Downloaded 242 times

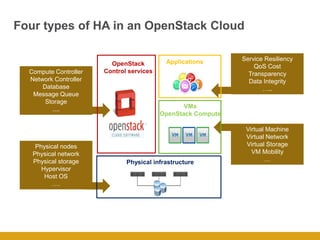


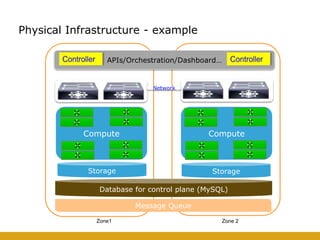


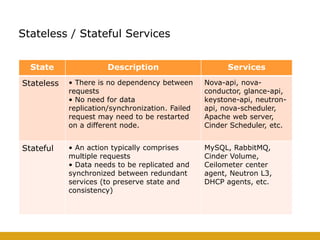





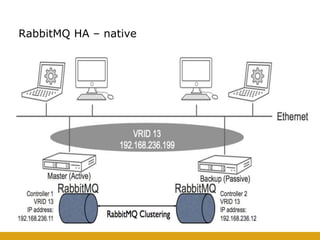


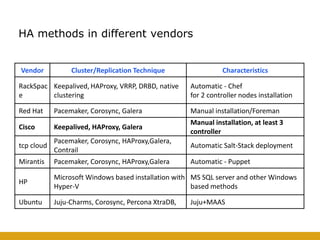
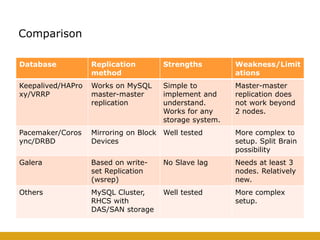
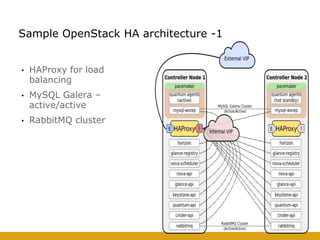
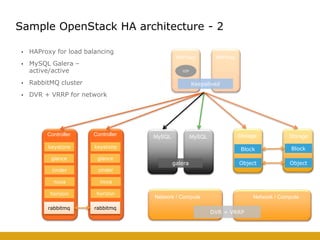


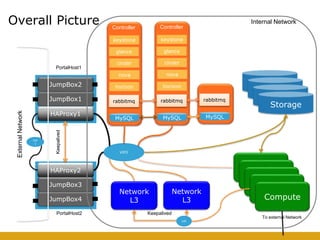

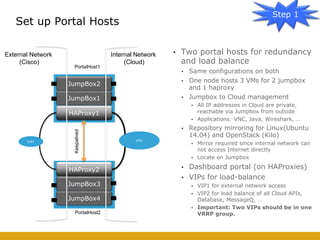
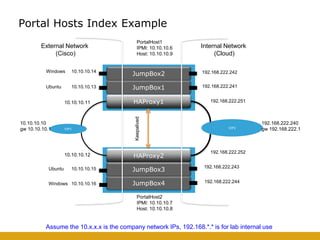











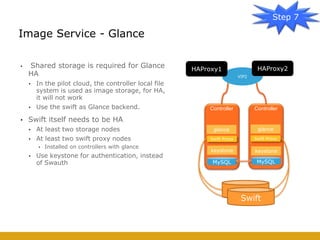
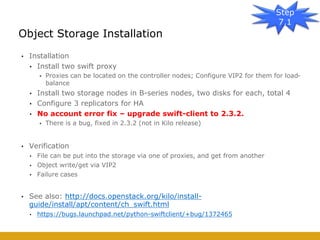
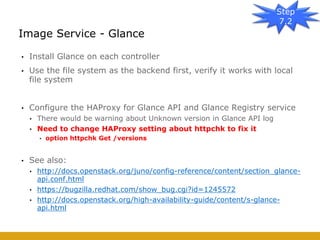



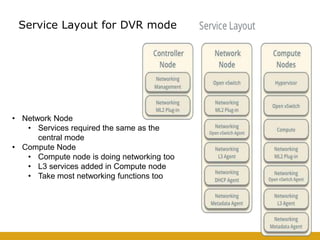



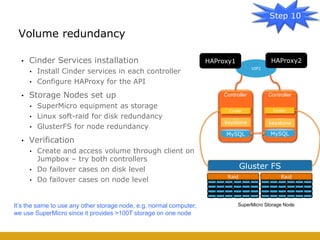




This document details the design and deployment of high availability (HA) for OpenStack cloud control services, outlining various types of HA configurations including stateless and stateful services, and the use of technologies such as keepalived, HAProxy, and MySQL Galera for load balancing and redundancy. It describes the architecture featuring multiple physical nodes and detailed deployment steps for setting up a resilient OpenStack environment with components like controllers, databases, and storage systems. Additionally, it addresses challenges and configurations related to networking, including the use of VRRP for virtual IP management and various vendor-specific implementation techniques.


![[OpenStack] 공개 소프트웨어 오픈스택 입문 & 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/opensource-skimmingopenstackwithkoreausergroup-180824144737-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=640&height=640&fit=bounds)






![[오픈소스컨설팅] 스카우터 사용자 가이드 2020](https://cdn.slidesharecdn.com/ss_thumbnails/2020scouteruserguide-200122014357-thumbnail.jpg?width=640&height=640&fit=bounds)





































































