Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
弘毅 露崎
10,272 views
RとSQLiteで気軽にデータベース作成
Read more
14
Save
Share
Embed
Embed presentation
Download
Downloaded 62 times
1
/ 19
2
/ 19
Most read
3
/ 19
4
/ 19
Most read
5
/ 19
6
/ 19
7
/ 19
8
/ 19
Most read
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PPTX
Rによる高速処理 まだfor使ってるの?
by
jundoll
PPTX
Rでのtry関数によるエラー処理
by
wada, kazumi
PDF
質的変数の相関・因子分析
by
Mitsuo Shimohata
PDF
RのffでGLMしてみたけど...
by
Kazuya Wada
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
PDF
03 「重回帰分析」の入門
by
Shuhei Ichikawa
PDF
機械学習と主成分分析
by
Katsuhiro Morishita
Rによる高速処理 まだfor使ってるの?
by
jundoll
Rでのtry関数によるエラー処理
by
wada, kazumi
質的変数の相関・因子分析
by
Mitsuo Shimohata
RのffでGLMしてみたけど...
by
Kazuya Wada
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
03 「重回帰分析」の入門
by
Shuhei Ichikawa
機械学習と主成分分析
by
Katsuhiro Morishita
What's hot
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
セミパラメトリック推論の基礎
by
Daisuke Yoneoka
PPTX
第五回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
多重代入法の書き方 公開用
by
Koichiro Gibo
PPTX
心理学のためのPsychパッケージ
by
考司 小杉
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PPTX
R seminar on igraph
by
Kazuhiro Takemoto
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
はじめての「R」
by
Masahiro Hayashi
PDF
媒介分析について
by
Hiroshi Shimizu
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PPTX
ベイズモデリングで見る因子分析
by
Shushi Namba
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
多変量解析の一般化
by
Akisato Kimura
PDF
探索と活用の戦略 ベイズ最適化と多腕バンディット
by
H Okazaki
PDF
ggplot2をつかってみよう
by
Hiroki Itô
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
PDF
漸近理論をスライド1枚で(フォローアッププログラムクラス講義07132016)
by
Hideo Hirose
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
セミパラメトリック推論の基礎
by
Daisuke Yoneoka
第五回統計学勉強会@東大駒場
by
Daisuke Yoneoka
多重代入法の書き方 公開用
by
Koichiro Gibo
心理学のためのPsychパッケージ
by
考司 小杉
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
R seminar on igraph
by
Kazuhiro Takemoto
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
はじめての「R」
by
Masahiro Hayashi
媒介分析について
by
Hiroshi Shimizu
階層ベイズとWAIC
by
Hiroshi Shimizu
ベイズモデリングで見る因子分析
by
Shushi Namba
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
多変量解析の一般化
by
Akisato Kimura
探索と活用の戦略 ベイズ最適化と多腕バンディット
by
H Okazaki
ggplot2をつかってみよう
by
Hiroki Itô
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
漸近理論をスライド1枚で(フォローアッププログラムクラス講義07132016)
by
Hideo Hirose
Similar to RとSQLiteで気軽にデータベース作成
PDF
RとSQLiteによるオミックス解析の促進
by
弘毅 露崎
KEY
データベースのお話
by
Hidekazu Tanaka
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
PDF
社会ネットワーク分析第7回
by
Satoru Mikami
PDF
tcpdump & xtrabackup @ MySQL Casual Talks #1
by
Ryosuke IWANAGA
PDF
Japan.r 2データベース
by
sleipnir002
PPTX
Python による 「スクレイピング & 自然言語処理」入門
by
Tatsuya Tojima
PPTX
データベース入門
by
拓 小林
PDF
NoSQLとビックデータ入門編Update版
by
Koichiro Nishijima
PDF
RDBを中核としたXMLDBの開発
by
Hiroyuki Inoue
PDF
Elasticsearch入門 pyfes 201207
by
Jun Ohtani
PDF
TAM 新人ディレクター システムスキルアップ プログラム 第6回 「データベース」
