This document provides an overview of a MongoDB workshop. It includes an agenda with topics like an overview of databases, what is MongoDB, MongoDB commands, sharding and replication in MongoDB, and a demo. The workshop is hosted by Vivian at ThoughtWorks for the audience of NYC Open Data and will be presented by Kannan Sankaran and Roman Kubiak.
![MONGODB WORKSHOP
{
meetup: “NYC Open Data”,
presenters: [“Kannan Sankaran”, “Roman Kubiak”],
host: “Vivian”,
location: “ThoughtWorks”,
audience: “You guys”
}](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-1-320.jpg)
![MONGODB WORKSHOP
{
meetup: “NYC Open Data”,
presenters: [“Kannan Sankaran”, “Roman Kubiak”],
host: “Vivian is awesome, THANK YOU”,
location: “ThoughtWorks is awesome, THANK YOU”,
audience: “You guys are awesome, THANK YOU”
}](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-2-320.jpg)













![…BUT IT IS MORE FLEXIBLE
{
{
_id: ObjectID(“12AB34CD56EF”),
name: “Ed Brown”,
orderDate: “2-1-2014”,
payments:
{
car: “100.50”,
hotel: “200”
}
_id: ObjectID(“12AB34CD56EF”),
name: “Ed Brown”,
orderDate: “2-1-2014”,
payments:
{
car: “100.50”,
hotel: “200”
},
tags: [“shirt”, “tie”]
}
}
THAT LOOKS LIKE A DOCUMENT
WITHIN ANOTHER DOCUMENT!
WHAT IS THIS? MULTIPLE VALUES
WITHIN A COLUMN?](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-18-320.jpg)



![WHAT IS JSON?
JAVASCRIPT OBJECT NOTATION
NAME-VALUE PAIRS
{
{
}
vehicle: “car”,
make: “Malibu”,
color: “blue”
}
name: “Kannan”,
gender: “male”,
favorites:
{
color: “blue”
},
interests: [“MongoDB”, “R”]](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-22-320.jpg)
![MONGODB DOCUMENT
{
_id: ObjectID(“12AB34CD56EF”),
name: “Kannan”,
gender: “male”,
favorites:
{
color: “blue”
},
interests: [“MongoDB”, “R”],
date: new Date()
}](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-23-320.jpg)

![A GROUP OF DOCUMENTS
{
SIMILAR
{
_id: ObjectID(“34AB34CD56EF”),
name: “Ed Brown”,
orderDate: “2-1-2014”,
tags: [“shirt”, “tie”]
_id: ObjectID(“12AB34CD56EF”),
name: “Ed Brown”,
orderDate: “2-1-2014”
}
{
_id: ObjectID(“78AB34CD56EF”),
name: “Roman Ku”,
orderDate: “2-1-2014”
}
{
_id: ObjectID(“56AB34CD56EF”),
name: “Eva Green”,
orderDate: “2-1-2014”
DIFFERENT
}
{
_id: ObjectID(“90AB34CD56EF”),
name: “Roman Ku”,
orderDate: “2-1-2014”,
payments:
{ car: “100.50”, hotel: “200” }
}
{
VERY DIFFERENT
{
_id: ObjectID(“35AB34CD56EF”),
name: “Ed Brown”,
orderDate: “2-1-2014”
}
{
_id: ObjectID(“79AB34CD56EF”),
vehicle: “car”,
make: “Malibu”,
color: “blue”
}
{
_id: ObjectID(“57AB34CD56EF”),
name: “Eva Green”,
orderDate: “2-1-2014”,
tags: [“shirt”, “tie”]
_id: ObjectID(“13AB34CD56EF”),
name: “Eva Green”,
orderDate: “2-1-2014”
}
}
}](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-25-320.jpg)
















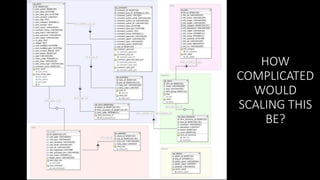









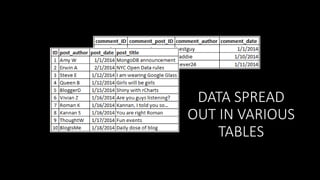
![WP_POSTS
STACKING THE DATA
{
NO NEED TO
JOIN
}
WP_COMMENTS
_id: 1,
post_author: “Amy W”,
post_date: “1/1/2014”,
comments: [{
comment_author: “bestguy”,
comment_date: “1/1/2014”
},{
comment_author: “baddie”,
comment_date: “1/10/2014”
},{
comment_author: “clever24”,
comment_date: “1/11/2014”
}]](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-53-320.jpg)
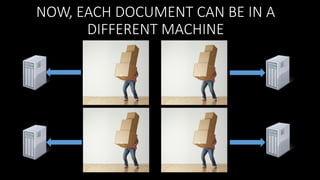


![{
BUT SINGLE DOCUMENT
UPDATE IS ATOMIC
_id: 1,
post_author: “Amy W”,
post_date: “1/1/2014”,
comments: [{
comment_author: “bestguy”,
comment_date: “1/1/2014”
},{
comment_author: “baddie”,
comment_date: “1/10/2014”
},{
comment_author: “clever24”,
comment_date: “1/11/2014”
}]
}](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-57-320.jpg)






























![SHARDING WP_POSTS COLLECTION
{
_id: 1,
post_author: “Amy W”,
post_date: “1/1/2014”,
comments: [{
comment_author: “bestguy”,
comment_date: “1/1/2014”
},{
comment_author: “baddie”,
comment_date: “1/10/2014”
},{
comment_author: “clever24”,
comment_date: “1/11/2014”
}]
}
SHARD KEY](https://image.slidesharecdn.com/mongodbworkshop-v5-140209224950-phpapp01/85/MongoDB-Workshop-89-320.jpg)