

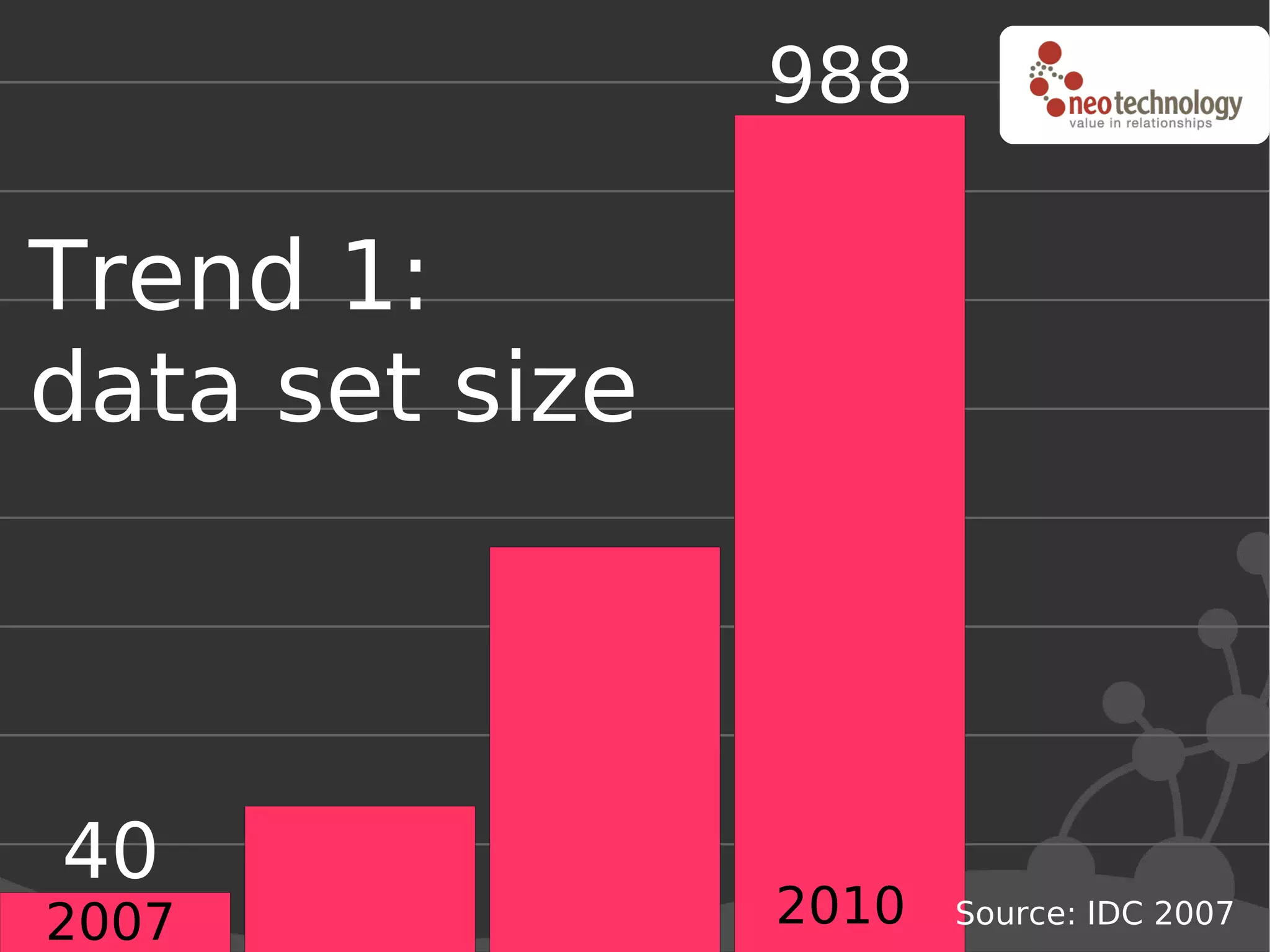
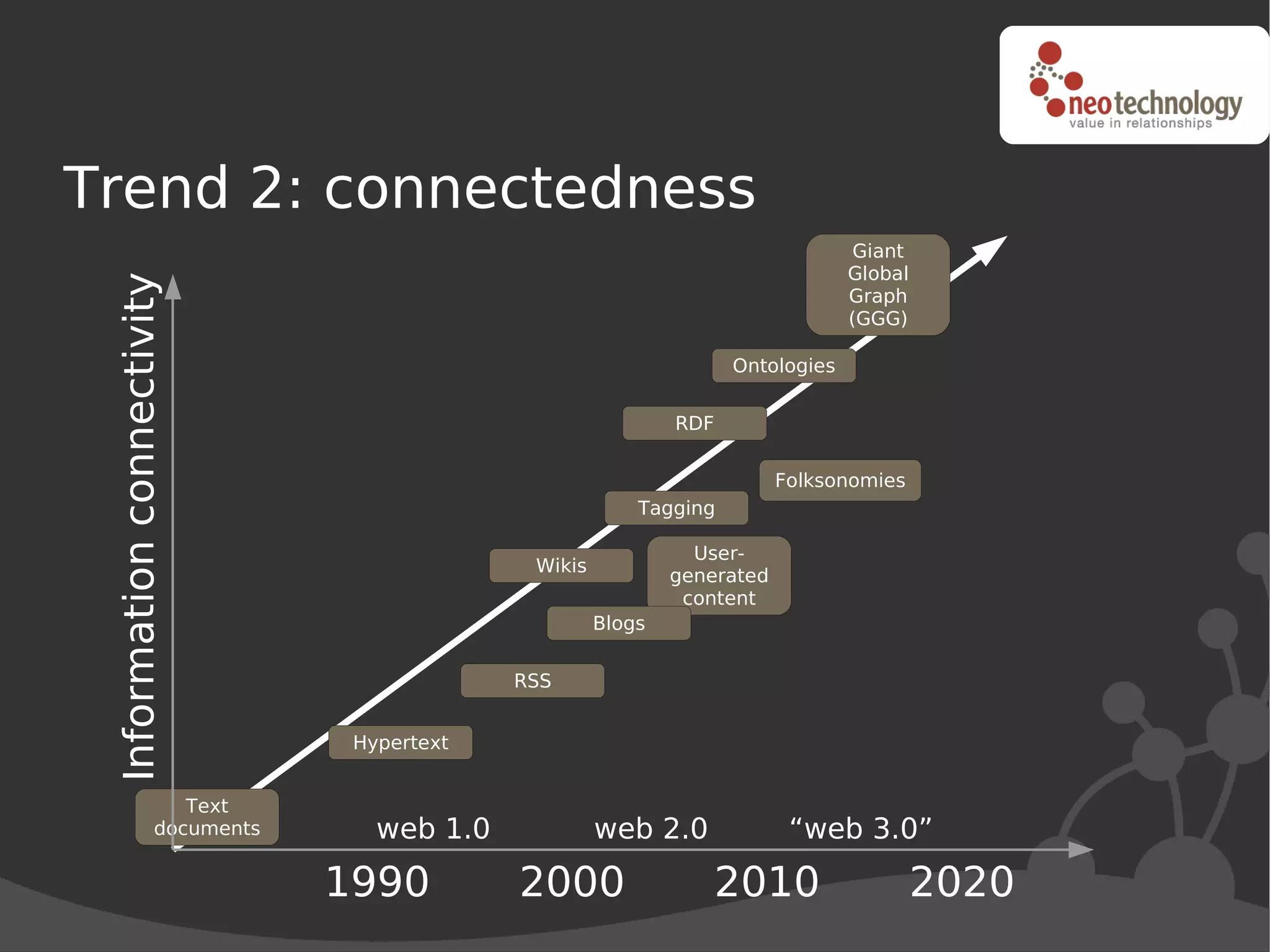

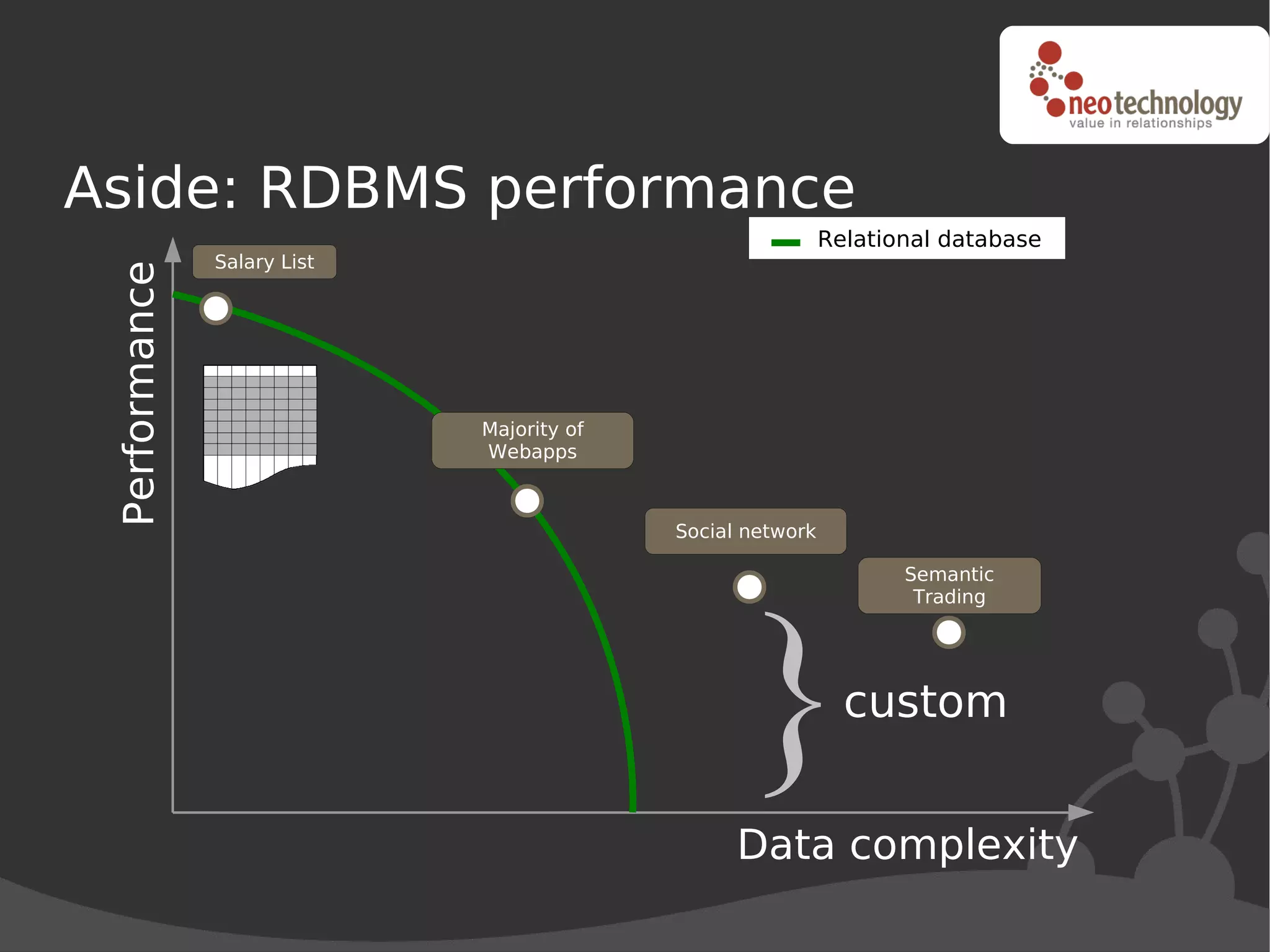
