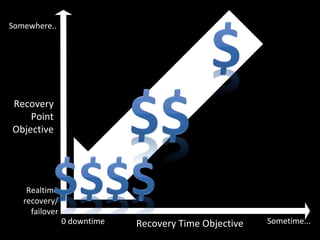
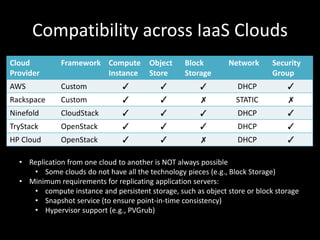
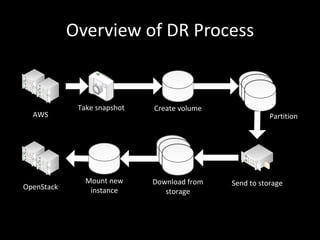
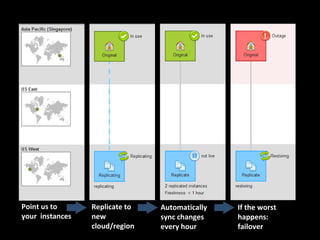
This document discusses building a disaster recovery solution using OpenStack. It outlines the goals of providing a configurable warm standby solution with a known recovery point objective (RPO) and reduced recovery time objective (RTO) to minimize business impact. The document describes challenges in replicating an application across clouds while preserving the running environment. It provides an overview of the disaster recovery process using OpenStack, including taking snapshots, creating volumes, and mounting new instances. Optimizations discussed include incremental backups and parallel transfers to improve large data transfer speeds across cloud datacenters for disaster recovery.