Downloaded 481 times







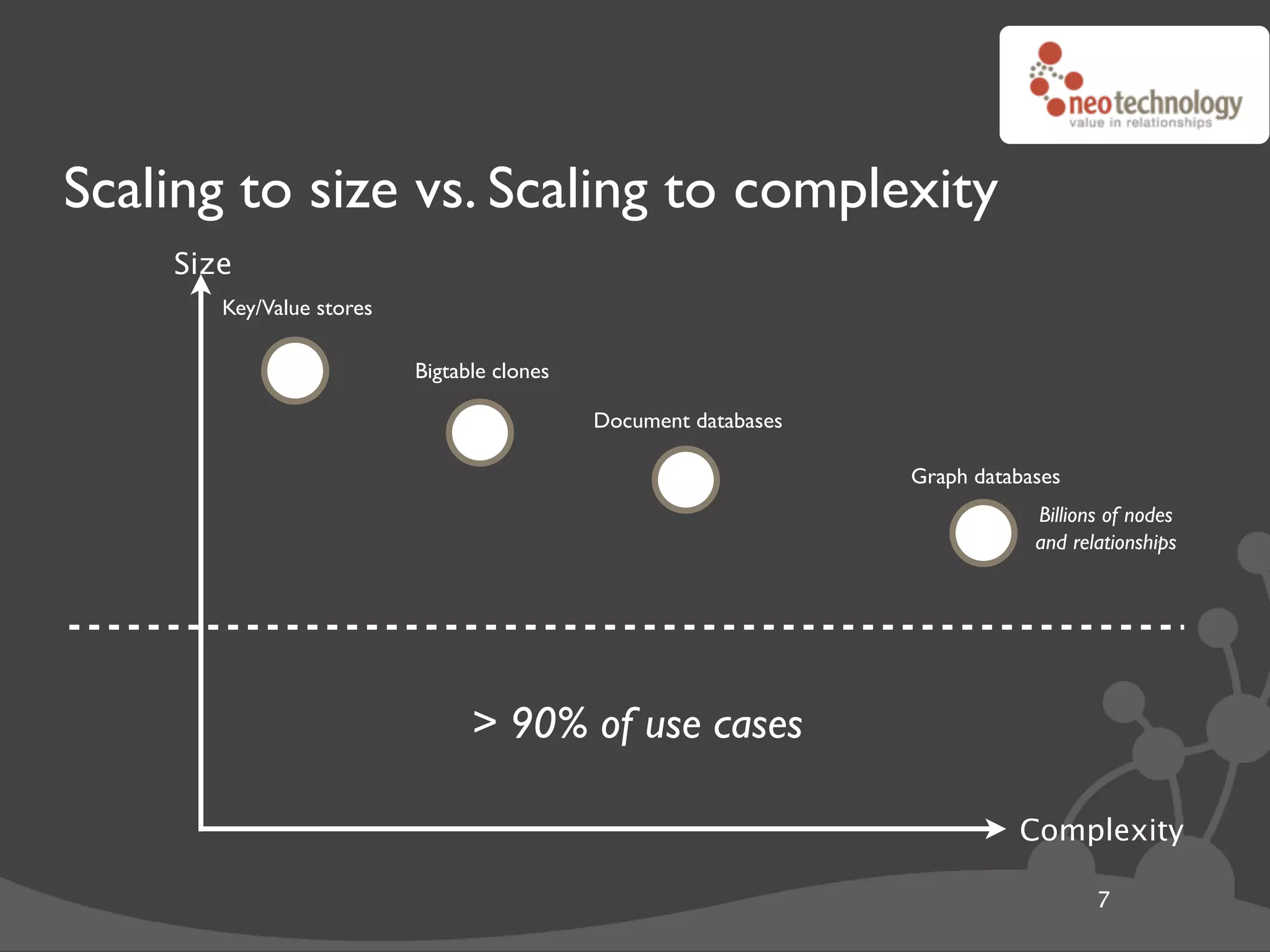








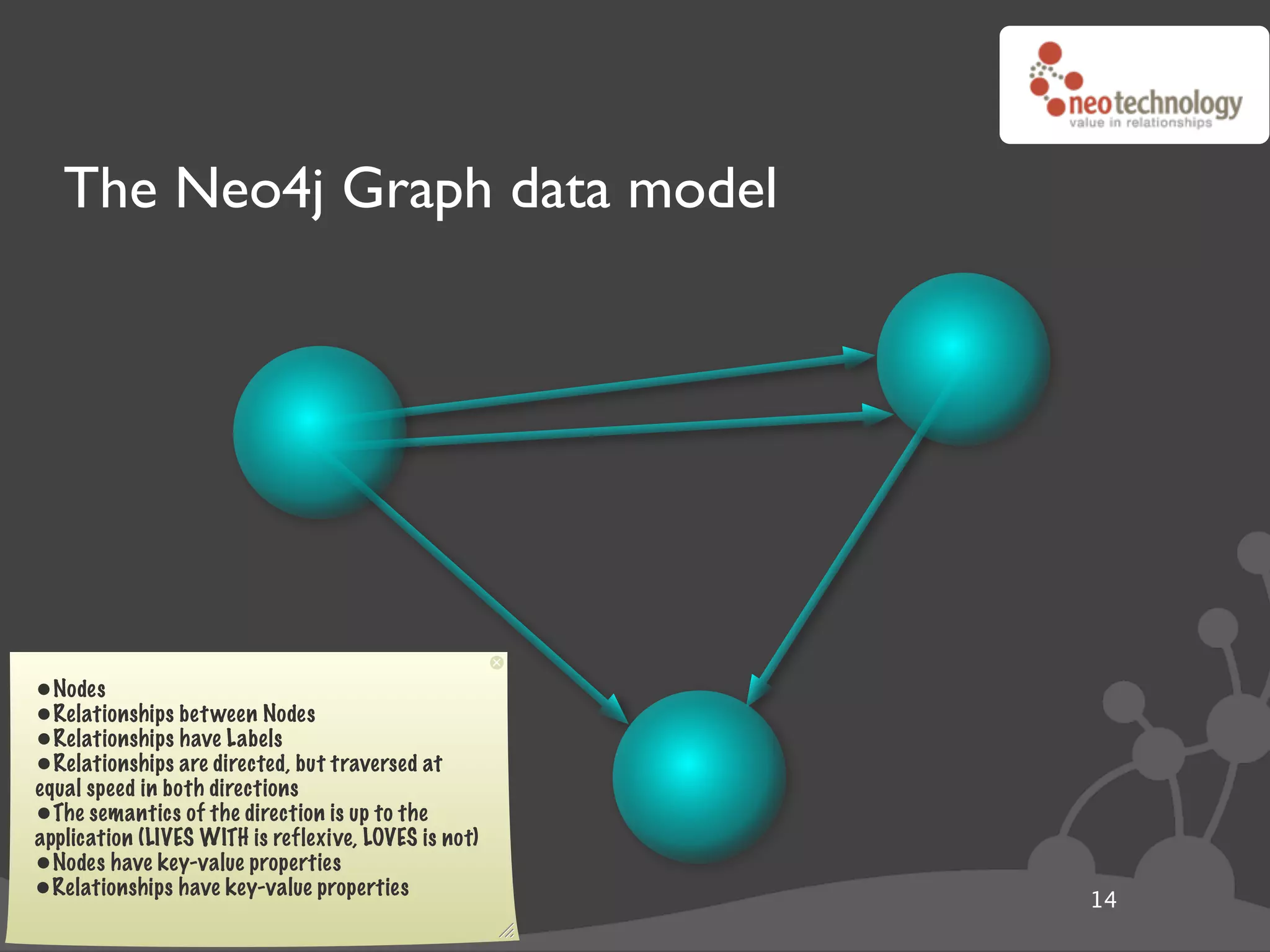
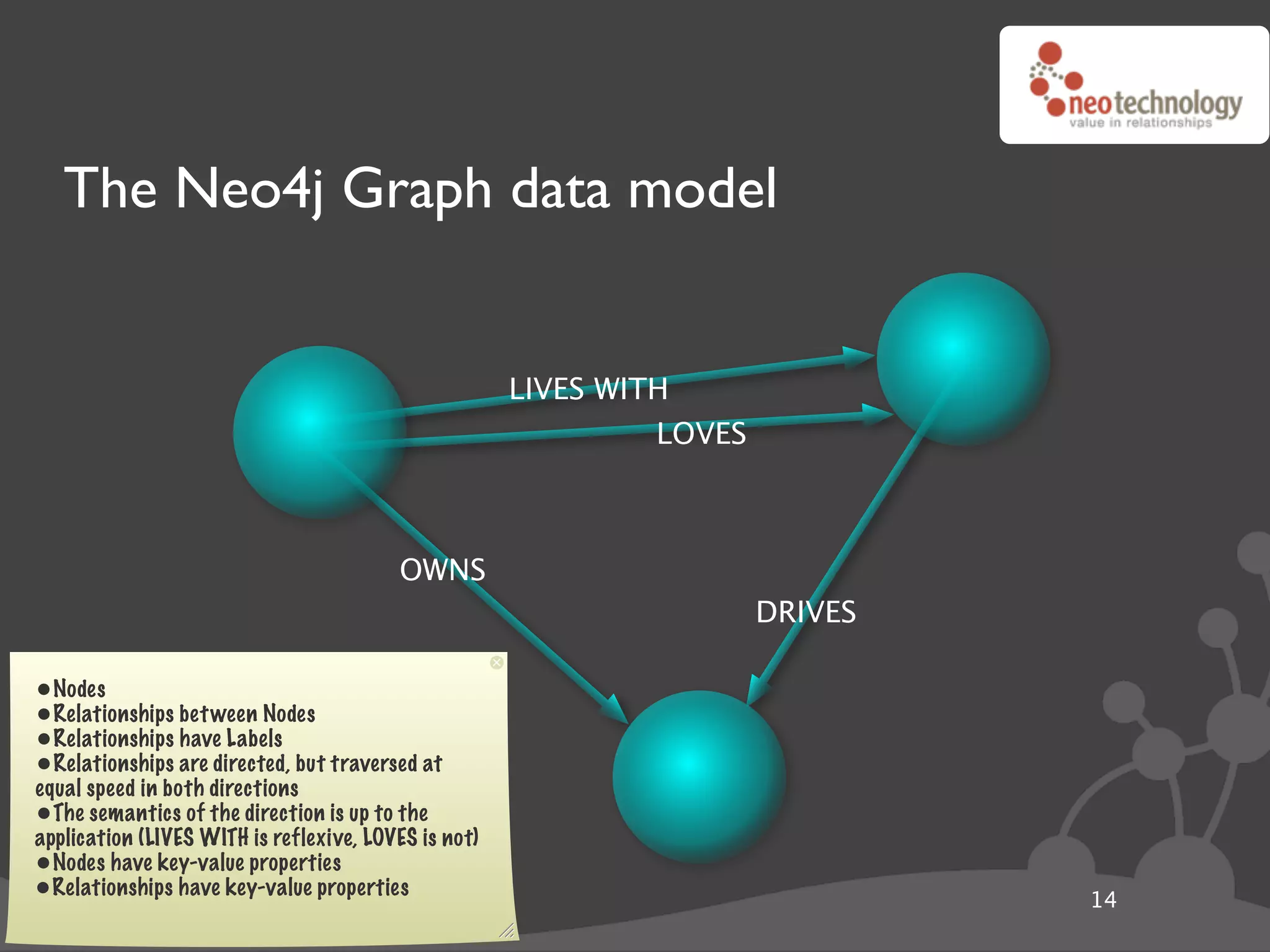
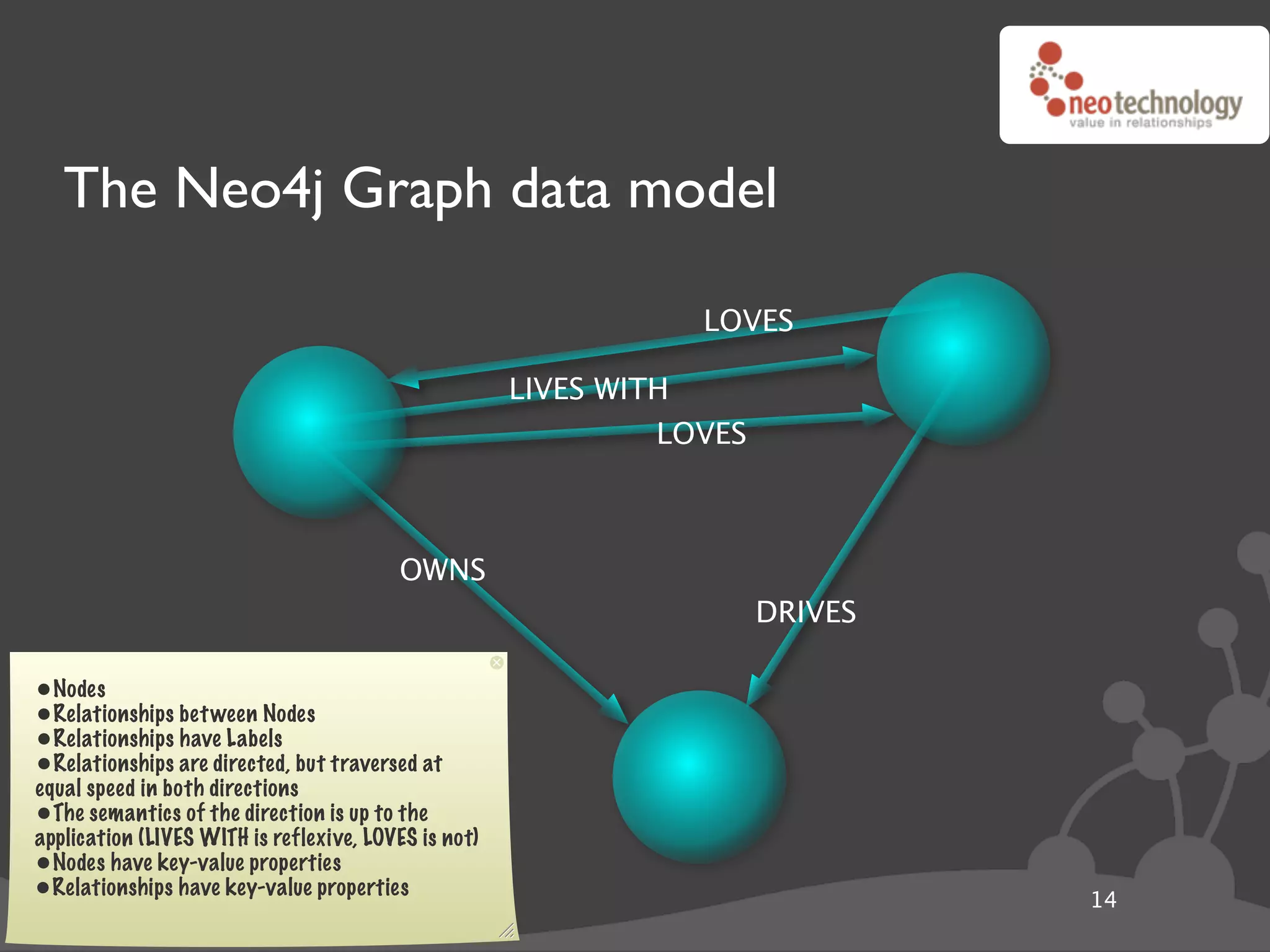
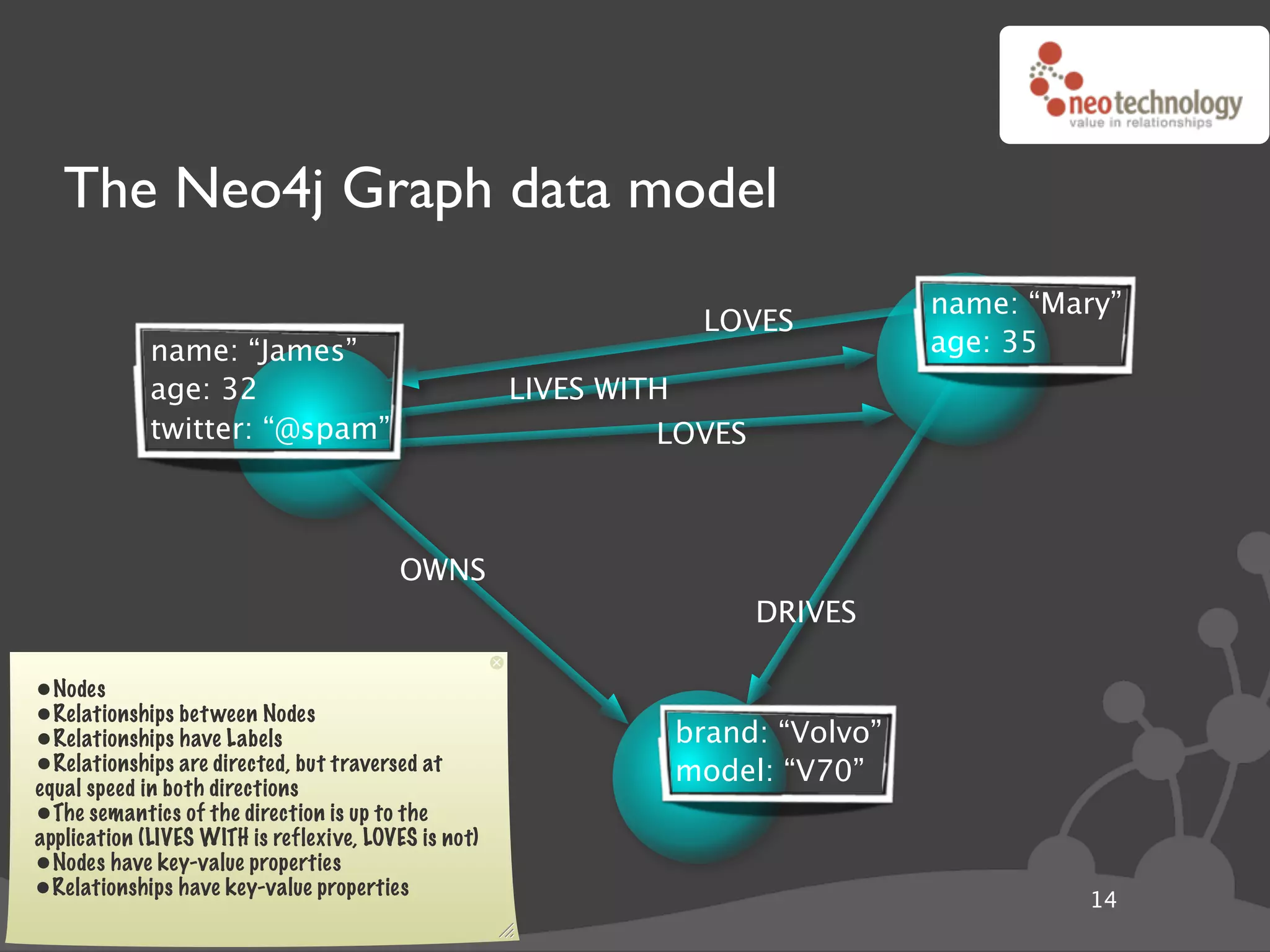
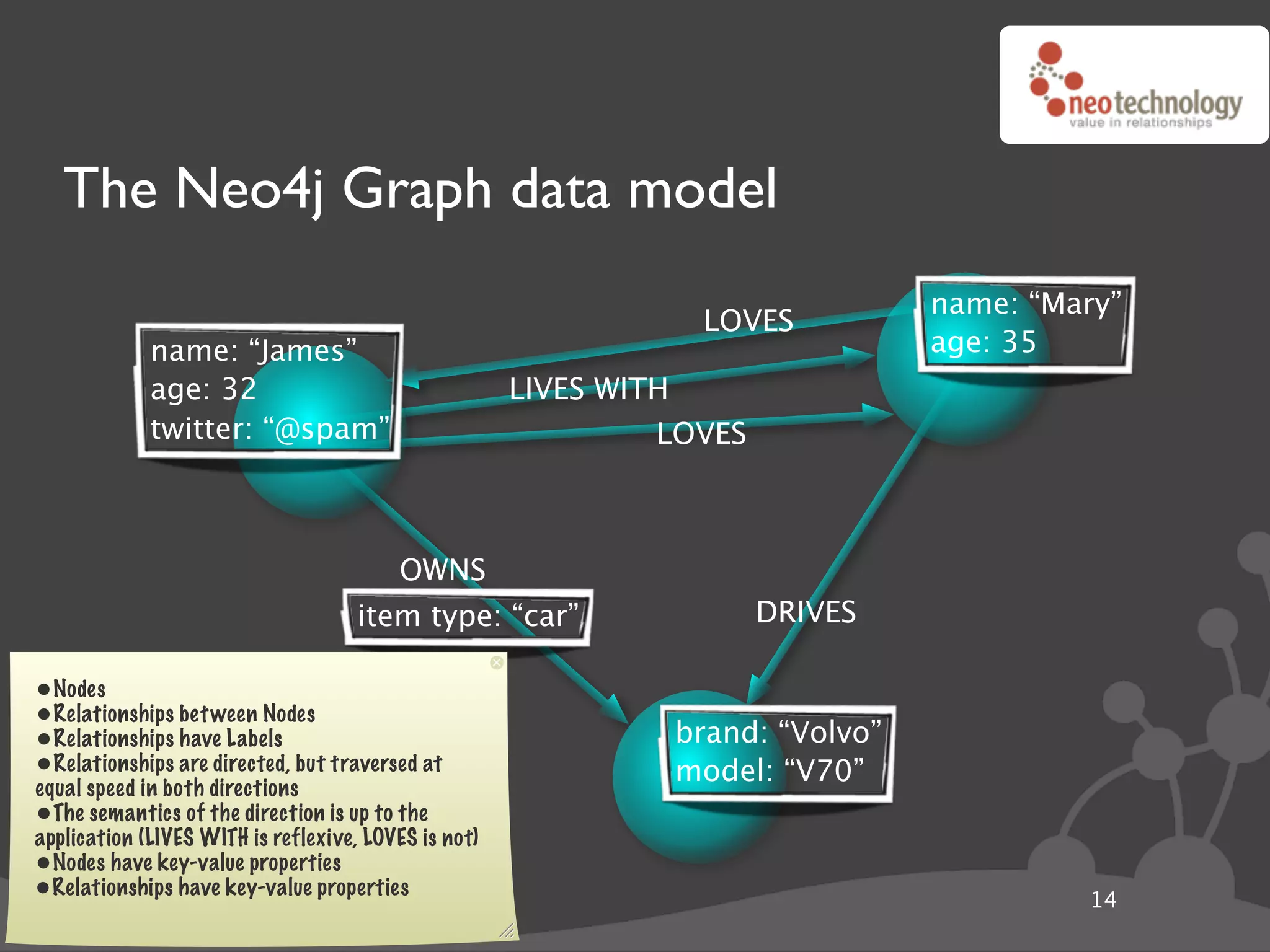



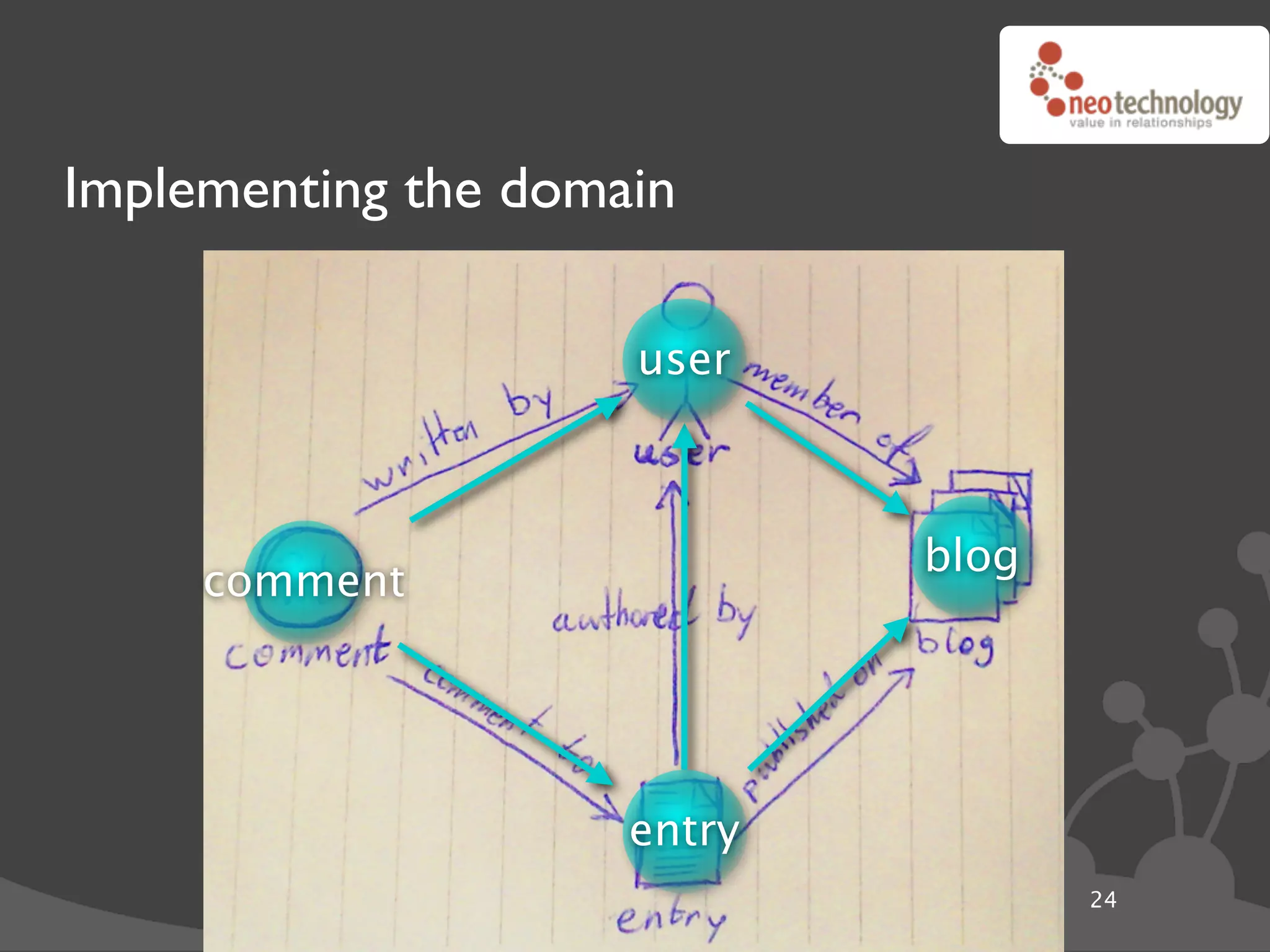
![Graph traversals name: “The Architect”
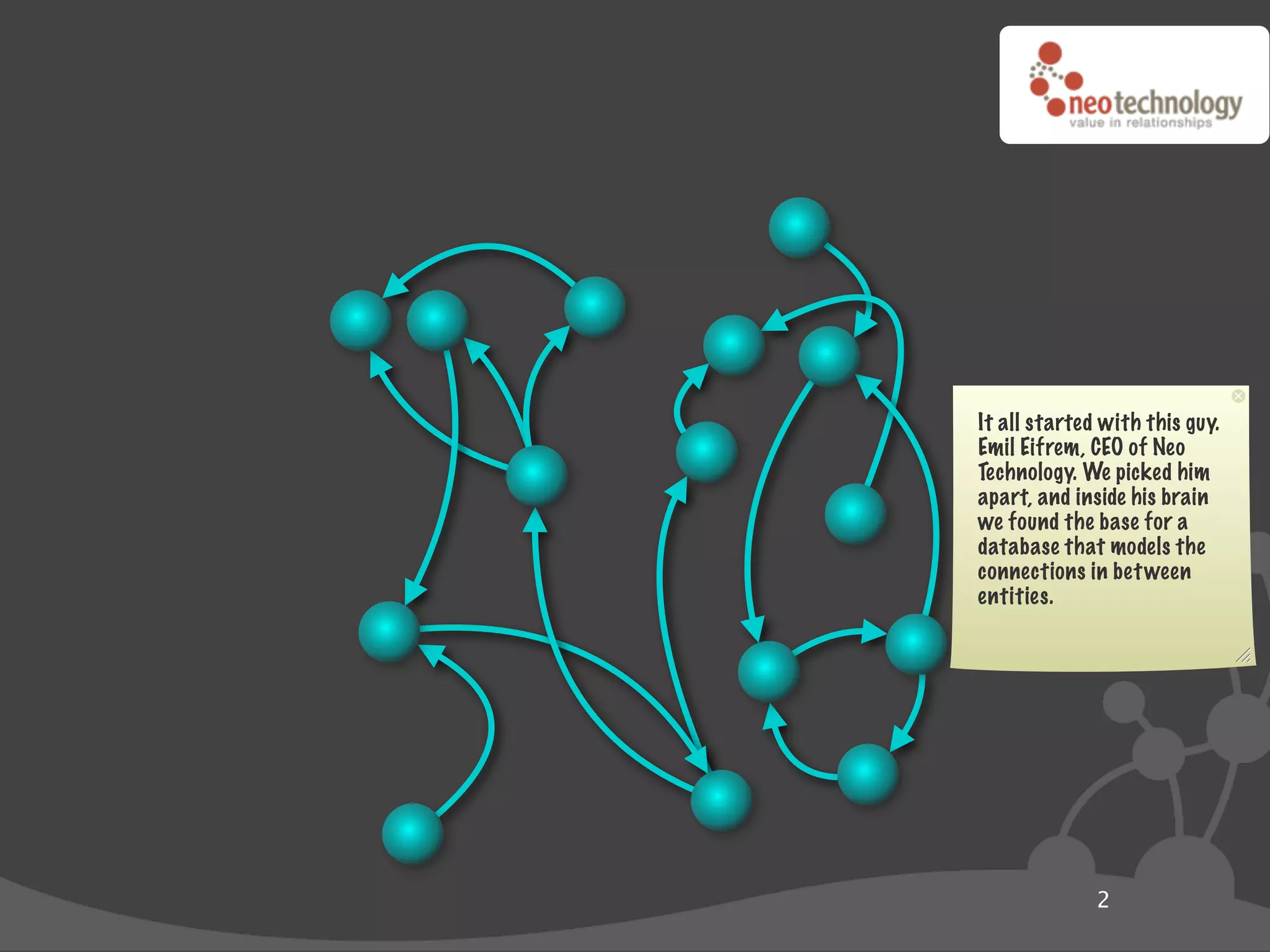
disclosure: “public”
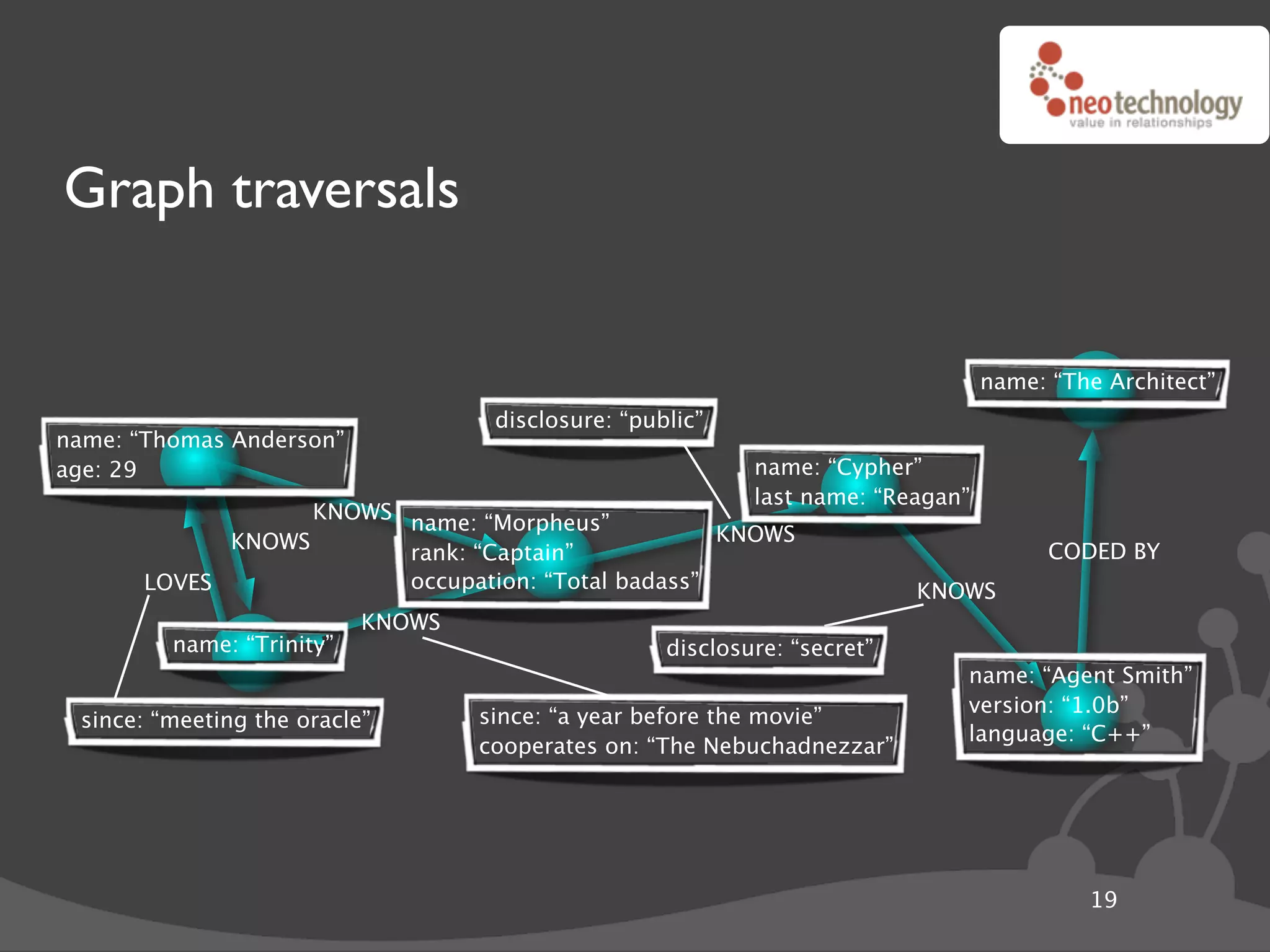
name: “Thomas Anderson”
age: 29 name: “Cypher”
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
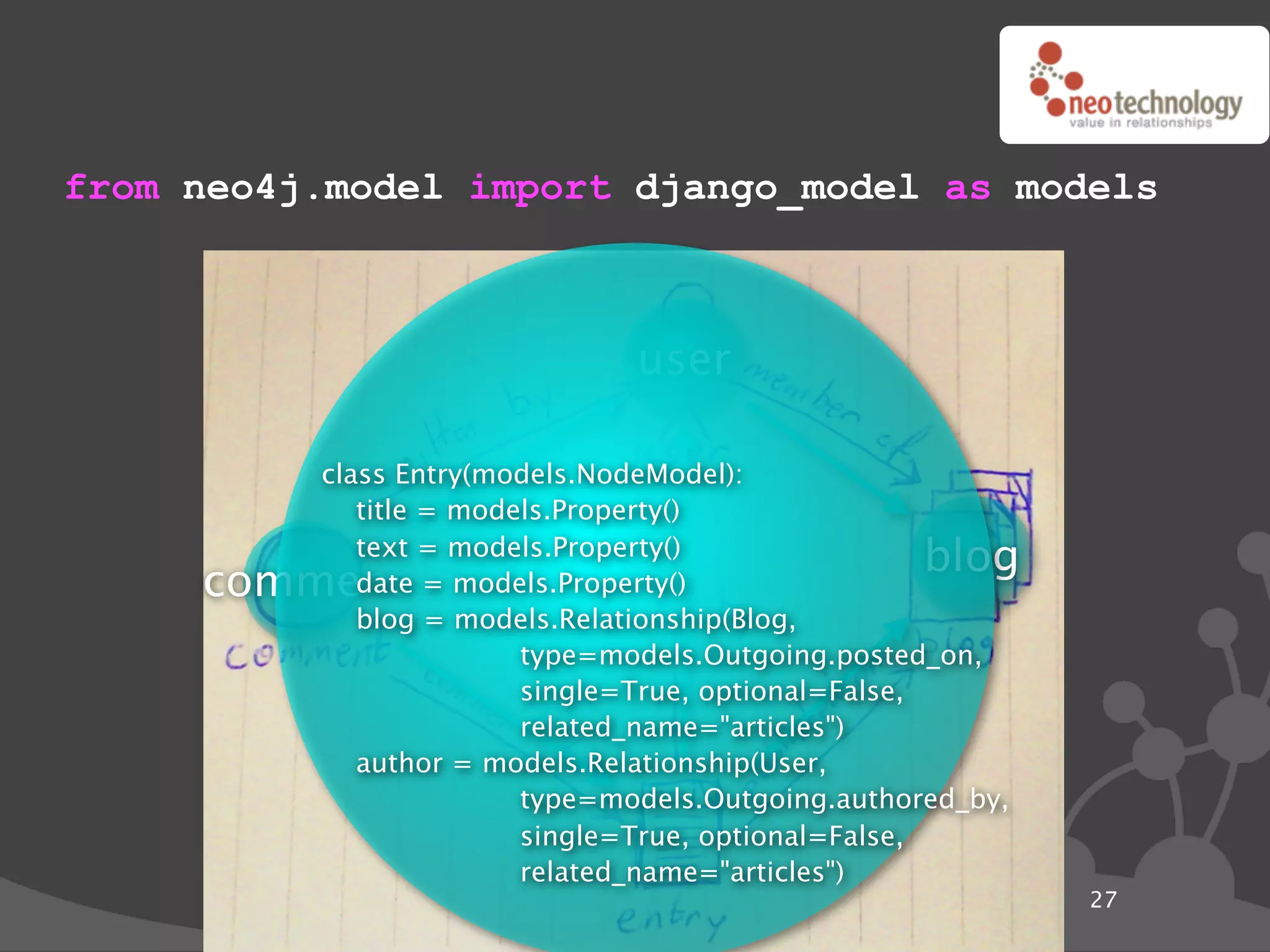
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ]
order = neo4j.BREADTH_FIRST
stop = neo4j.STOP_AT_END_OF_GRAPH