by
(株)TAM
PDF
Perl暦およそ10年(?)の僕がデータベースを使えるようになるまでの昔話
by
azuma satoshi
PDF
経済学のための実践的データ分析 4.SQL ことはじめ
by
Yasushi Hara
PDF
[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門
by
Koichi Hamada
PDF
Mongodb 紹介
by
Ryo Matsumura
PDF
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
PPTX
2024年度_サイバーエージェント_新卒研修「データベースの歴史」.pptx
by
yassun7010
PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識
by
Katsuhiro Morishita
PDF
Spider DeNA Technology Seminar #2
by
Kentoku
RとSQLiteによるオミックス解析の促進
by
弘毅 露崎
データベースのお話
by
Hidekazu Tanaka
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
社会ネットワーク分析第7回
by
Satoru Mikami
tcpdump & xtrabackup @ MySQL Casual Talks #1
by
Ryosuke IWANAGA
Japan.r 2データベース
by
sleipnir002
Python による 「スクレイピング & 自然言語処理」入門
by
Tatsuya Tojima
データベース入門
by
拓 小林
NoSQLとビックデータ入門編Update版
by
Koichiro Nishijima
RDBを中核としたXMLDBの開発
by
Hiroyuki Inoue
Elasticsearch入門 pyfes 201207
by
Jun Ohtani
TAM 新人ディレクター システムスキルアップ プログラム 第6回 「データベース」
by
(株)TAM
Perl暦およそ10年(?)の僕がデータベースを使えるようになるまでの昔話
by
azuma satoshi
経済学のための実践的データ分析 4.SQL ことはじめ
by
Yasushi Hara
[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門
by
Koichi Hamada
Mongodb 紹介
by
Ryo Matsumura
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
2024年度_サイバーエージェント_新卒研修「データベースの歴史」.pptx
by
yassun7010
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識
by
Katsuhiro Morishita
Spider DeNA Technology Seminar #2
by
Kentoku
More from 弘毅 露崎
PDF
大規模テンソルデータに適用可能なeinsumの開発
by
弘毅 露崎
PDF
バイオインフォ分野におけるtidyなデータ解析の最新動向
by
弘毅 露崎
PDF
Benchmarking principal component analysis for large-scale single-cell RNA-seq...
by
弘毅 露崎
PDF
R-4.0の解説
by
弘毅 露崎
PDF
scTGIFの鬼QC機能の追加
by
弘毅 露崎
PDF
20191204 mbsj2019
by
弘毅 露崎
PDF
1細胞オミックスのための新GSEA手法
by
弘毅 露崎
PDF
Predicting drug-induced transcriptome responses of a wide range of human cell...
by
弘毅 露崎
PDF
LRBase × scTensorで細胞間コミュニケーションの検出
by
弘毅 露崎
PDF
非負値テンソル分解を用いた細胞間コミュニケーション検出
by
弘毅 露崎
PDF
Exploring the phenotypic consequences of tissue specific gene expression vari...
by
弘毅 露崎
PDF
データベースとデータ解析の融合
by
弘毅 露崎
PDF
ビール砲の放ち方
by
弘毅 露崎
PDF
Identification of associations between genotypes and longitudinal phenotypes ...
by
弘毅 露崎
PDF
A novel method for discovering local spatial clusters of genomic regions with...
by
弘毅 露崎
PDF
Rによる統計解析と可視化
by
弘毅 露崎
PDF
文献注釈情報MeSHを利用した網羅的な遺伝子の機能アノテーションパッケージ
by
弘毅 露崎
PDF
PCAの最終形態GPLVMの解説
by
弘毅 露崎
PDF
カーネル法を利用した異常波形検知
by
弘毅 露崎
PDF
ISMB読み会 2nd graph kernel
by
弘毅 露崎
大規模テンソルデータに適用可能なeinsumの開発
by
弘毅 露崎
バイオインフォ分野におけるtidyなデータ解析の最新動向
by
弘毅 露崎
Benchmarking principal component analysis for large-scale single-cell RNA-seq...
by
弘毅 露崎
R-4.0の解説
by
弘毅 露崎
scTGIFの鬼QC機能の追加
by
弘毅 露崎
20191204 mbsj2019
by
弘毅 露崎
1細胞オミックスのための新GSEA手法
by
弘毅 露崎
Predicting drug-induced transcriptome responses of a wide range of human cell...
by
弘毅 露崎
LRBase × scTensorで細胞間コミュニケーションの検出
by
弘毅 露崎
非負値テンソル分解を用いた細胞間コミュニケーション検出
by
弘毅 露崎
Exploring the phenotypic consequences of tissue specific gene expression vari...
