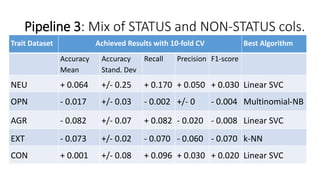
The document discusses predicting personality traits from Facebook statuses using machine learning techniques. It presents the goals of applying stylometry and natural language processing to a dataset of Facebook statuses labeled with Big Five personality traits. The methodology uses supervised machine learning algorithms like Naive Bayes and k-NN with features extracted from the statuses like word counts and part-of-speech tags. Baseline models using only the status text or derived features performed poorly. Combining status text with other features in a pipeline improved performance slightly but results were still limited by hardware and computational constraints.







![Extracted features from statuses
5 Labels
from ODS
Feature from
ODS
Extracted ones
Lexical (6) Character (8)
cNEU
STATUS
# functional words string length
lexical diversity [0-1]
# words # dots
# commas
cAGR
# personal pronouns
smileys
# semicolons
# colons
cOPN
Parts-of-speech Tags # *PROPNAME*
cCON
Bag-of-words (ngrams) average word length
cEXT](https://image.slidesharecdn.com/finalcustlingprofiling-160226163538/85/Customer-Linguistic-Profiling-8-320.jpg)
![Splitting dataset using stratified k-fold CV
• Create 5 trait datasets based on our labels
• Use stratified k-fold cross-validation to split into the training and testing set
>>> train_X, test_X, train_Y, test_Y =
sk.cross_validation.train_test_split(agr[:,1:9],
agr["cAGR"],
train_size = 0.66, stratify = agr["cAGR"],
random_state = 5152)](https://image.slidesharecdn.com/finalcustlingprofiling-160226163538/85/Customer-Linguistic-Profiling-9-320.jpg)

![Learning and predicting
• Head-on approach: Classifiers only
# Assumption: features are numeric values only
classifier = MultinomialNB()
classifier.fit(train_X, train_Y).predict(test_X) # results in a prediction for test_X
• But: “Status” is a string and not numeric
nb_pipeline= Pipeline([
('vectorizer_tfidf', TfidfVectorizer(ngram_range=(1,2))),
('nb', MultinomialNB())
])
predicted = nb_pipeline.fit(train_X, train_Y).predict(test_X)
• Validation of results
scores = cross_validation.cross_val_score(
nb_pipeline, train_X + test_X, train_Y + test_Y, cv=10, scoring=‘accuracy’
)
accuracy, std_deviation = scores.mean(), scores.std() * 2
precision = average_precision_score(test_Y, predicted)
recall = recall_score(test_Y, predicted, labels=[False, True])
f1 = f1_score(test_Y, predicted, labels=[False, True])](https://image.slidesharecdn.com/finalcustlingprofiling-160226163538/85/Customer-Linguistic-Profiling-11-320.jpg)
![Pipeline: Source Code Example
pipeline = sklearn.pipeline.Pipeline([
('features', sklearn.pipeline.FeatureUnion(
transformer_list=[
(‘status_string', sklearn.pipeline.Pipeline([ # tfidf on status
('tf_idf_vect', sklearn.feature_extraction.text.TfidfVectorizer()),
])),
('derived_numeric', sklearn.pipeline.Pipeline([ # aggregator creates derived values
(‘derived_cols', Aggregator([LexicalDiversity(), NumberOfFunctionalWords()])),
('scaler', sklearn.preprocessing.MinMaxScaler()),
])),
],
)),
(‘classifier_naive_bayes', sklearn.naive_bayes.MultinomialNB())
])](https://image.slidesharecdn.com/finalcustlingprofiling-160226163538/85/Customer-Linguistic-Profiling-12-320.jpg)
![Parameter fine-tuning
• Most transformers and classifier accept different parameters
• Parameters can heavily influence the result
grid_params = {
'features__status_string__tf_idf_vect__ngram_range': ((1, 1), (1, 2), (2,3))}
}
grid_search = GridSearchCV(pipeline, param_grid=grid_params, cv=2, n_jobs=-1, verbose=0)
y_pred_trait = grid_search.fit(train_X, train_Y).predict(x_test)
# print best parameters
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(grid_parameter.keys()):
print("t%s: %r" % (param_name, best_parameters[param_name]))](https://image.slidesharecdn.com/finalcustlingprofiling-160226163538/85/Customer-Linguistic-Profiling-13-320.jpg)








![Pf cs102 programming-10 [structs]](https://cdn.slidesharecdn.com/ss_thumbnails/pfcs102programming-10structs-170208153327-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)