returnable = neo4j.RETURN_ALL_BUT_START_NODE
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-35-2048.jpg)
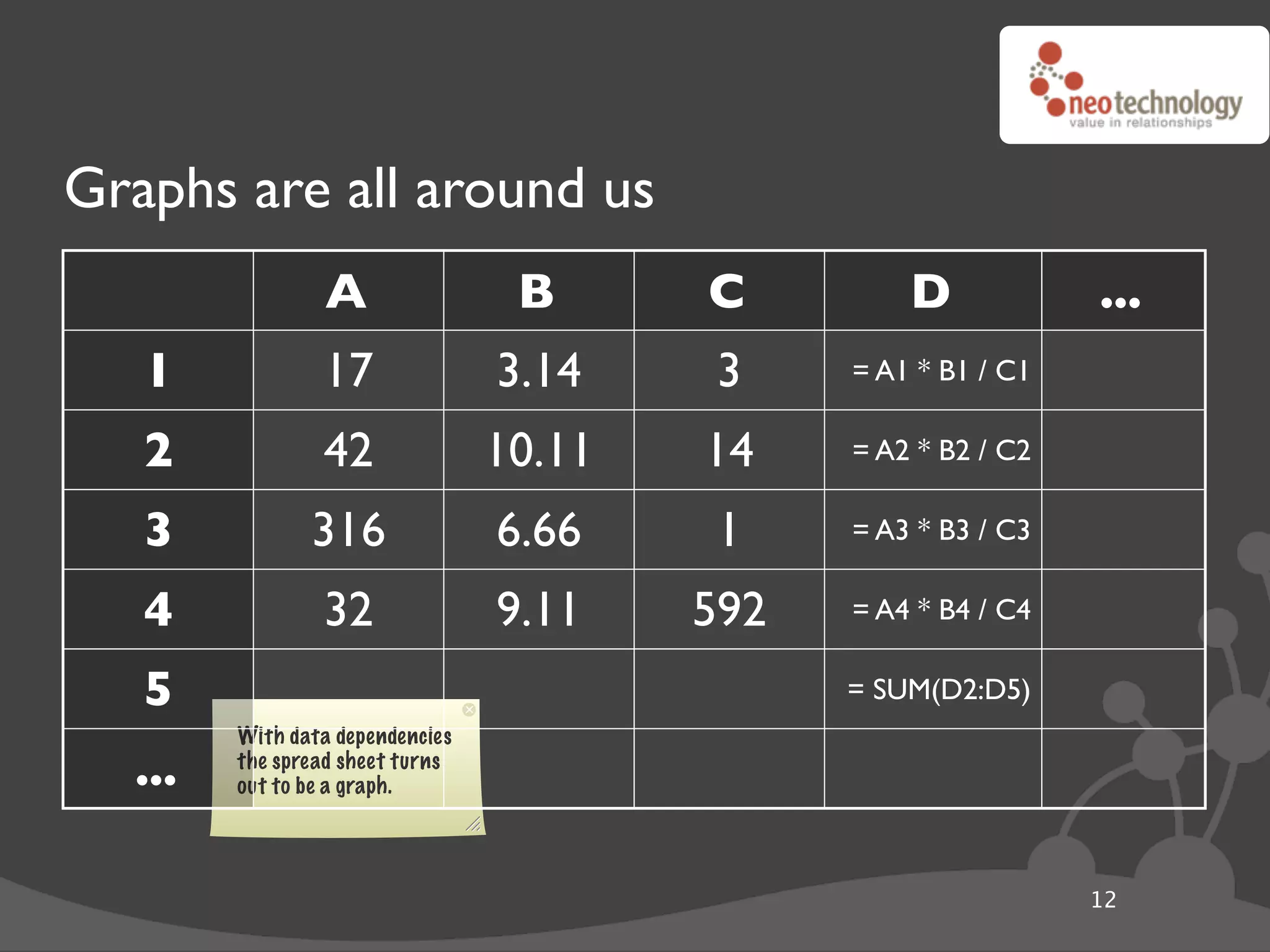
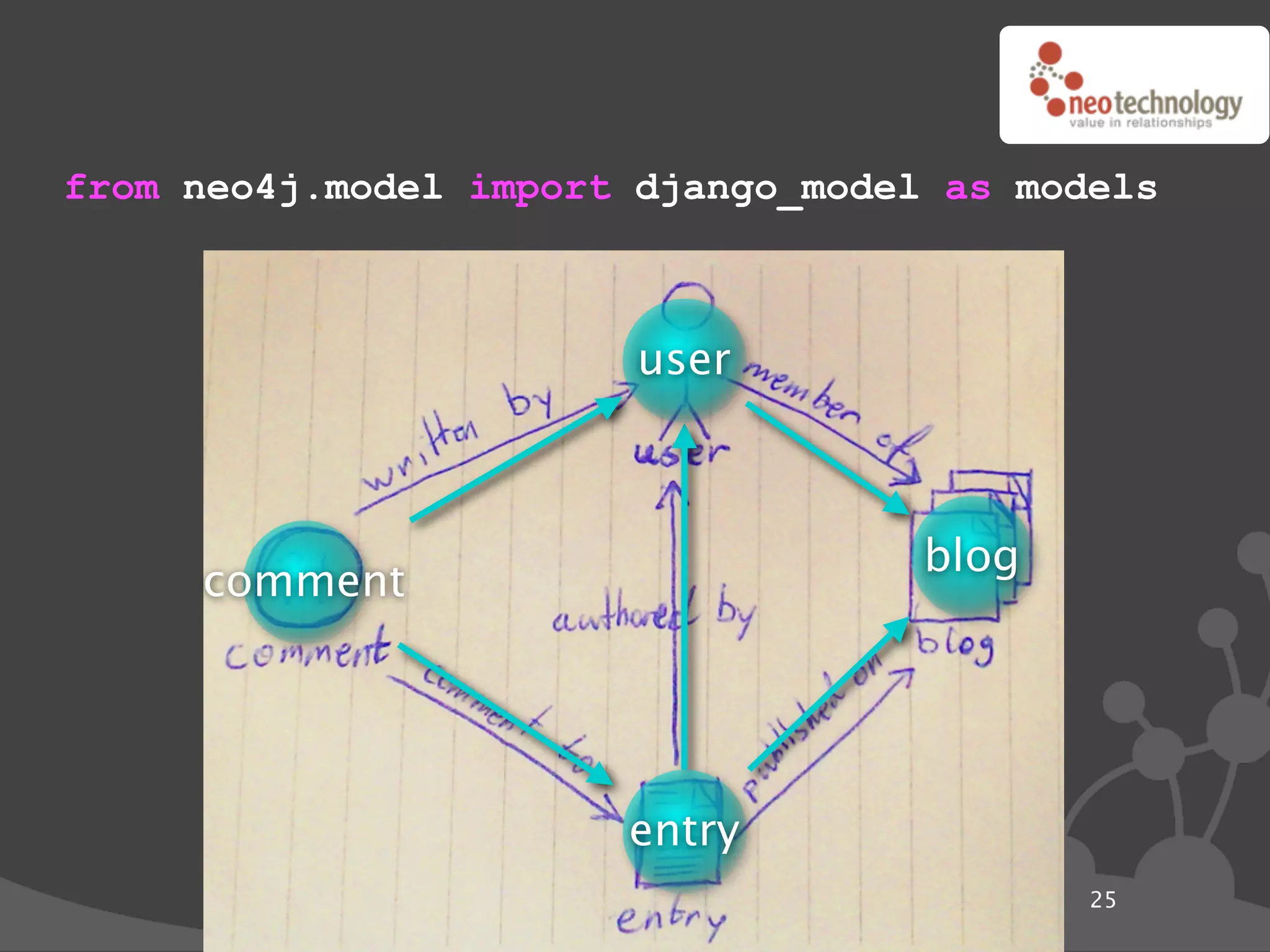
![Graph traversals name: “The Architect”
disclosure: “public”
name: “Thomas Anderson”
age: 29 name: “Cypher”
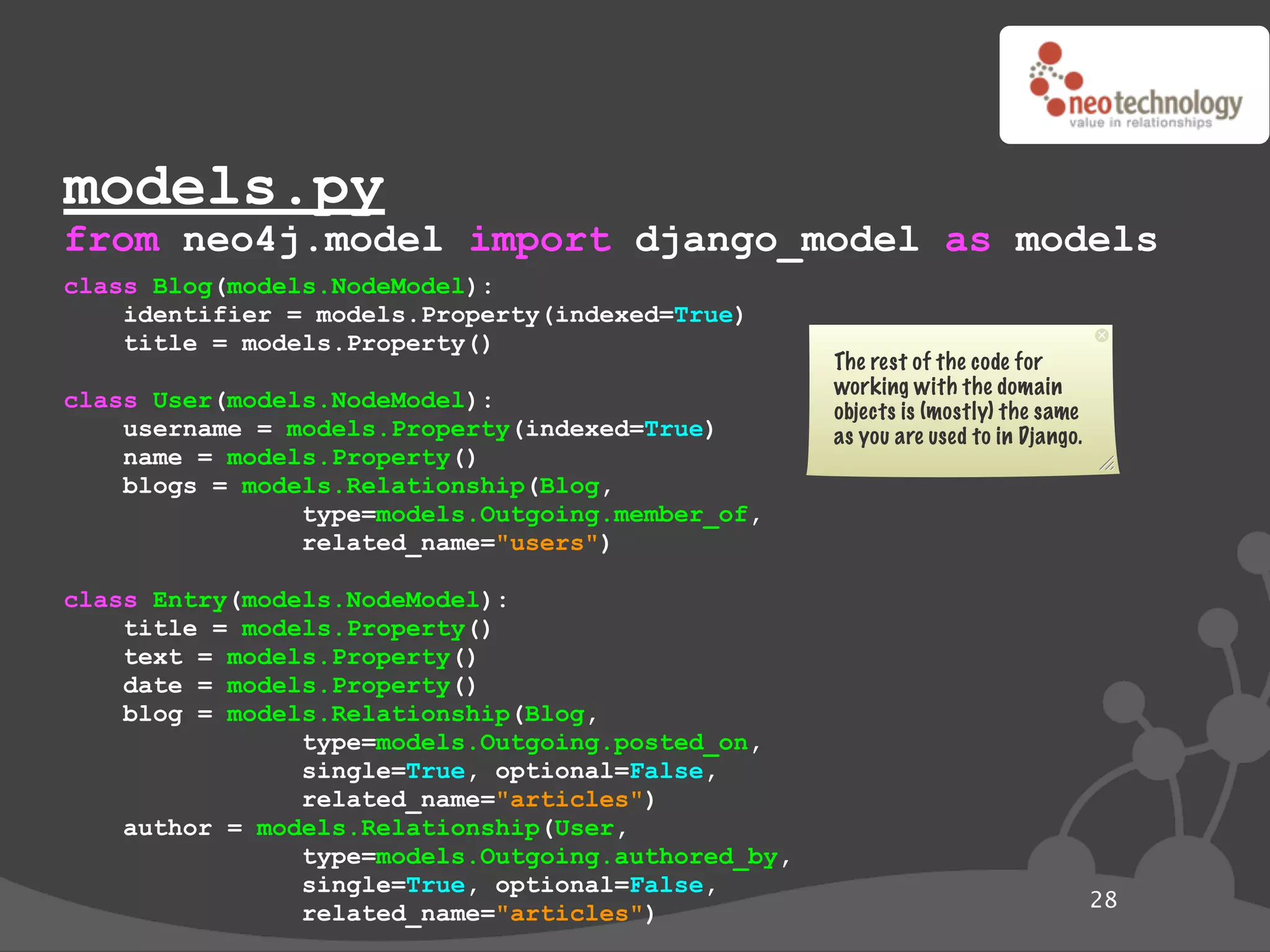
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ]
order = neo4j.BREADTH_FIRST
stop = neo4j.STOP_AT_END_OF_GRAPH
returnable = neo4j.RETURN_ALL_BUT_START_NODE
for friend_node in Friends(mr_anderson):
print "%s (@ depth=%s)" % ( friend_node["name"],
friend_node.depth )
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-36-2048.jpg)
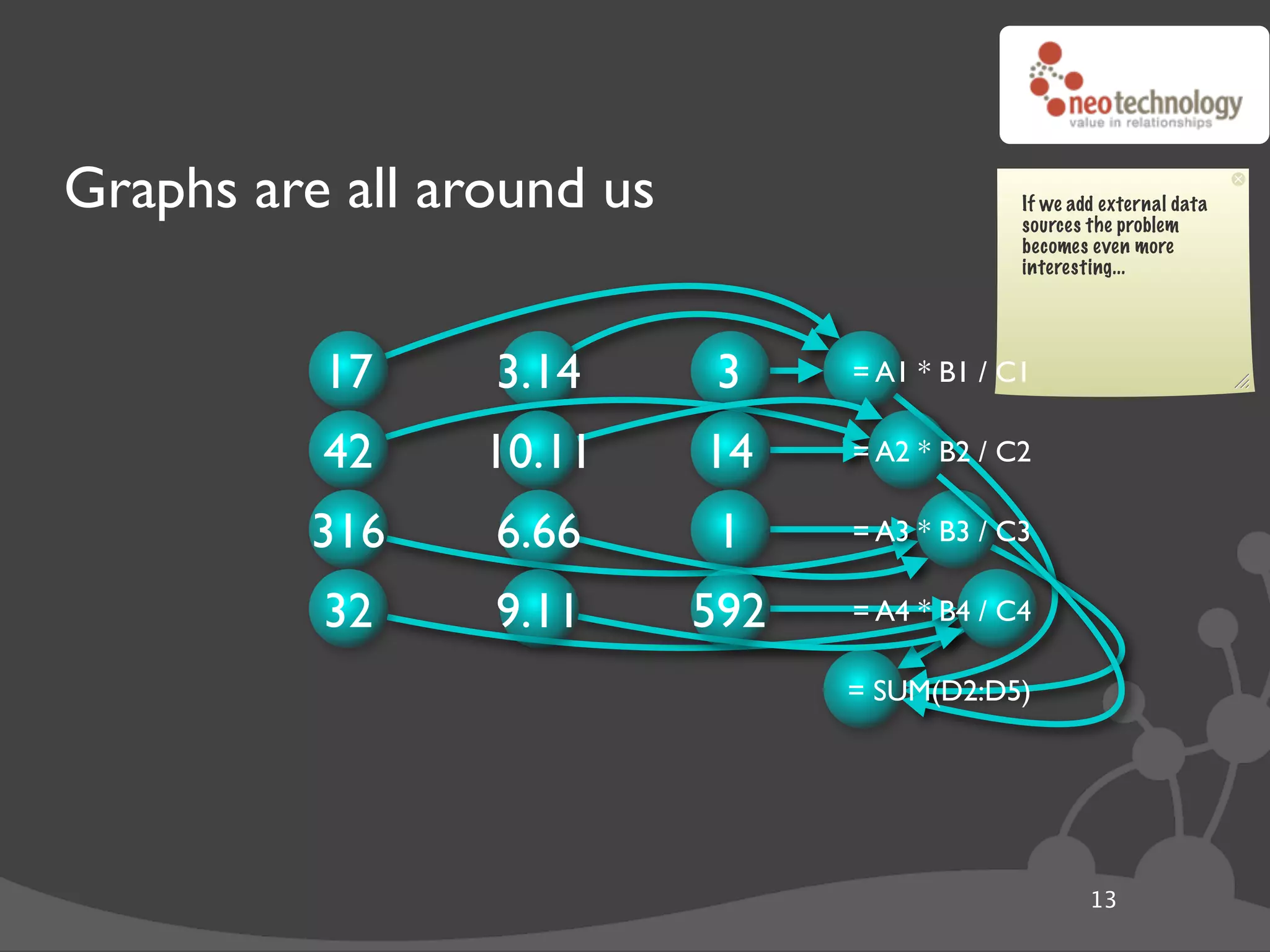
