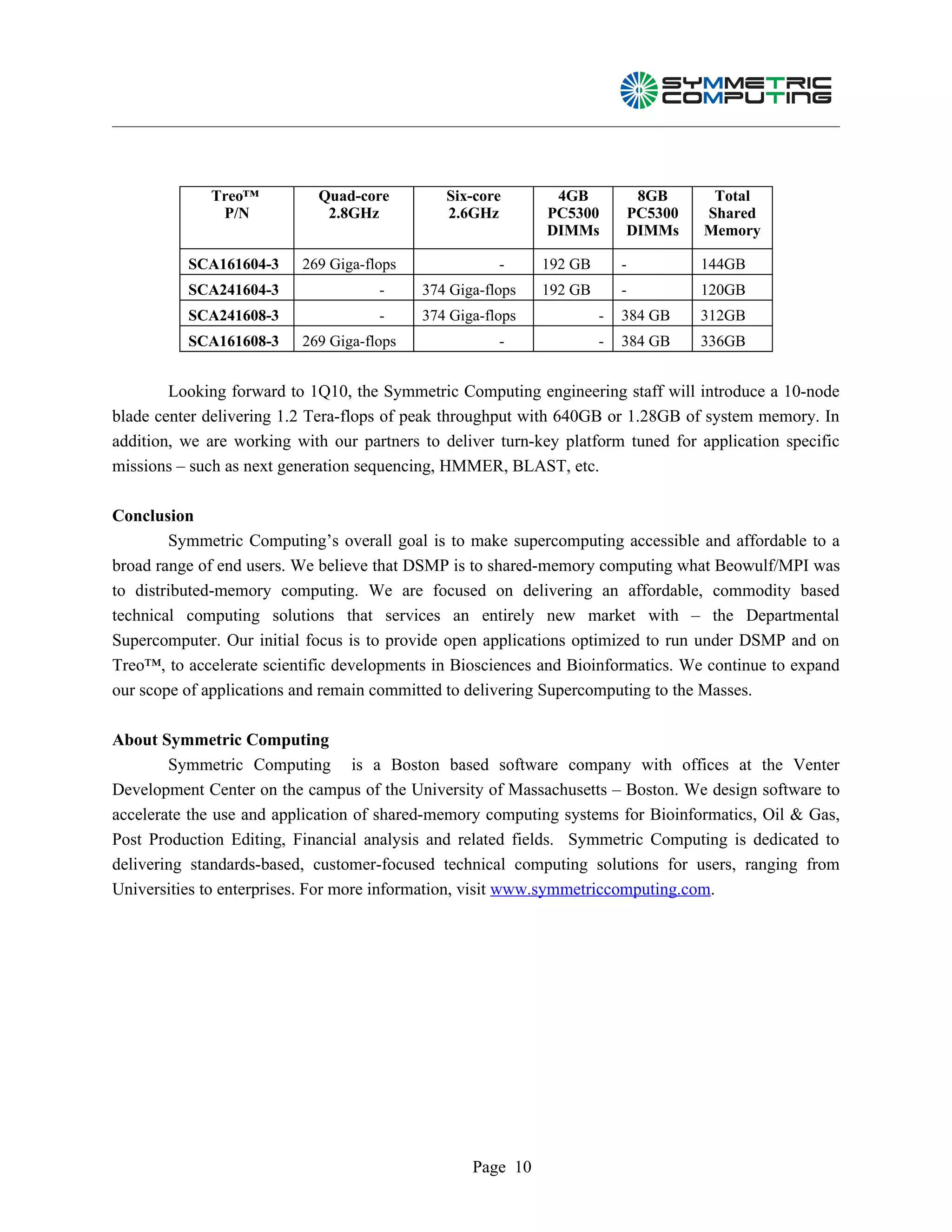
This document provides an overview of the Distributed Symmetric Multiprocessing (DSMP) software architecture. DSMP transforms an InfiniBand connected cluster of commodity servers into a shared memory supercomputer through two unique software components: 1) a host operating system that runs on the head node, and 2) a lightweight microkernel that runs on the other servers. Key aspects of DSMP include a shared memory system, optimized InfiniBand drivers, an application-driven memory page coherency scheme, enhanced multithreading support, and distributed disk storage. DSMP allows commodity clusters to provide shared memory capabilities at a lower cost than proprietary supercomputers.























































![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