by
弘毅 露崎
データベースとデータ解析の融合
by
弘毅 露崎
ビール砲の放ち方
by
弘毅 露崎
Identification of associations between genotypes and longitudinal phenotypes ...
by
弘毅 露崎
A novel method for discovering local spatial clusters of genomic regions with...
by
弘毅 露崎
Rによる統計解析と可視化
by
弘毅 露崎
文献注釈情報MeSHを利用した網羅的な遺伝子の機能アノテーションパッケージ
by
弘毅 露崎
PCAの最終形態GPLVMの解説
by
弘毅 露崎
カーネル法を利用した異常波形検知
by
弘毅 露崎
ISMB読み会 2nd graph kernel
by
弘毅 露崎
RとSQLiteで気軽にデータベース作成
1.
RとSQLiteで気軽に データベース作成 antiplastics@Kashiwa.R#4
2012/9/28
2.
テーブルデータの限界
4.39GBのデータを read.table() webから取得した シロイヌナズナの 遺伝子発現データ 堅気の人はまず見る事が無いエラーメッセージ
3.
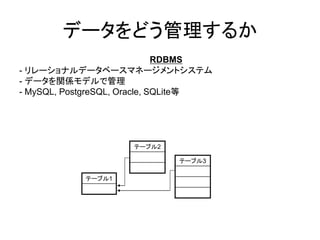
データをどう管理するか
RDBMS - リレーショナルデータベースマネージメントシステム - データを関係モデルで管理 - MySQL, PostgreSQL, Oracle, SQLite等 テーブル2 テーブル3 テーブル1
4.
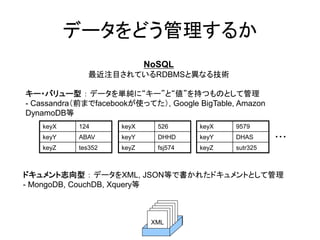
データをどう管理するか
NoSQL 最近注目されているRDBMSと異なる技術 キー・バリュー型 : データを単純に“キー”と“値”を持つものとして管理 - Cassandra(前までfacebookが使ってた), Google BigTable, Amazon DynamoDB等 keyX 124 keyX 526 keyX 9579 keyY ABAV keyY DHHD keyY DHAS ・・・ keyZ tes352 keyZ fsj574 keyZ sutr325 ドキュメント志向型 : データをXML, JSON等で書かれたドキュメントとして管理 - MongoDB, CouchDB, Xquery等 XML XML XML XML XML
5.
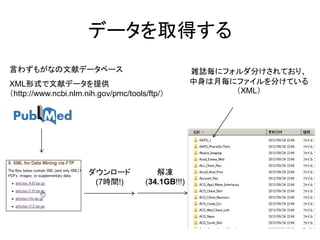
データを取得する 言わずもがなの文献データベース
雑誌毎にフォルダ分けされており、 XML形式で文献データを提供 中身は月毎にファイルを分けている (http://www.ncbi.nlm.nih.gov/pmc/tools/ftp/) (XML) ダウンロード 解凍 (7時間!) (34.1GB!!!)
6.
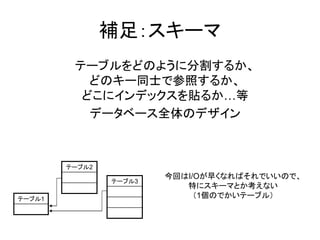
補足:スキーマ
テーブルをどのように分割するか、 どのキー同士で参照するか、 どこにインデックスを貼るか…等 データベース全体のデザイン テーブル2 今回はI/Oが早くなればそれでいいので、 テーブル3 特にスキーマとか考えない テーブル1 (1個のでかいテーブル)
7.
補足:スキーマ ゲノムデータベースEnsemblのスキーマ
あまりにアレだからBiomartがもっと簡単に データを取得できるようにしている
8.
補足:SQLite
RDBMSの一種で、サーバーvsクライアントという概念が無い SQLの文法はMySQLとかと大体は同じ → 個人で気軽にローカルのデータベースを構築するのに最適 隠しファイル Macだと Macだと /Users/ユーザー名/Library/Application /Users/ユーザー名/Library/Application Macだと Support/Firefox/Profiles/307dewum.default/ Support/Skype/アカウント名/ /Users/ユーザー名/.dropbox 他にもあらゆるアプリケーションが利用 (http://www.sqlite.org/famous.html)
9.