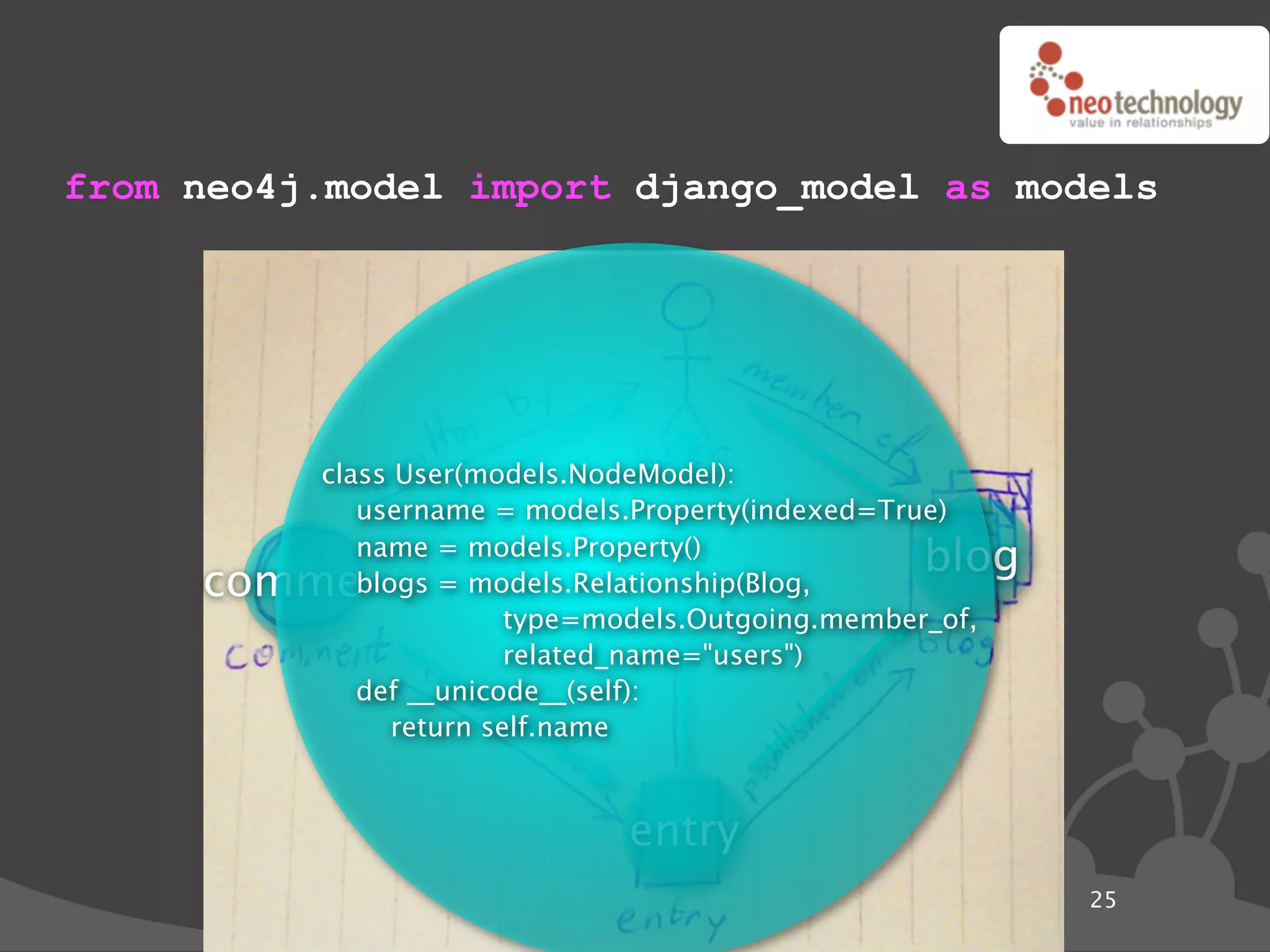
![Graph traversals name: “The Architect”
disclosure: “public”
name: “Thomas Anderson”
age: 29 name: “Cypher”
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ]
order = neo4j.BREADTH_FIRST
stop = neo4j.STOP_AT_END_OF_GRAPH
returnable = neo4j.RETURN_ALL_BUT_START_NODE
for friend_node in Friends(mr_anderson):
print "%s (@ depth=%s)" % ( friend_node["name"],
friend_node.depth )
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-37-2048.jpg)
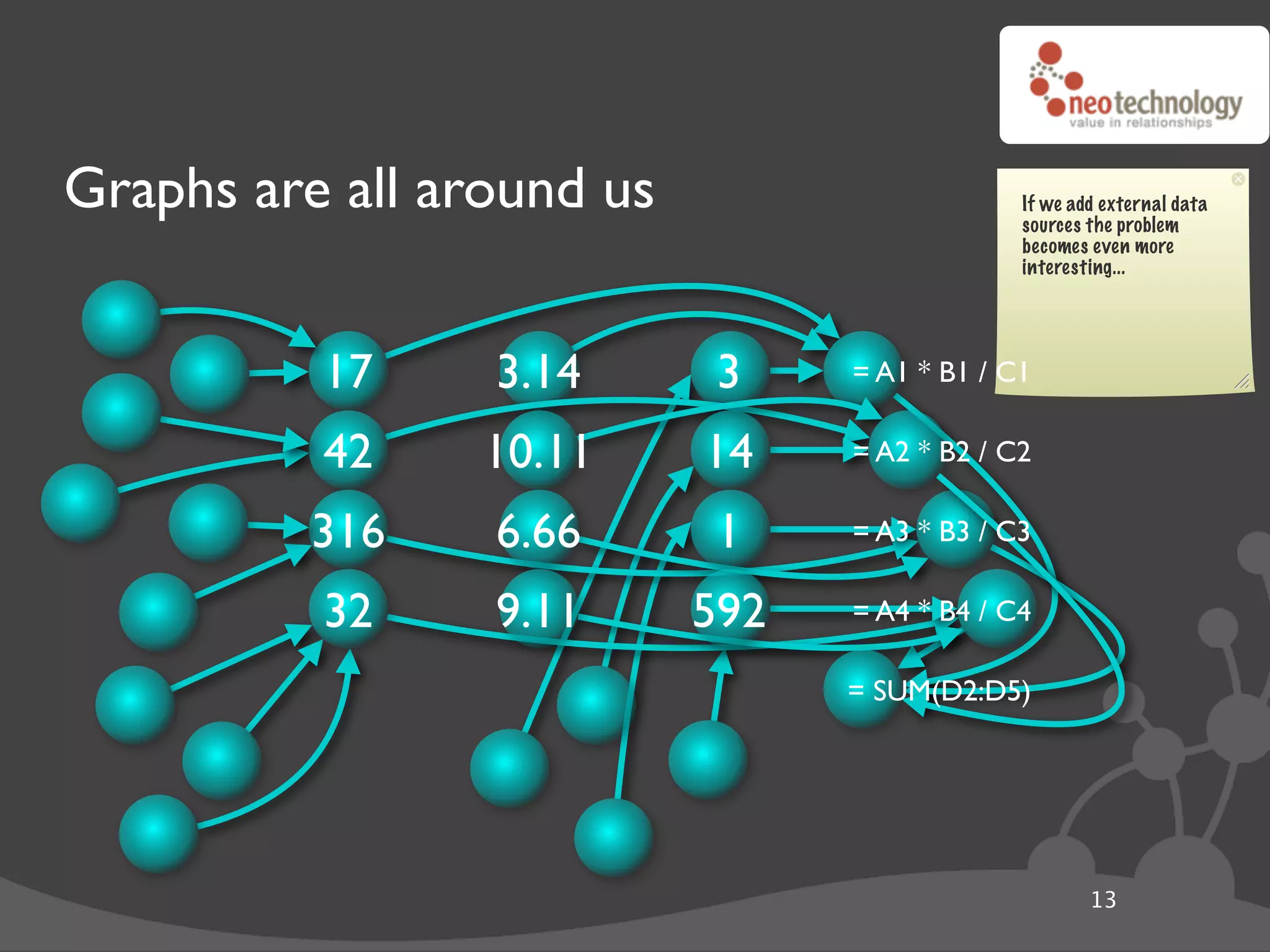
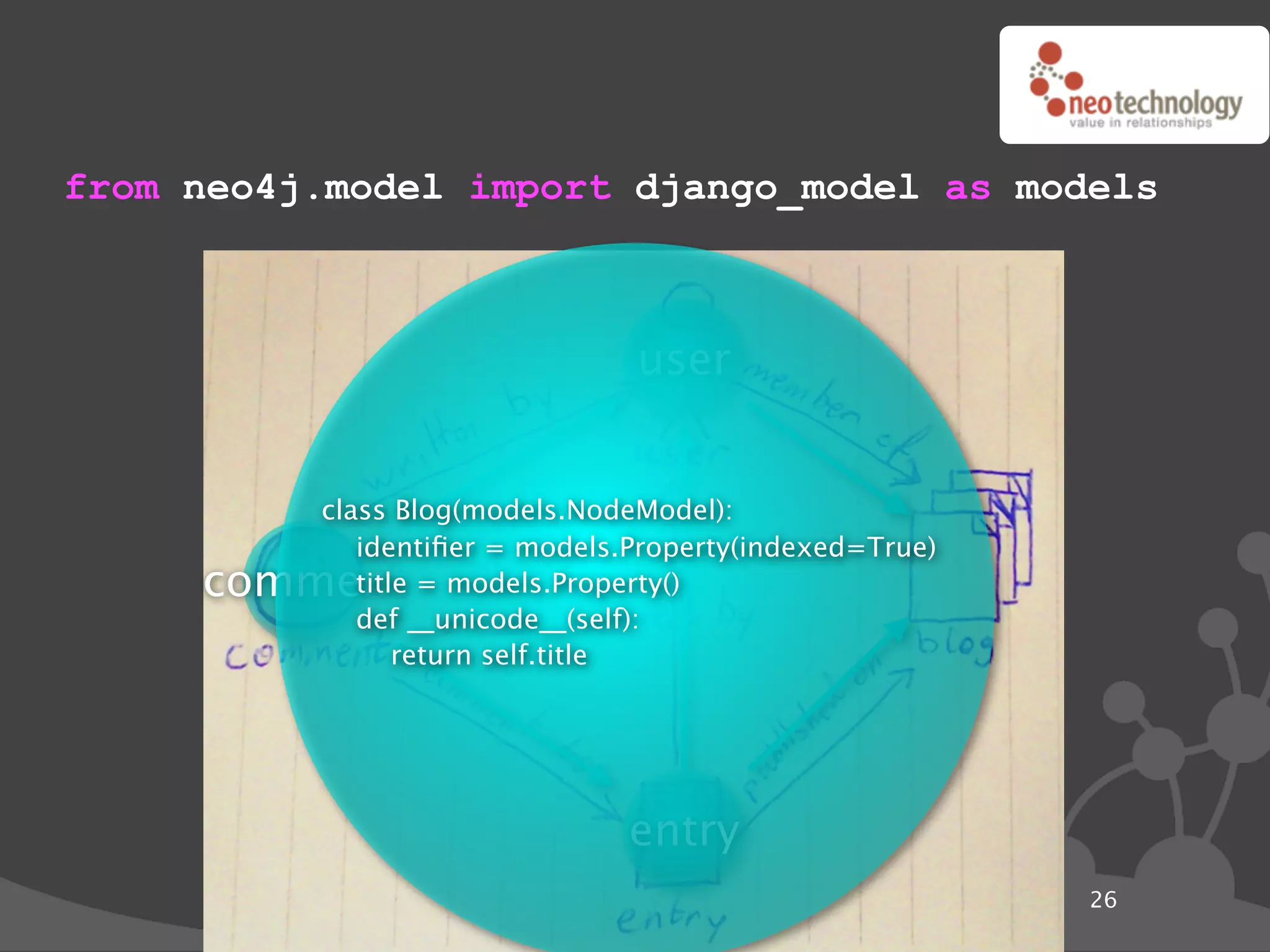
![Graph traversals name: “The Architect”
disclosure: “public”
name: “Thomas Anderson”
age: 29 name: “Cypher”
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ] Morpheus (@ depth=1)
