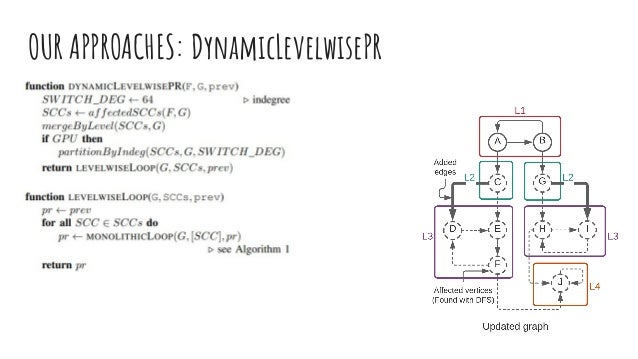
The document discusses dynamic batch parallel algorithms for updating PageRank, highlighting the importance of addressing challenges posed by large and constantly changing graphs. It compares various dynamic algorithms, including incremental, decremental, and fully dynamic types, while emphasizing the benefits of batched fully dynamic algorithms for efficiency. The research presents performance measurements on both CPU and GPU platforms, demonstrating significant improvements over existing state-of-the-art methods.