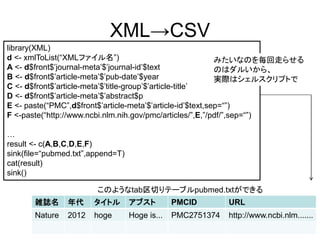
XML→CSV library(XML) d <- xmlToList(“XMLファイル名”)
みたいなのを毎回走らせる A <- d$front$’journal-meta’$’journal-id’$text のはダルいから、 B <- d$front$’article-meta’$’pub-date’$year 実際はシェルスクリプトで C <- d$front$’article-meta’$’title-group’$’article-title’ D <- d$front$’article-meta’$’abstract$p E <- paste(“PMC”,d$front$’article-meta’$’article-id’$text,sep=“”) F <-paste(“http://www.ncbi.nlm.nih.gov/pmc/articles/”,E,”/pdf/”,sep=“”) … result <- c(A,B,C,D,E,F) sink(file=“pubmed.txt”,append=T) cat(result) sink() このようなtab区切りテーブルpubmed.txtができる 雑誌名 年代 タイトル アブスト (???GB) PMCID URL Nature 2012 hoge Hoge is... PMC2751374 http://www.ncbi.nlm.......
10.
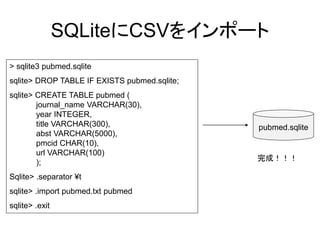
SQLiteにCSVをインポート > sqlite3 pubmed.sqlite sqlite>
DROP TABLE IF EXISTS pubmed.sqlite; sqlite> CREATE TABLE pubmed ( journal_name VARCHAR(30), year INTEGER, title VARCHAR(300), pubmed.sqlite abst VARCHAR(5000), pmcid CHAR(10), url VARCHAR(100) 完成!!! ); Sqlite> .separator ¥t sqlite> .import pubmed.txt pubmed sqlite> .exit
11.
RSQLite
RでSQLiteを操作できるパッケージ Rでコマンドを叩いても、実際は裏でSQLが走る SQLがデータをとってきても、返ってくるのはRオブジェクト SQL文 例: SELECT * FROM pubmed; pubmed.sqlite Rオブジェクト (データフレーム) DBI(データベースインターフェース)という 他の言語でも実装されている 例: PerlのDBD::Pg、JavaのJDBI、Rubyのruby-dbi
12.
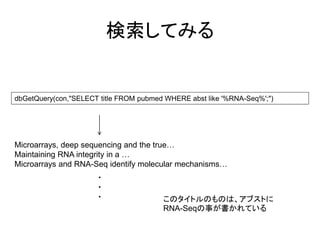
検索してみる dbGetQuery(con,"SELECT title FROM
pubmed WHERE abst like '%RNA-Seq%';") Microarrays, deep sequencing and the true… Maintaining RNA integrity in a … Microarrays and RNA-Seq identify molecular mechanisms… ・ ・ ・ このタイトルのものは、アブストに RNA-Seqの事が書かれている
13.
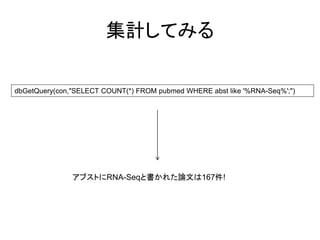
集計してみる dbGetQuery(con,"SELECT COUNT(*) FROM
pubmed WHERE abst like '%RNA-Seq%';") アブストにRNA-Seqと書かれた論文は167件!
14.
可視化 paper <- rep(0:0,length=85) for(i
in 1928:2012){ command <- paste("SELECT COUNT(*) FROM pubmed WHERE abst like '%RNA-Seq%' AND year = ",i,";",sep="") prepaper <- dbGetQuery(con,command) if(as.numeric(prepaper)!=0){ paper[i-1928] <- as.numeric(prepaper) } } jpeg(file="paper.jpeg") plot(1928:2012,paper,"l",ylab="Frequency",xlab="Year") dev.off() 論文の本数が2000年後半あたりにい きなり急増している!