order = neo4j.BREADTH_FIRST
stop = neo4j.STOP_AT_END_OF_GRAPH
returnable = neo4j.RETURN_ALL_BUT_START_NODE
for friend_node in Friends(mr_anderson):
print "%s (@ depth=%s)" % ( friend_node["name"],
friend_node.depth )
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-38-2048.jpg)
![Graph traversals name: “The Architect”
disclosure: “public”
name: “Thomas Anderson”
age: 29 name: “Cypher”
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ] Morpheus (@ depth=1)
order = neo4j.BREADTH_FIRST Trinity (@ depth=1)
stop = neo4j.STOP_AT_END_OF_GRAPH
returnable = neo4j.RETURN_ALL_BUT_START_NODE
for friend_node in Friends(mr_anderson):
print "%s (@ depth=%s)" % ( friend_node["name"],
friend_node.depth )
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-39-2048.jpg)
![Graph traversals name: “The Architect”
disclosure: “public”
name: “Thomas Anderson”
age: 29 name: “Cypher”
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ] Morpheus (@ depth=1)
order = neo4j.BREADTH_FIRST Trinity (@ depth=1)
stop = neo4j.STOP_AT_END_OF_GRAPH
Cypher (@ depth=2)
returnable = neo4j.RETURN_ALL_BUT_START_NODE
for friend_node in Friends(mr_anderson):
print "%s (@ depth=%s)" % ( friend_node["name"],
friend_node.depth )
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-40-2048.jpg)
![Graph traversals name: “The Architect”
disclosure: “public”
name: “Thomas Anderson”
age: 29 name: “Cypher”
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ] Morpheus (@ depth=1)
