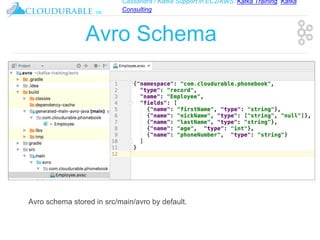
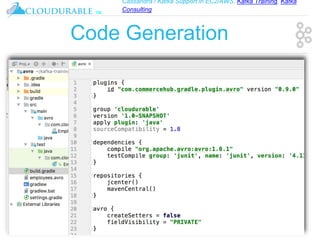
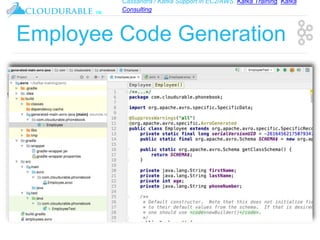
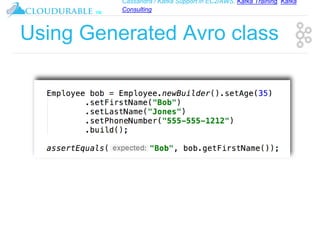
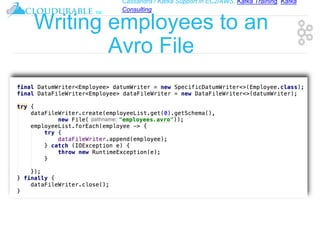
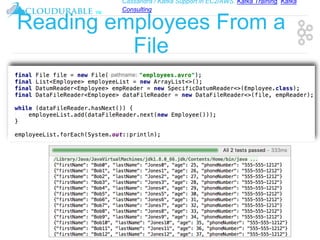
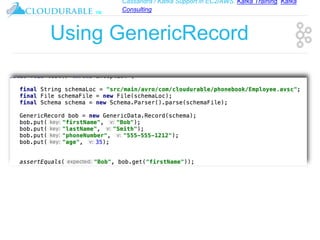
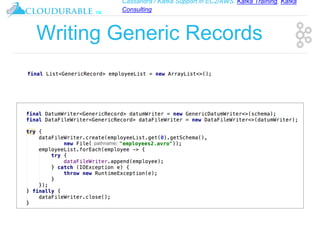
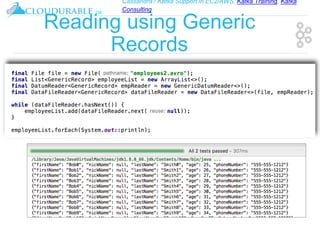
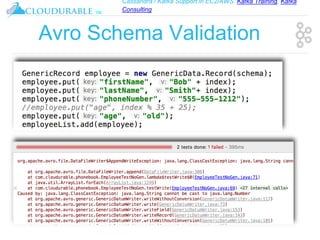
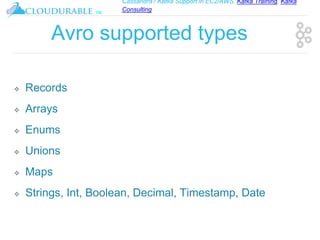
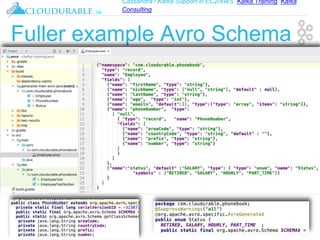
The document discusses support for Apache Kafka and Cassandra in AWS EC2, highlighting Kafka training and consulting services. It provides an overview of Apache Avro as a data serialization system, including its support for schemas, ease of use, and types. The document emphasizes Avro's efficiency in data handling and its capability for schema evolution.






![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















