Downloaded 54 times








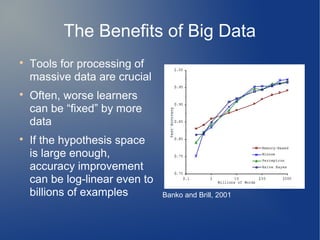









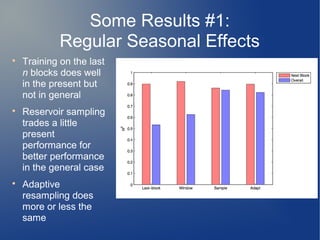
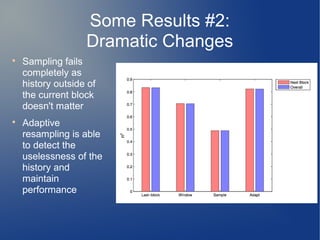



The document presents insights from Charles Parker of BigML on the challenges and research directions in large-scale machine learning. It covers issues like data processing speed, assumptions in data distribution, and new complexities introduced by big data, particularly 'slow arrival' scenarios where data does not arrive all at once. The discussion emphasizes the importance of adapting algorithms and methodologies to effectively handle varying data conditions and invites feedback on these preliminary observations.












































