order = neo4j.BREADTH_FIRST Trinity (@ depth=1)
stop = neo4j.STOP_AT_END_OF_GRAPH
Cypher (@ depth=2)
returnable = neo4j.RETURN_ALL_BUT_START_NODE
Agent Smith (@ depth=3)
for friend_node in Friends(mr_anderson):
print "%s (@ depth=%s)" % ( friend_node["name"],
friend_node.depth )
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-41-2048.jpg)
![Graph traversals name: “The Architect”
disclosure: “public”
name: “Thomas Anderson”
age: 29 name: “Cypher”
last name: “Reagan”
KNOWS name: “Morpheus”
KNOWS KNOWS
rank: “Captain” CODED BY
LOVES occupation: “Total badass” KNOWS
KNOWS
name: “Trinity” disclosure: “secret”
name: “Agent Smith”
version: “1.0b”
since: “meeting the oracle” since: “a year before the movie”
language: “C++”
cooperates on: “The Nebuchadnezzar”
import neo4j
class Friends(neo4j.Traversal): # Traversals ! queries in Neo4j
types = [ neo4j.Outgoing.KNOWS ] Morpheus (@ depth=1)
order = neo4j.BREADTH_FIRST Trinity (@ depth=1)
stop = neo4j.STOP_AT_END_OF_GRAPH
Cypher (@ depth=2)
returnable = neo4j.RETURN_ALL_BUT_START_NODE
Agent Smith (@ depth=3)
for friend_node in Friends(mr_anderson):
print "%s (@ depth=%s)" % ( friend_node["name"],
friend_node.depth )
20](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-42-2048.jpg)
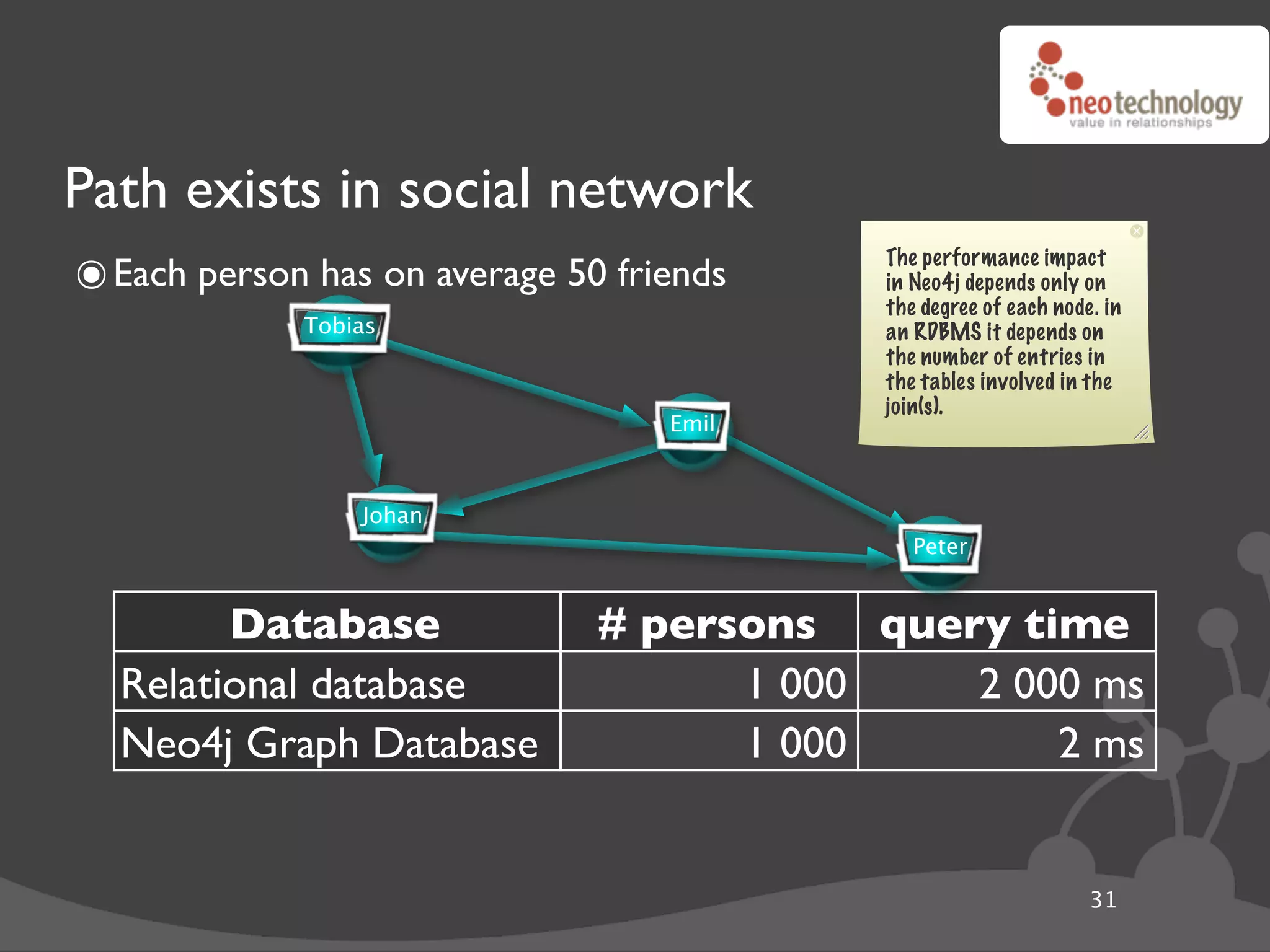
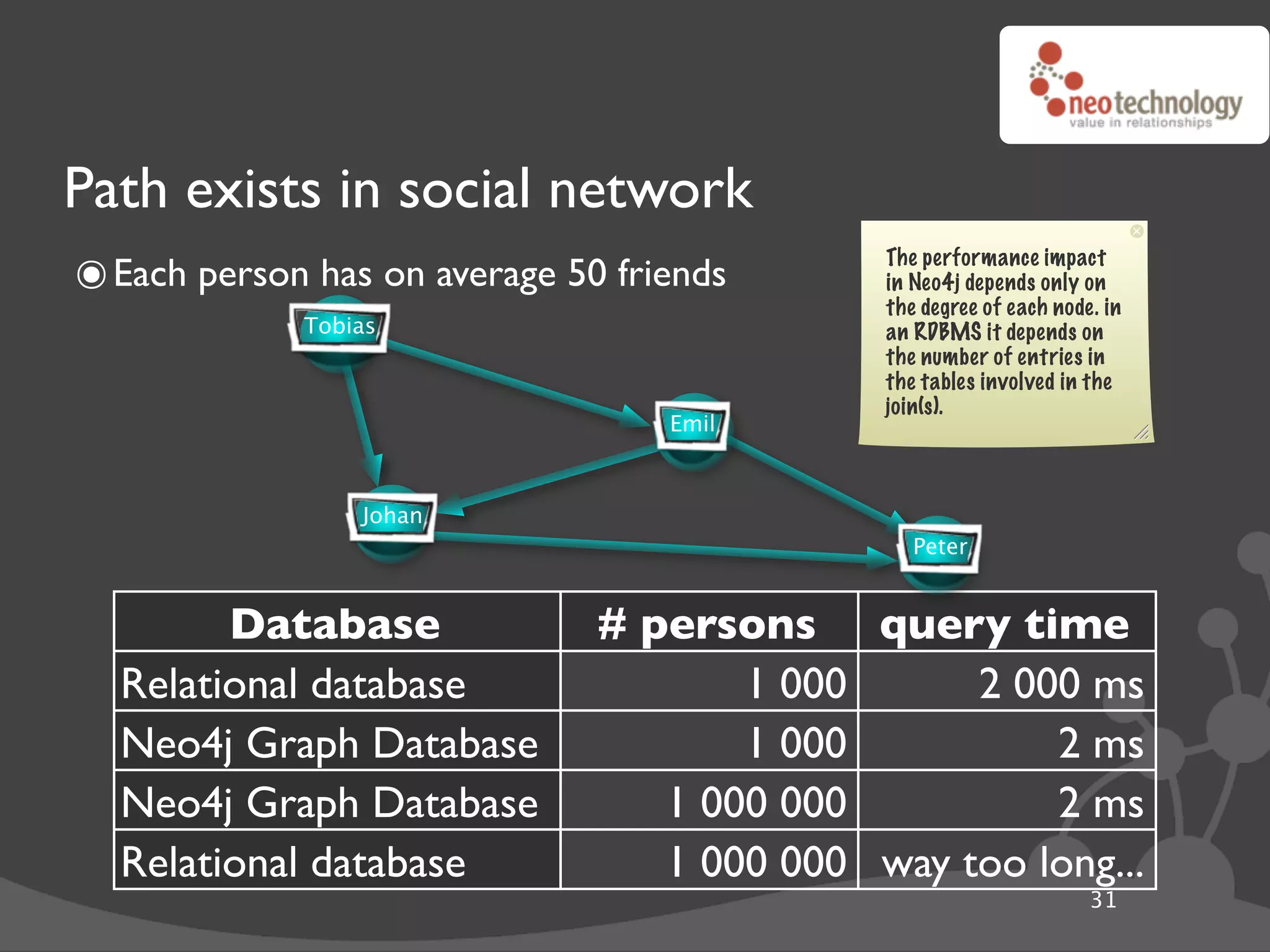
![Finding a place to start
๏ Traversals need a Node to start from
• QUESTION: How do I find the start Node?