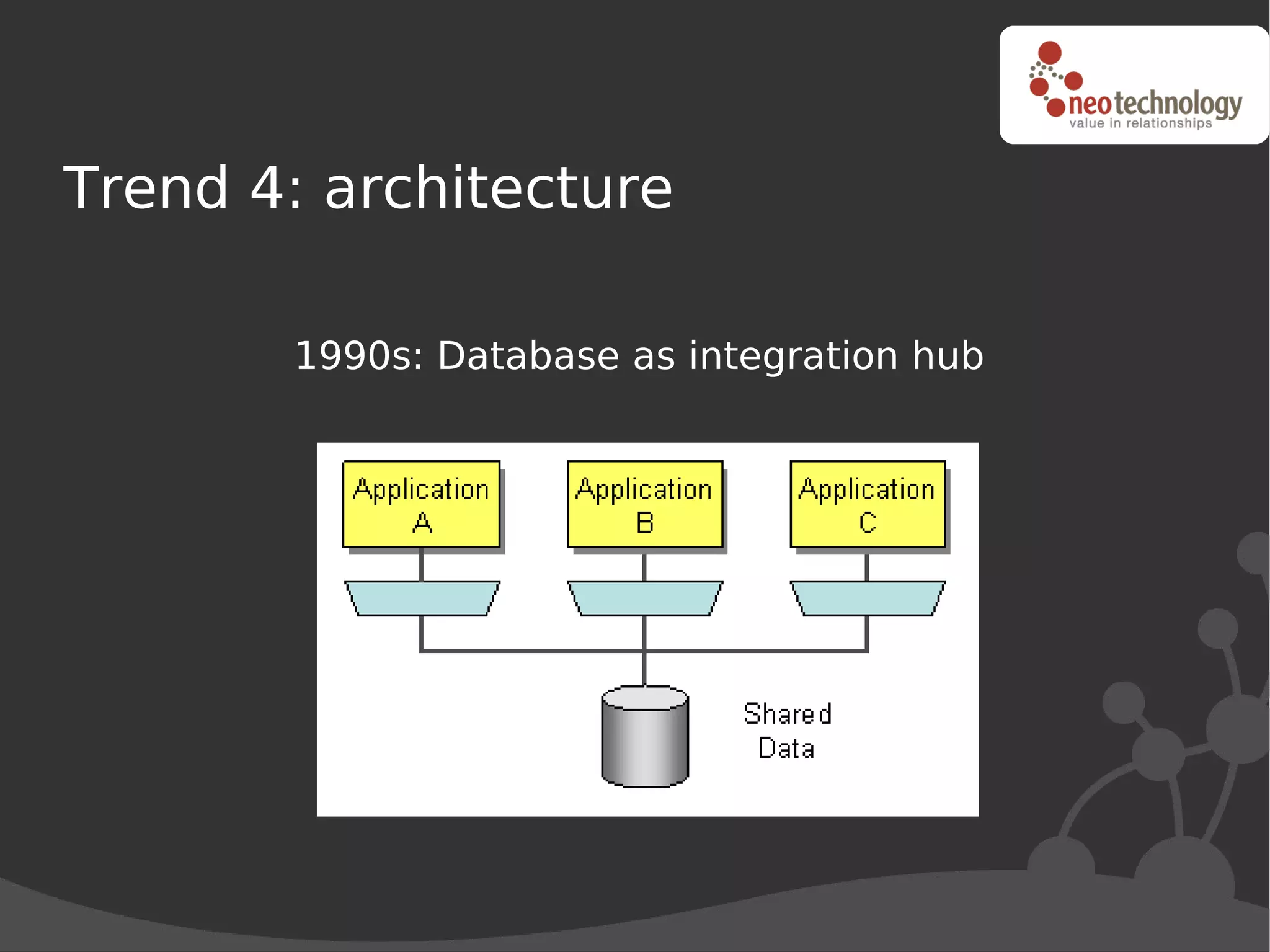
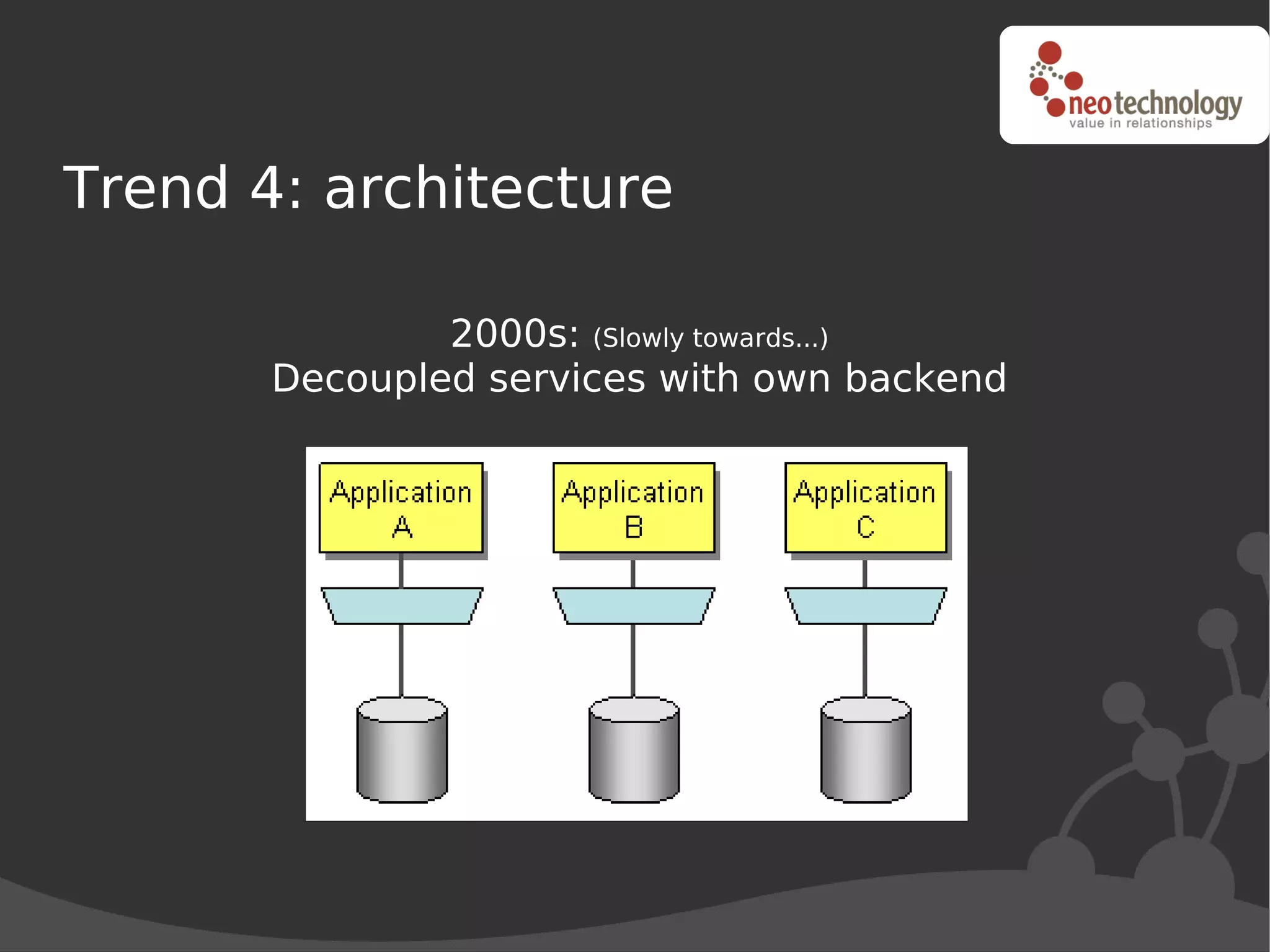






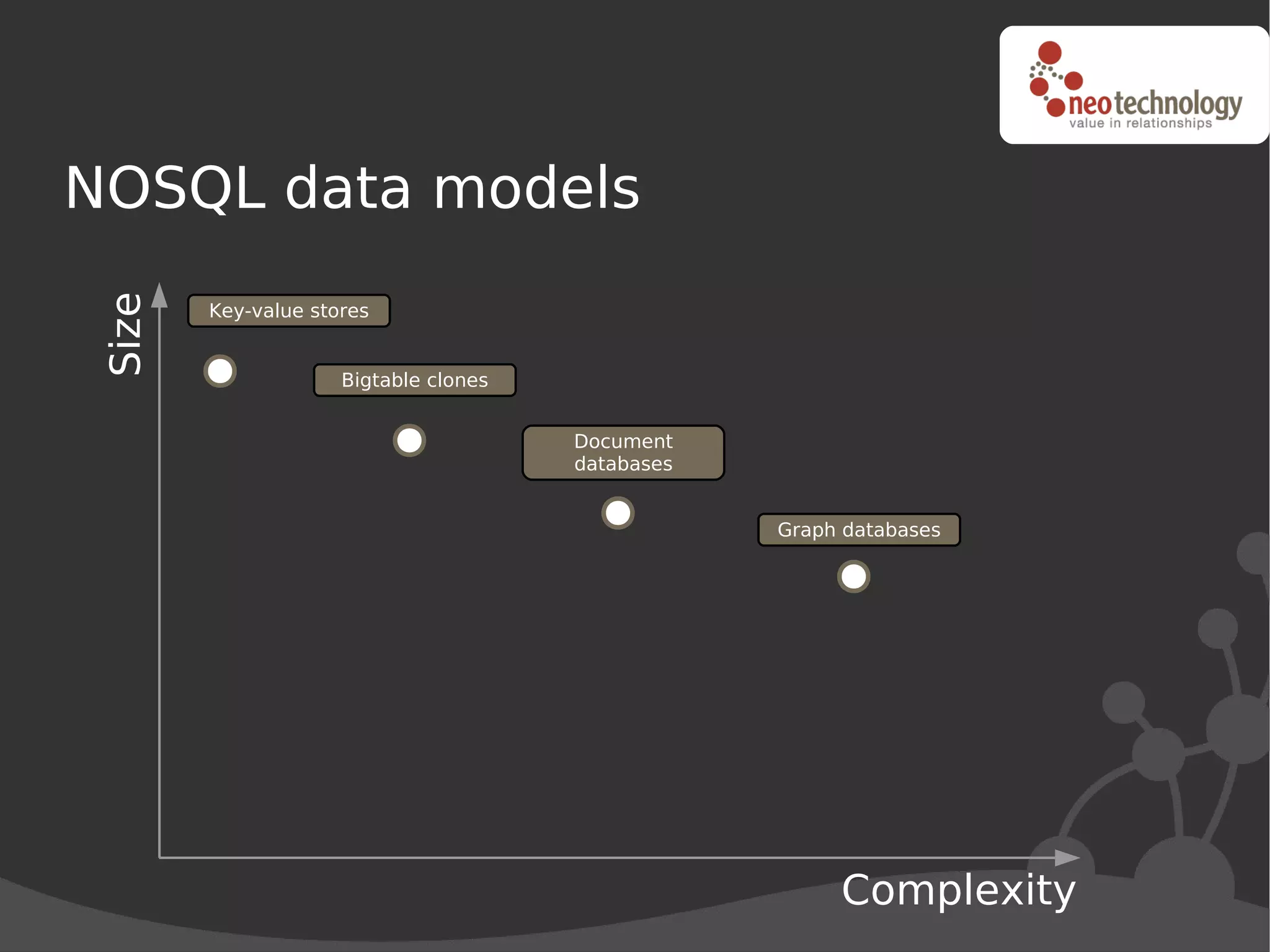
