議論抽出(Argument Mining: AM)とは、テキストから議論、その構成要素、および議論と構成要素間の関係を自動的に抽出するプロセスである。オンライン討論をサポートするプラットフォームが増えるにつれ、特に下流タスクを支援する上で、AMの必要性はますます切迫している。関係ベースの議論抽出(Relation-based AM: RbAM)は、議論間の合意(支持)関係と不一致(攻撃)関係を特定することに焦点を当てたAMの一形態である。RbAMは困難な分類課題であり、既存手法は満足のいく性能を発揮できていない。本論文では、適切に事前学習とプロンプティングを施した汎用大規模言語モデル(LLM)が、最良のベースライン(RoBERTaベース)を大幅に上回る性能を発揮し得ることを示す。具体的には、2つのオープンソースLLM(Llama-2とMistral)を用いて10のデータセットで実験を行った。








![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
予備実験
目的
LLMへ入力するfew-shot例の選定
タスク定義をプロンプトに含めるべきか検証
プロンプトにテンプレート([INST]...[/INST]) を含めるべき
か検証
方法
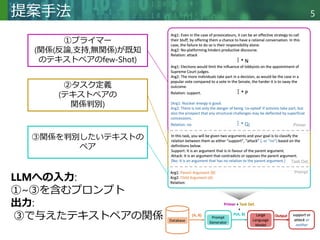
2A2Sのプライマーを4つ用意
タスク定義、テンプレートがある場合とない場合のマイ
クロF1スコアを計算
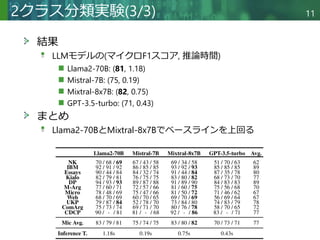
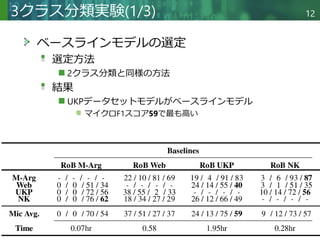
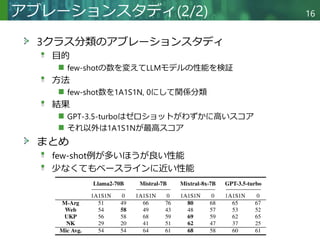
結果
タスク定義なし、テンプレートなしが最良
もっとも良いfew-shot例を実験に使用
2クラス分類実験(2/3) 10](https://image.slidesharecdn.com/canlargelanguagemodelsperformrelation-basedargumentmining-251120052221-18a7bbf3/85/Can-Large-Language-Models-perform-Relation-based-Argument-Mining-10-320.jpg)















![[2016-12-01] DDBJデータ解析チャレンジ報告:機械学習コンペティションのタスク設計とルール設定](https://cdn.slidesharecdn.com/ss_thumbnails/bmbposter161201-161202134900-thumbnail.jpg?width=640&height=640&fit=bounds)









![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)
