• ANSWER:You use an Index
๏ Indexes in Neo4j are different from Indexes in Relational Databases
• RDBMSes use them for Joining
• Neo4j use them for simple lookup
index = graphDb.index["name"]
mr_anderson = index["Thomas Anderson"]
performTraversalFrom( mrAnderson )
21](https://image.slidesharecdn.com/djangoandneo4j-100721185000-phpapp02/75/Django-and-Neo4j-Domain-modeling-that-kicks-ass-43-2048.jpg)









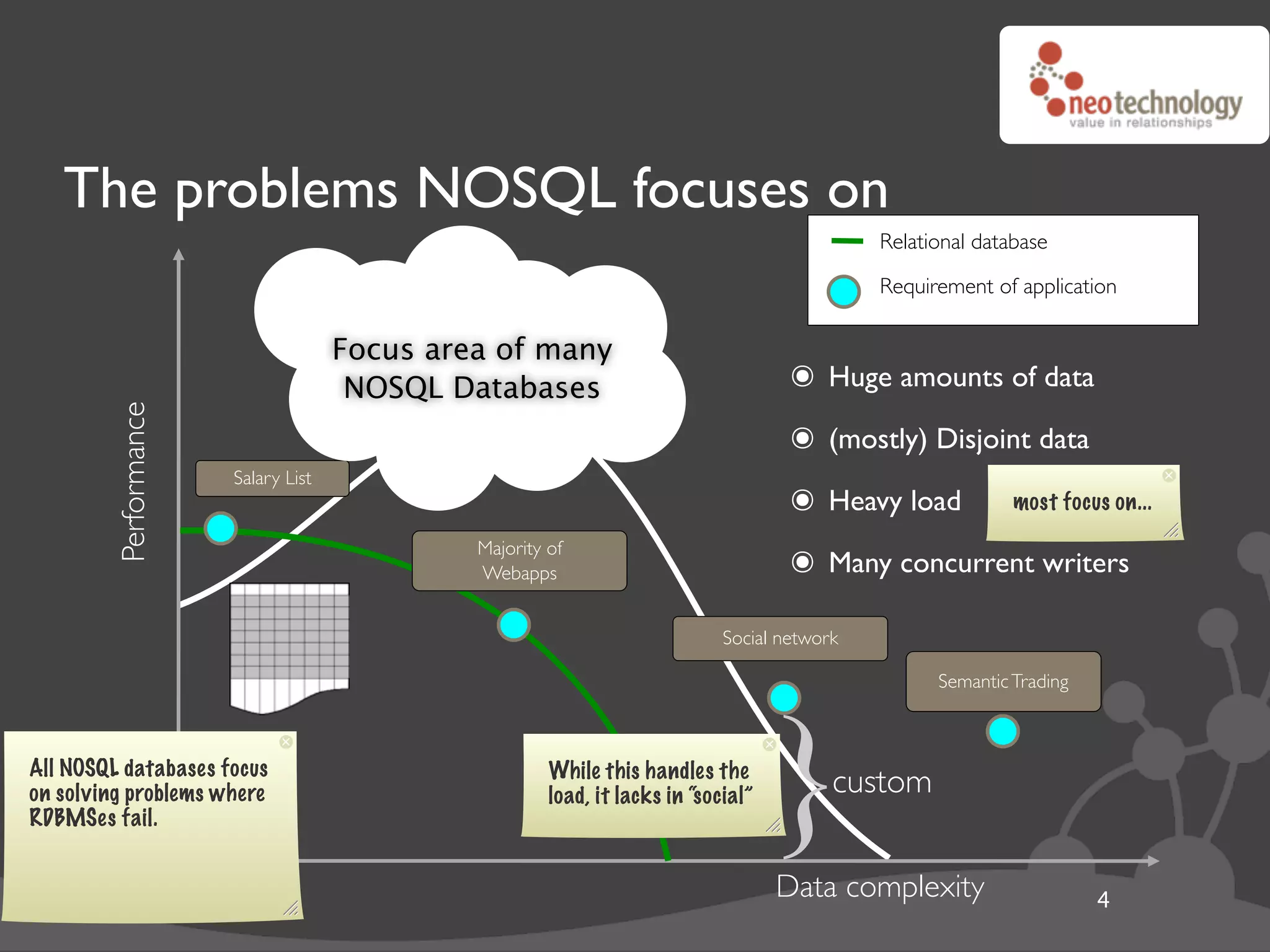
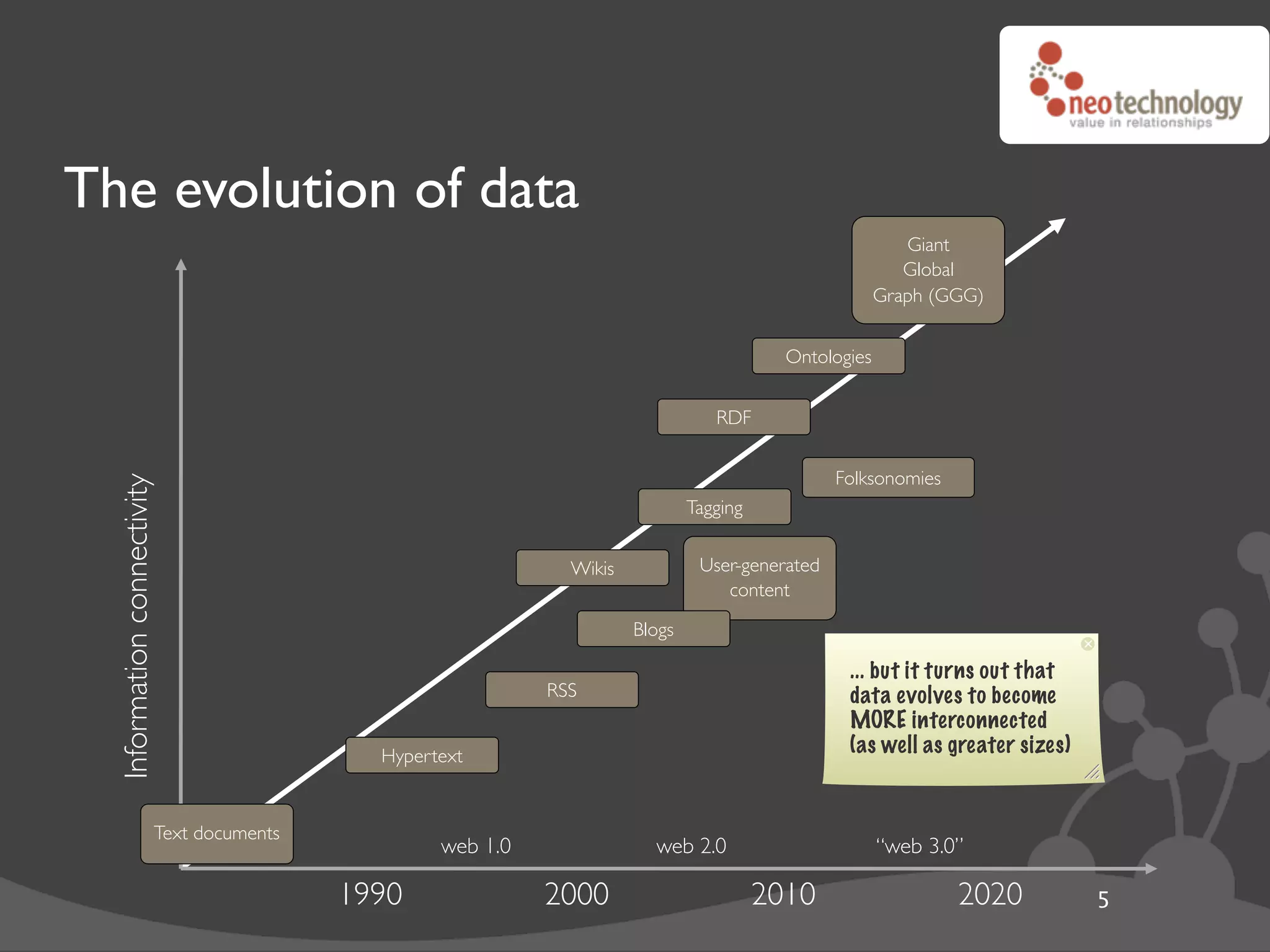
This document discusses Neo4j, a graph database that models connections between entities, addressing the limitations of traditional relational databases. It highlights its open-source nature, transactional capabilities, and high performance in handling complex relationships through a schema-free design. The document also provides examples of graph modeling and operations using Neo4j's API.








































































![[JavaOne 2011] Models for Concurrent Programming](https://cdn.slidesharecdn.com/ss_thumbnails/24881-modelsforconcurrentprogramming-111019034625-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















