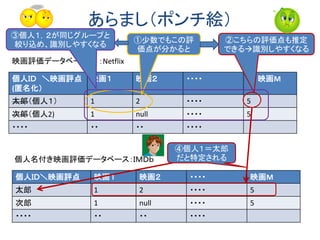
• Netflixの映画評価データベースを使った公開タスク事件:
Narayanan,A., Shmatikov, V. (2008) Robust De-anonymization of Large Sparse
Datasets, Proc. of the 2008 IEEE Symposium on Security and Privacy, 111-125
という論文が以下のような匿名性の崩壊現象を示しました。
このデータベースは、50万人のユーザがのべ1億件の映画評価を行った
データベース。1人あたり8本を評価したデータで評価実験タスクが公開され、
参加者が募集されました。
評価した日が3日程度誤差があるとすると
• 2本の映画評価が知られると、60%のユーザが識別され、
• 4本の映画評価が知られると90%のユーザが識別されます
– 識別とは個人を特定できないが、同一人物のデータだと認識された状態で
あり、外部のデータと突き合わせると個人特定につながりやすい
• これによって、Netflix公開タスクは中止に追い込まれました。
あらまし
Narayanan2008:Robust De-anonymization of
Large Sparse Datasets



























![Sparsityに関する定理の改善
prrDr
ArD
mpDmD
qDDSimKjNjqSimD
jDDNK
jk
j
Pr
eddeanonymiz,perfectlysupp
,:,1Prsparse,
],1[:Sparsity
を持つことである。ムを生成するアルゴリズから次式を満たす攻撃者が
とは、に対してであるとき、が定義(再掲)
かつであるとは、に関してが
行とする。の第をんだ値とする。区間からランダムに選を定義
である。に対してとは
が成立するならこのとき、
とする。はさらに、
であるとする。に関してとはアルゴリズム
があるとき、に関する)仮定条件に関するあるとする。
定理
eddeanonymizperfectly'
sparse,
eddeanonymiz,,'
',,(',
7
qpDAD
H
qD
mpDSimA
HDDmDDqp
](https://image.slidesharecdn.com/netfix-after-140601023956-phpapp01/85/slide-29-320.jpg)
































![Differential privacy without sensitivity [NIPS2016読み会資料]](https://cdn.slidesharecdn.com/ss_thumbnails/nipsyomi2016slideshare-170122091905-thumbnail.jpg?width=640&height=640&fit=bounds)


































