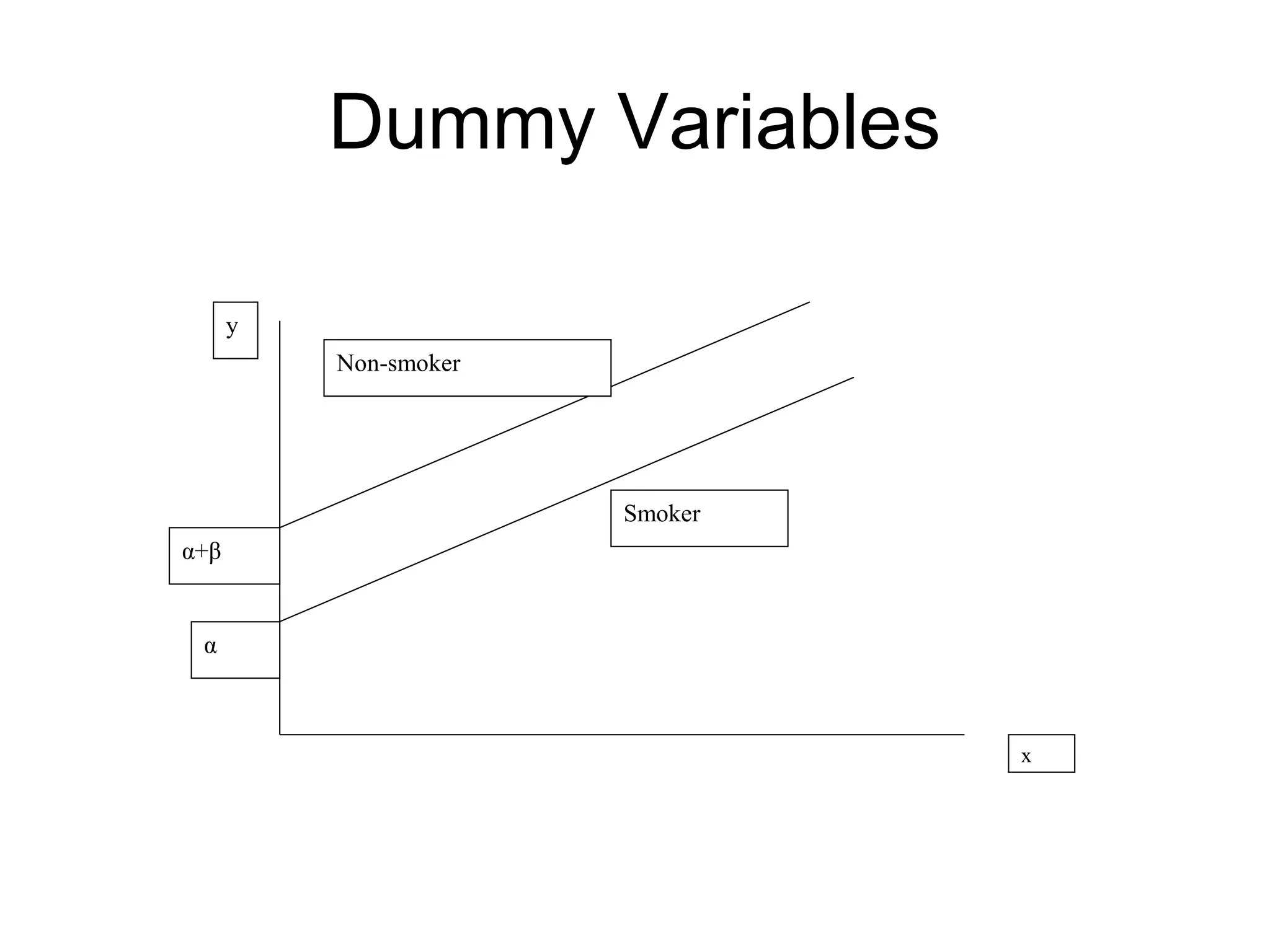
The document discusses the use of dummy variables in financial econometrics, highlighting their role in addressing issues of normality in regression models through techniques such as the Bera-Jarque test. It explains the implications of incorporating dummy variables for outliers and differentiates between different types of dummy variables, including intercept and slope dummies. Additionally, it examines the testing for structural stability using dummy variables to understand changes in regression relationships over time.



![Bera-Jarque Test
• This test for normality in effect tests for the
coefficients of skewness and excess kurtosis
being jointly equal to 0
nsobservatioofnumber
kurtosisexcessoftcoefficien
skewnessoftcoefficien
]
24
)3(
6
[
2
1
2
2
2
1
−
−
−
−
+=
T
b
b
bb
TW](https://image.slidesharecdn.com/dummyvariables-150110020407-conversion-gate01/75/Dummy-variables-xd-4-2048.jpg)