Downloaded 16 times



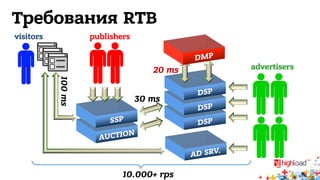
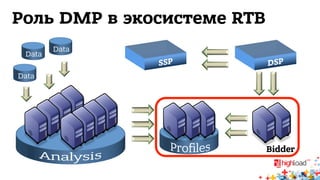


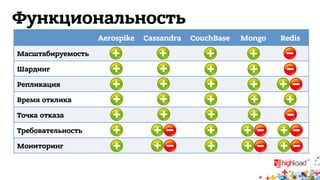



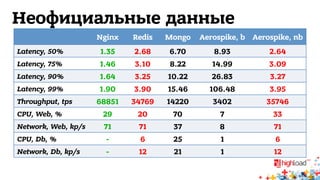
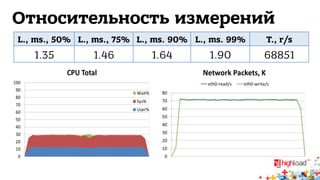
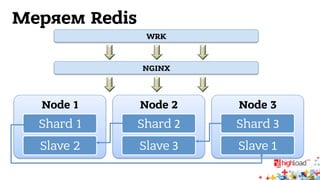
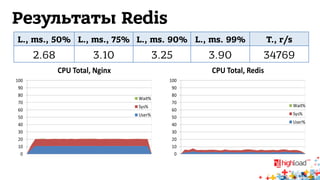

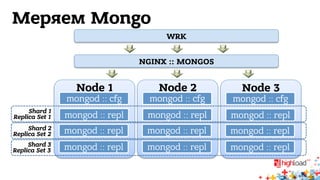
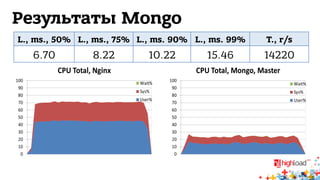
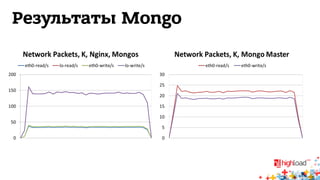
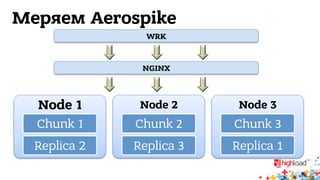
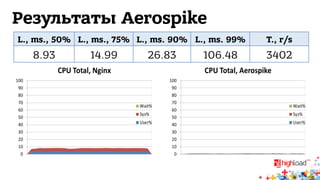
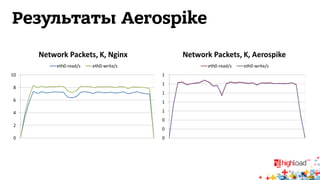
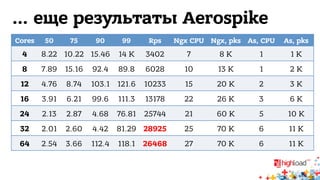
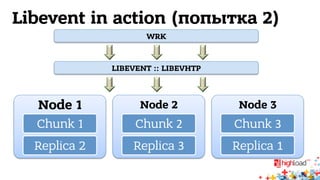
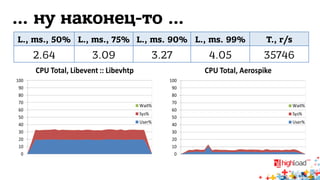
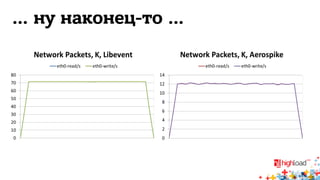




Документ обсуждает архитектуру систем RTB (Real-Time Bidding), включая выводу характеристик производительности различных NoSQL решений, таких как Aerospike, Cassandra, Couchbase, MongoDB и Redis. Уделяется внимание времени отклика, пропускной способности и необходимым требованиям для эффективной работы систем, представлен анализ данных по различным метрикам. В заключение, автор предлагает рекомендации по выбору архитектуры и использованию технологий для оптимизации производительности.
































































