Download as PDF, PPTX








![OPENSTACK COMPUTE 101OPENSTACK COMPUTE 101
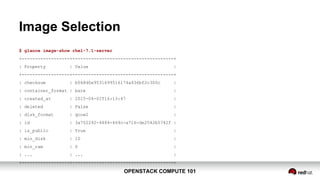
Authentication$ cat keystonerc_demo
export OS_USERNAME=demo
export OS_TENANT_NAME=demo
export OS_PASSWORD=c8500b92ed7f4ed0
export OS_AUTH_URL=http://93.184.216.34:5000/v2.0/
export PS1='[u@h W(keystone_demo)]$ '
$ source keystonerc_demo](https://image.slidesharecdn.com/openstacksummit2015vancouver-compute101-150519144933-lva1-app6891/85/Compute-101-OpenStack-Summit-Vancouver-2015-11-320.jpg)
![OPENSTACK COMPUTE 101OPENSTACK COMPUTE 101
Instance Creation
● Instance creation achieved using nova boot command.
● Minimal set of arguments include selecting a flavor and
image:
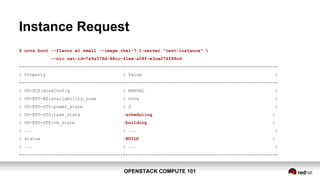
$ nova boot --flavor <flavor> --image <image>
[--nic net-id=<net-id>] <name>
● Flavor determines the “size” of an instance.
● Image determines the disk image used to boot the
instance.](https://image.slidesharecdn.com/openstacksummit2015vancouver-compute101-150519144933-lva1-app6891/85/Compute-101-OpenStack-Summit-Vancouver-2015-12-320.jpg)


![OPENSTACK COMPUTE 101OPENSTACK COMPUTE 101
What just happened?
● Retrieved token and endpoints from Keystone API
○ Compute end-point of the form: http[s]://<ip>:8774/v2/%(tenant_id)s
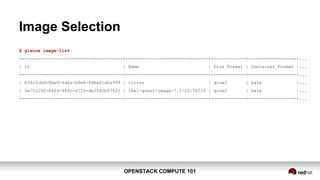
● Confirm image identifier:
○ Retrieved list of available images from Nova API
■ http://93.184.216.34:8774/v2/fc50f6843ba644baaae2af0398e7f04e/images
○ Retrieved specific image detail from Nova API
■ .../v2/fc50f6843ba644baaae2af0398e7f04e/images/3a752292-4484-469c-a716-de2542b5742f
● Confirm flavor identifier:
○ Retrieved list of available flavors from Nova API
■ ../v2/fc50f6843ba644baaae2af0398e7f04e/flavors
○ Retrieved specific flavor detail from Nova API
■ ../v2/fc50f6843ba644baaae2af0398e7f04e/flavors/2](https://image.slidesharecdn.com/openstacksummit2015vancouver-compute101-150519144933-lva1-app6891/85/Compute-101-OpenStack-Summit-Vancouver-2015-20-320.jpg)
![OPENSTACK COMPUTE 101OPENSTACK COMPUTE 101
What just happened? (cont.)
● User request was sent to the compute endpoint in
JSON format:
{"server":
{"name": "test-instance",
"imageRef": "3a752292-4484-469c-a716-de2542b5742f",
"flavorRef": "2", "max_count": 1, "min_count": 1,
"networks": [{"uuid": "7a9a376d-88cc-41ae-a08f-e3ca274f88cd"}]
}
}
● Request is picked up by nova-api service.](https://image.slidesharecdn.com/openstacksummit2015vancouver-compute101-150519144933-lva1-app6891/85/Compute-101-OpenStack-Summit-Vancouver-2015-21-320.jpg)


