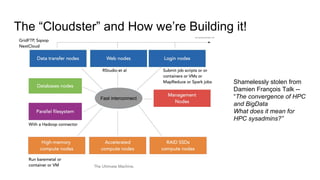
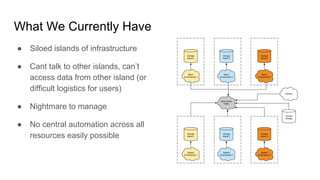
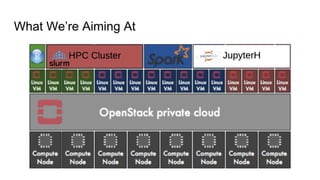
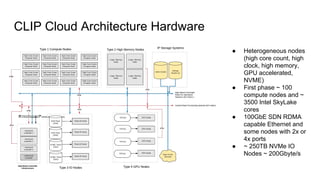
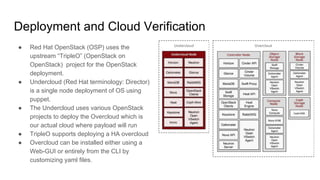
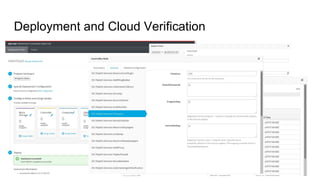
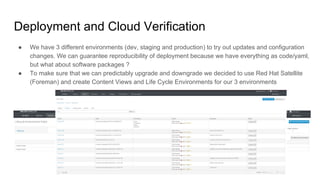
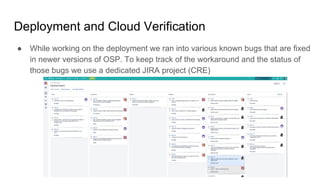
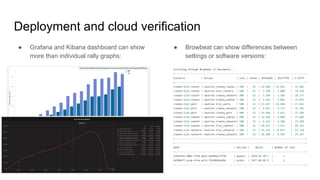
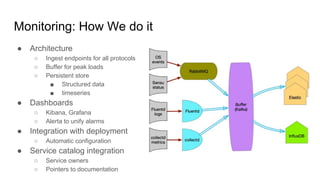
The document outlines a presentation on the cloud infrastructure project 'Clip' at Vienna Bio Center, which aims to enhance HPC services using OpenStack. It details the team's structure, existing challenges with siloed infrastructure, and the project's phased approach to build and deploy a software-defined data center. Key lessons emphasize the complexity of OpenStack, the necessity for multiple environments for deployment verification, and strategies for effective monitoring and performance testing.



























































![[Rakuten TechConf2014] [F-4] At Rakuten, The Rakuten OpenStack Platform and B...](https://cdn.slidesharecdn.com/ss_thumbnails/f4openstackrakutentechnologyconference20141025-141105211349-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



