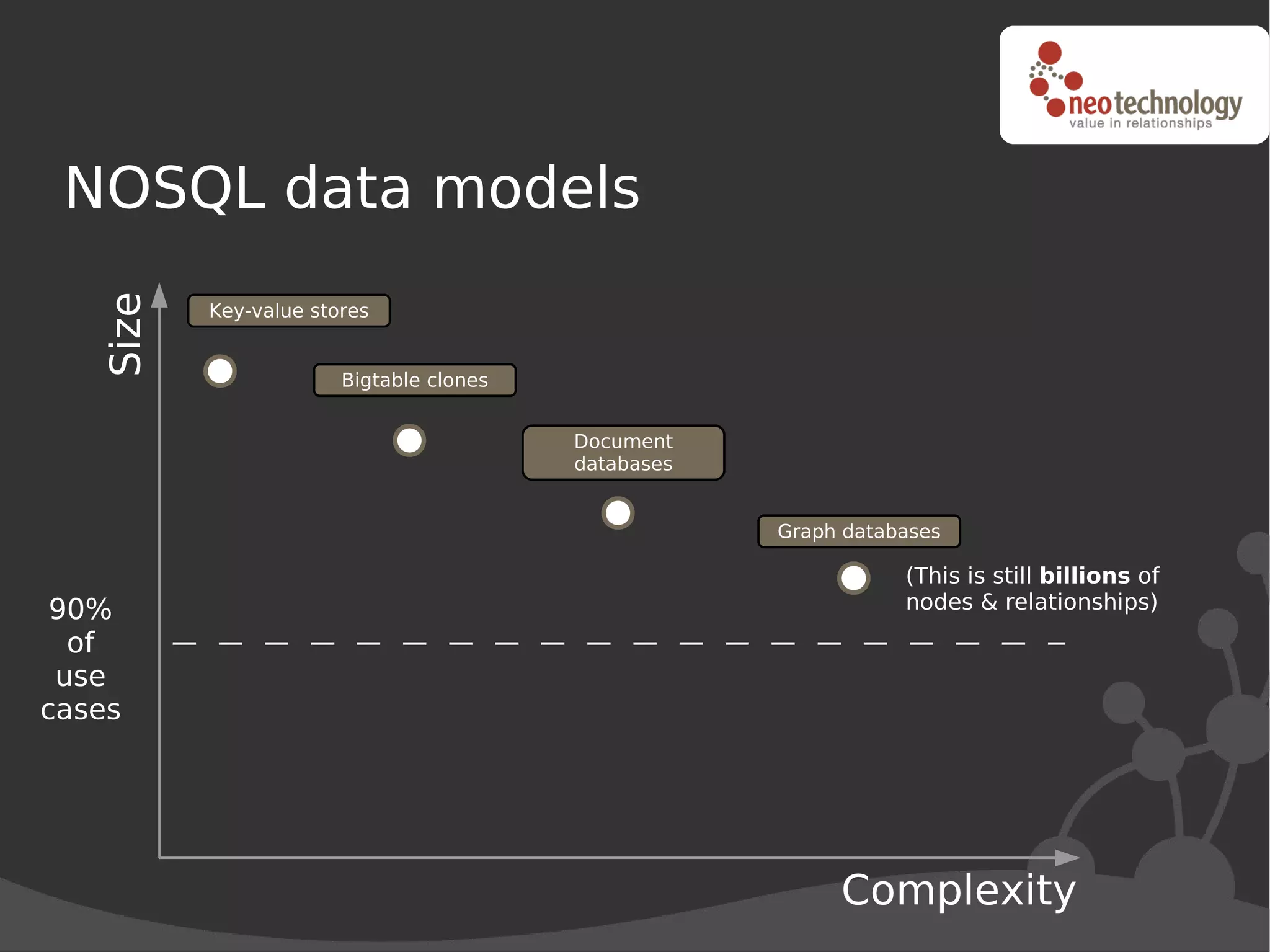
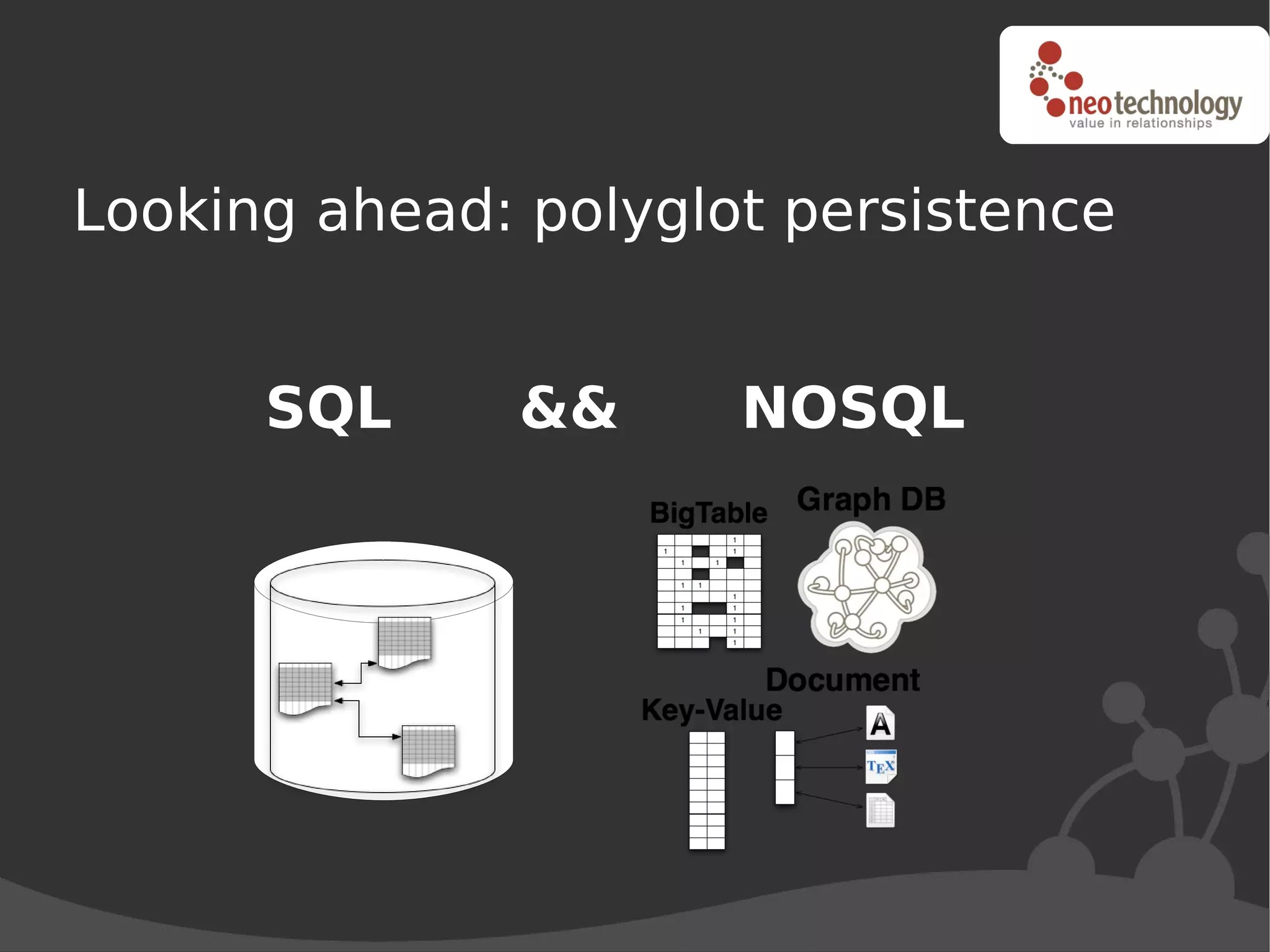


This document discusses trends driving the emergence of NoSQL databases and provides an overview of NoSQL. The key trends include: (1) rapidly increasing data set sizes, (2) greater connectivity of data, and (3) more semi-structured and decentralized content. These trends have challenged the performance and architecture of traditional relational databases. NoSQL databases emerged in response and come in four main categories: key-value stores, BigTable clones, document databases, and graph databases. Each has a different data model suited to different types of use cases. Looking ahead, the best approach may be "polyglot persistence" using both SQL and NoSQL solutions.







































































