Download as ODP, PPTX



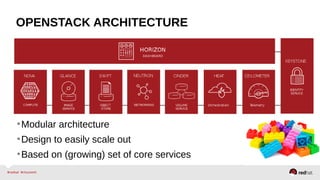
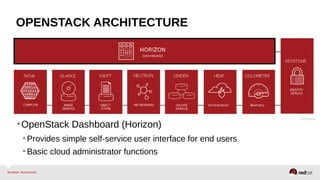
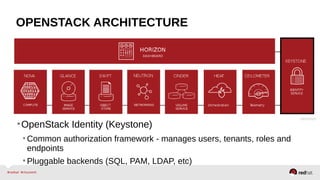
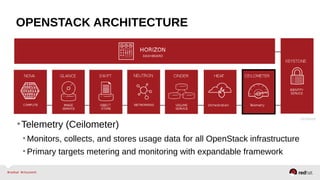
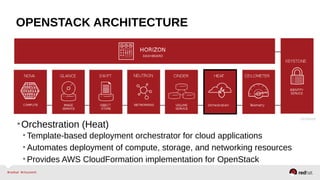
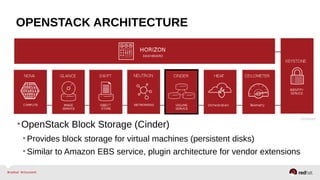
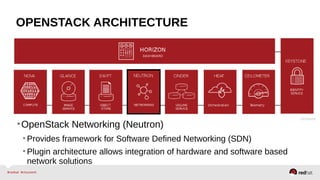
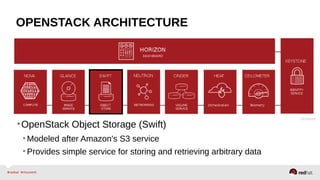
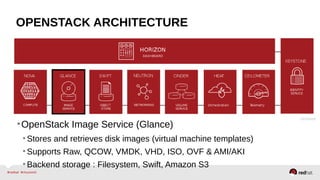
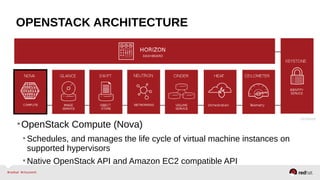

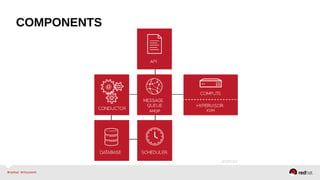


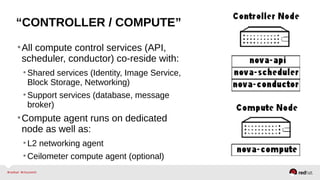
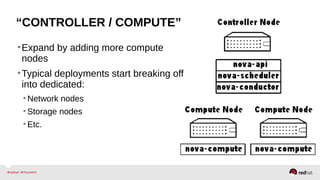


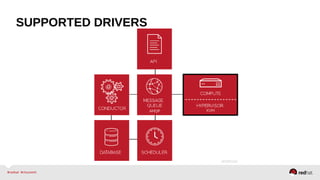
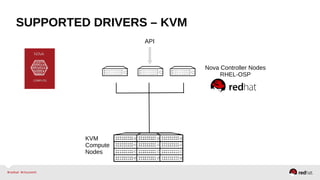
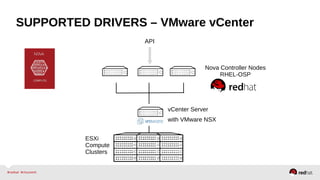










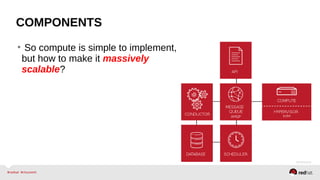
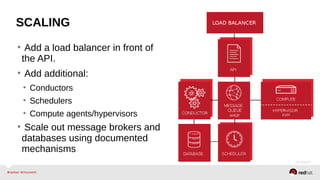
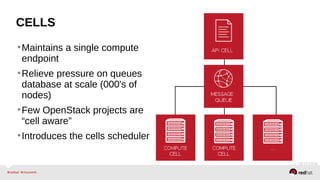
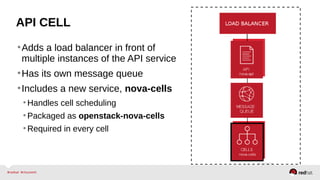
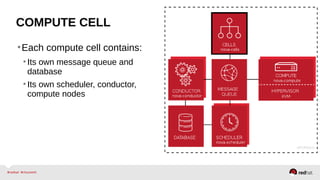



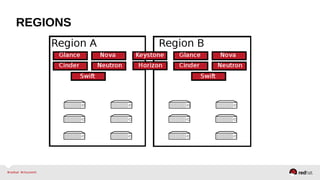




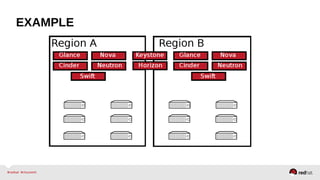
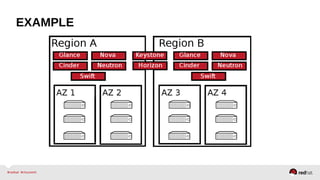
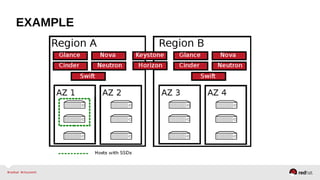
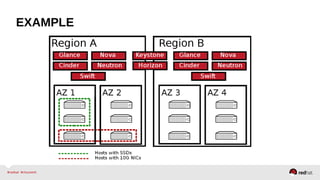
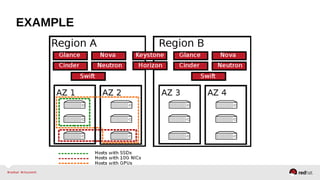
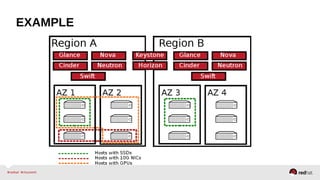











The document provides a comprehensive overview of OpenStack architecture and components, focusing on the compute services managed by Nova. It discusses instance lifecycle, scaling options, and the segregation of compute resources, emphasizing best practices and new features. Additionally, it outlines the integration with Red Hat Enterprise Linux and support for various drivers, presenting a detailed technical guide for managing cloud infrastructure.





































![[Rakuten TechConf2014] [F-4] At Rakuten, The Rakuten OpenStack Platform and B...](https://cdn.slidesharecdn.com/ss_thumbnails/f4openstackrakutentechnologyconference20141025-141105211349-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)











































