This document is written about "Data-Intensive Text Processing with MapReduce" Chapter 4.
This chapter describes how to design inverted index with MapReduce algorithm.
Data-Intensive Text Processing
with MapReduce
(Ch4 Inverted Indexing for Text Retrieval)
2010/10/03
shiumachi
http://d.hatena.ne.jp/shiumachi/
http://twitter.com/shiumachi
big data における検索
● リアルタイム処理が要求されるので
MapReduceはどの道無理
● 以下MapReduce全く出てこない……
● でも分散させるのは一緒
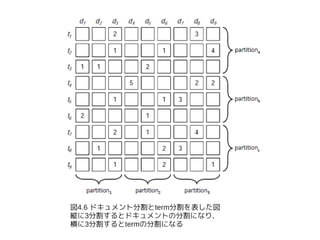
● 分散の方法は2つ
● ドキュメントを分割し、それぞれのサーバで全ての
term を持つ
● term を分割し、それぞれのサーバで全てのドキュ
メントを持つ




























![Simple-9のフラグ [4]
上位bit 符号の個数 符号のビット長
0000 28 1
0001 14 2
0010 9 3
0011 7 4
0100 5 5
0101 4 7
0110 3 9
0111 2 14
1000 1 28
最適化するにはDPを使う必要がある
が、tsubosakaさんによると0.2%ほどしか圧縮率
が改善しなかったため実用的ではないらしい [4]](https://image.slidesharecdn.com/mapreduce1010032-101010020737-phpapp02/85/Data-Intensive-Text-Processing-with-MapReduce-ch4-31-320.jpg)