Downloaded 420 times





![Cypher Example
CREATE (n {name: {value}})
CREATE (n)-[r:KNOWS]->(m)
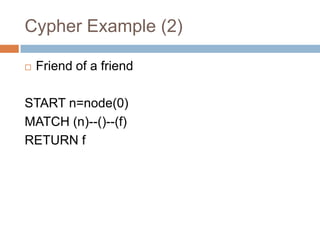
START
[MATCH]
[WHERE]
RETURN [ORDER BY] [SKIP] [LIMIT]](https://image.slidesharecdn.com/neo4j-graphdatabaseforrecommendations-130531021030-phpapp02/85/Neo4j-graph-database-for-recommendations-7-320.jpg)




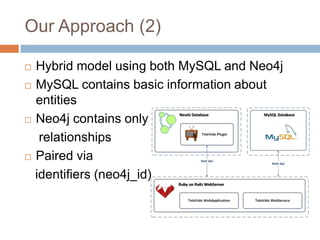



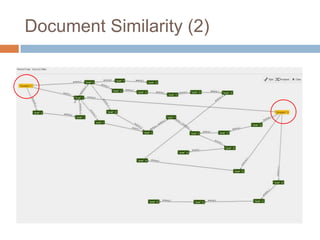




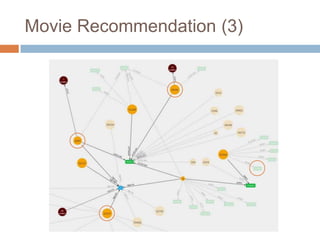

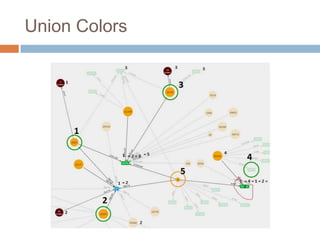
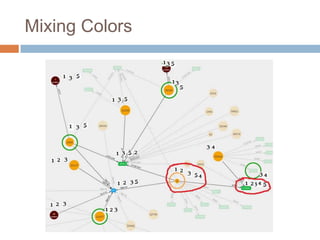
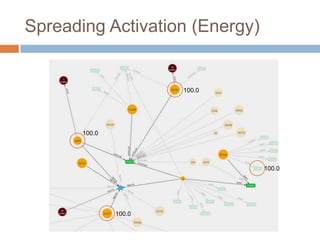
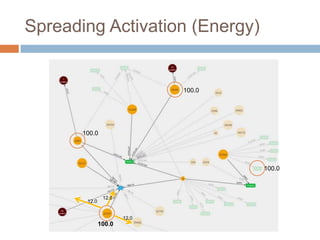
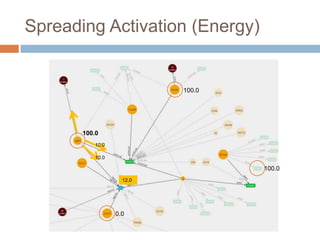
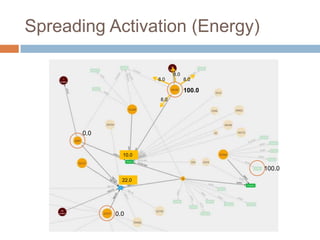
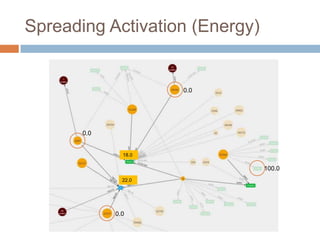








This document discusses using Neo4j, a graph database, for recommendations. It describes modeling data as graphs in Neo4j and developing recommendation algorithms and plugins for it, such as for document similarity, movie recommendations, and restricting recommendations to a subgraph. An example application called TeleVido.tv is also mentioned that provides media content recommendations using Neo4j.






















![[QCon.ai 2019] People You May Know: Fast Recommendations Over Massive Data](https://cdn.slidesharecdn.com/ss_thumbnails/qconaisf2019-pymk-190424130904-thumbnail.jpg?width=640&height=640&fit=bounds)



























































