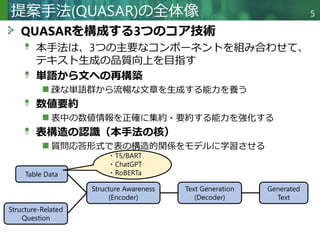
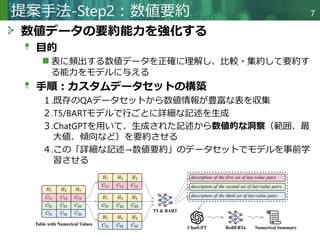
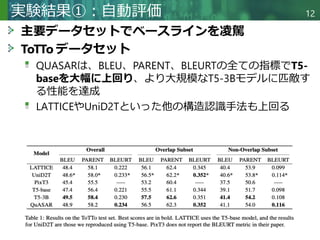
表からテキストへの生成は、構造化または半構造化された表形式データから自然言語による説明を自動的に生成することを目的とする。従来のテキスト生成タスクとは異なり、モデルが表構造を正確に理解し表現することが求められる。既存の手法は通常、表を線形化またはグラフ構造に変換して処理する。しかしこれらの手法は、表構造を適切に捉えられないか、複雑な注意機構に依存するため適用範囲が限定される。これらの課題に対処するため、我々はモデルの構造認識・表現能力を強化する質問駆動型自己教師付き学習アプローチ「QuASAR」を提案する。具体的には、自己教師付き学習向けに構造関連クエリ群を構築し、局所的・全体的な表構造の両方を明示的に捕捉するようモデルを誘導する。さらに、生成テキストの流暢性と事実性を向上させるため、2つの補助的事前学習タスクを導入する:単語から文への再構築タスクと数値要約タスクである。ToTToおよびHiTabデータセットでの実験結果は、本手法が既存手法と比較して高品質なテキストを生成することを実証している。






![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
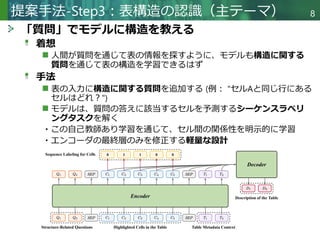
モデルアーキテクチャと学習2 つのタスクを同時に学習
入力:[構造に関する質問]+[ハイライトされたセル]+[表の
メタデータ]
学習:2つの目的関数を持つマルチタスク学習
シーケンスラベリング損失( ℒseq)
エンコーダが出力する各セルの表現を用いて、質問に対する正解ラベル
(関連あり/ なし)を予測構造理解を促進
テキスト生成損失( ℒgen)
デコーダが正解のテキスト記述を生成するように学習
総損失
ℒtotal = 𝜆𝜆seqℒseq + 𝜆𝜆genℒgen
モデルアーキテクチャと学習 10](https://image.slidesharecdn.com/quasaraquestion-drivenstructure-awareapproachfortable-to-textgeneration-251120050736-db316e82/85/QuASAR-A-Question-Driven-Structure-Aware-Approach-for-Table-to-Text-Generation-10-320.jpg)





![[DL輪読会]The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Se...](https://cdn.slidesharecdn.com/ss_thumbnails/theneuro-symbolicconceptlearnerinterpretingsceneswordsandsentencesfromnaturalsupervision-190906012005-thumbnail.jpg?width=640&height=640&fit=bounds)



















