15.
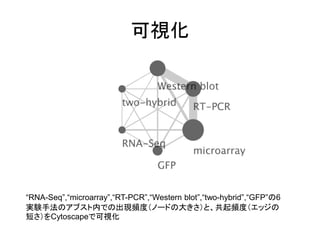
可視化 “RNA-Seq”,“microarray”,“RT-PCR”,“Western blot”,“two-hybrid”,“GFP”の6 実験手法のアブスト内での出現頻度(ノードの大きさ)と、共起頻度(エッジの 短さ)をCytoscapeで可視化
16.
pdf根こそぎダウンロード keyword
<- "RNA-Seq" url <- as.matrix(dbGetQuery(con,paste("SELECT url FROM pubmed WHERE abst like '%",keyword,"%';",sep=""))) url <- sub(" ","",url) d <- getwd() dir.create(paste(d,"/",keyword,sep="")) setwd(paste(d,"/",keyword,sep="")) for(i in 1:length(url)){ call <- paste(i,"/",length(url), "is now downloading...",sep=" ") print(call) filename <- paste(i,".pdf",sep="") download.file(url=url[i],destfile=filename,quiet=T) } setwd(d) RNA-Seqというキーワードがアブストに ある文献を一度にダウンロード
17.
その他 • web上の既存のDBにアクセスもできる
(Rパッケージガイドブック参照)
18.
まとめ • 大規模データの扱いはRDBMS • データ解析はR •
RSQLiteで美味しいとこどりできる • 書いたソースコードは以下にあるのでご自由に https://sites.google.com/site/scriptofbioinformatics/ sql-guan-xi/pubmednodetabesu-gou-zhu-r-sqlite
19.
参考 二階堂さんのサイト http://cat.hackingisbelieving.org/bioinfo_tips/Learning-sqlite3.html DBOnline http://www.dbonline.jp/sqlite/ sqliteコマンド 基本的な使い方 http://aaabbbkirai.sytes.net/wiki/tech/db/sqlite%A5%B3%A5%DE%A5%F3%A 5%C9%20%B4%F0%CB%DC%C5%AA%A4%CA%BB%C8%A4%A4%CA%F D.html#p2994141 RSQLite Reference
manual http://cran.r-project.org/web/packages/RSQLite/RSQLite.pdf Rパッケージガイドブックの@wakutekaが書いたとこ
Download







![可視化
paper <- rep(0:0,length=85)
for(i in 1928:2012){
command <- paste("SELECT COUNT(*) FROM pubmed WHERE abst like '%RNA-Seq%' AND year = ",i,";",sep="")
prepaper <- dbGetQuery(con,command)
if(as.numeric(prepaper)!=0){
paper[i-1928] <- as.numeric(prepaper)
}
}
jpeg(file="paper.jpeg")
plot(1928:2012,paper,"l",ylab="Frequency",xlab="Year")
dev.off()
論文の本数が2000年後半あたりにい
きなり急増している!](https://image.slidesharecdn.com/rsqlite-121022105537-phpapp02/85/R-SQLite-14-320.jpg)
![pdf根こそぎダウンロード
keyword <- "RNA-Seq"
url <- as.matrix(dbGetQuery(con,paste("SELECT url FROM pubmed WHERE abst
like '%",keyword,"%';",sep="")))
url <- sub(" ","",url)
d <- getwd()
dir.create(paste(d,"/",keyword,sep=""))
setwd(paste(d,"/",keyword,sep=""))
for(i in 1:length(url)){
call <- paste(i,"/",length(url), "is now downloading...",sep=" ")
print(call)
filename <- paste(i,".pdf",sep="")
download.file(url=url[i],destfile=filename,quiet=T)
}
setwd(d)
RNA-Seqというキーワードがアブストに
ある文献を一度にダウンロード](https://image.slidesharecdn.com/rsqlite-121022105537-phpapp02/85/R-SQLite-16-320.jpg)













































![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























