Downloaded 16 times



























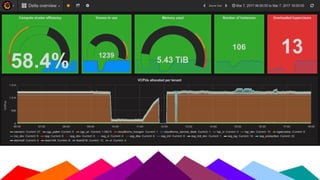
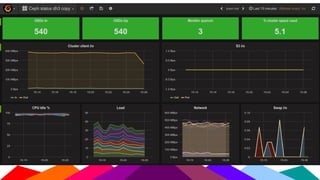
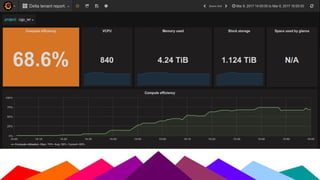












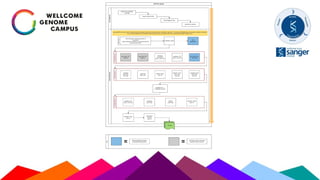
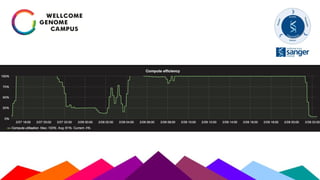

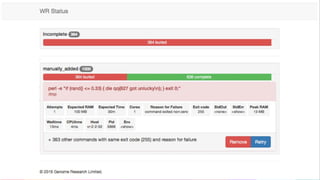














The Sanger Institute's transition to OpenStack aimed to enhance data handling and computing efficiency, while addressing shortcomings of their previous LSF system. They outlined their journey from initial training to production systems, discussed hardware choices, and detailed numerous challenges encountered, including networking and deployment issues. Future directions emphasize expanding Ceph storage capabilities and exploring advanced OpenStack features like bare-metal deployment and instance pricing.



































