![OPENSTACK COMPUTE 101OPENSTACK COMPUTE 101
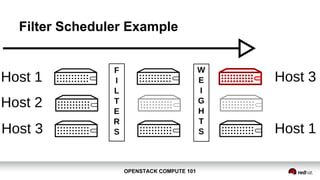
Filter Scheduler Example (cont.)
● Running with debug=True:
[req-... None] Starting with 3 host(s)
[req-... None] Filter RetryFilter returned 3 host(s)
[req-... None] Filter AvailabilityZoneFilter returned 3 host(s)
[req-... None] Filter RamFilter returned 2 host(s)
...
[req-... None] Filtered [(localhost.localdomain, localhost.localdomain)
ram:3208 disk:7168 io_ops:0 instances:1] _schedule ...
[req-... None] Weighed [ WeighedHost [host: (localhost.localdomain,
localhost.localdomain) ram:3208 disk:7168 io_ops:0 instances:1, weight:
1.0]] ...](https://image.slidesharecdn.com/openstacksummit2015vancouver-compute101-150519144933-lva1-app6891/85/Compute-101-OpenStack-Summit-Vancouver-2015-25-320.jpg)








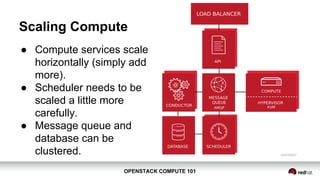
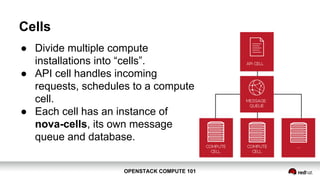
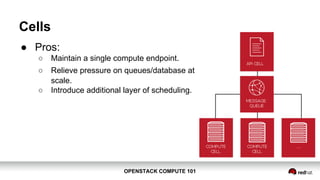
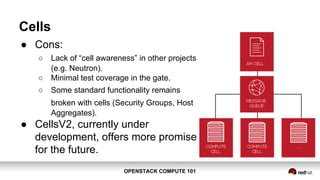


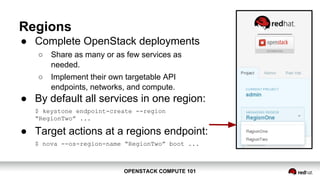





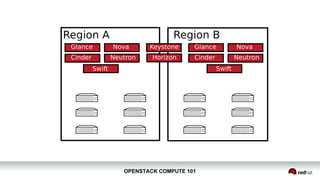
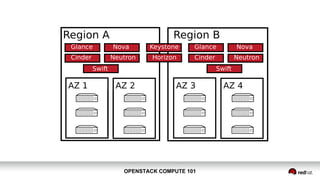
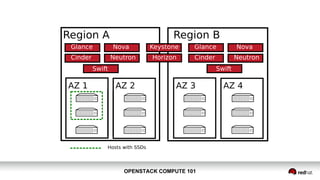
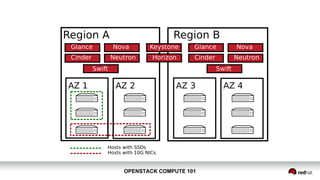
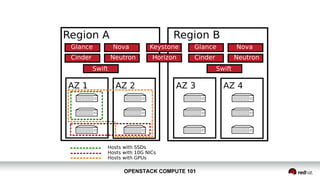













OpenStack Compute 101 provides an overview of OpenStack, focusing on its modules for infrastructure-as-a-service (IaaS) and the instance lifecycle management through the Nova component. Key topics include scheduling, compute drivers, resource segregation, and new features introduced in the Kilo release, such as API microversions for backward compatibility. The document emphasizes scaling compute services, understanding flavors and images, and the importance of logical groupings like regions, host aggregates, and availability zones.





![[OpenInfra Days Korea 2018] (Track 3) - CephFS with OpenStack Manila based on...](https://cdn.slidesharecdn.com/ss_thumbnails/36openinfra-2018-naver-cephfs-180704055415-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)












![[2015-11월 정기 세미나]K8s on openstack](https://cdn.slidesharecdn.com/ss_thumbnails/k8sonopenstack-151127132857-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[오픈소스컨설팅]오픈스택에 대하여](https://cdn.slidesharecdn.com/ss_thumbnails/random-151125103039-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)















































