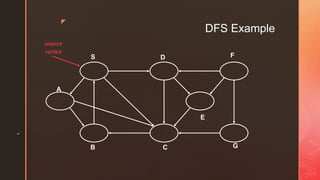
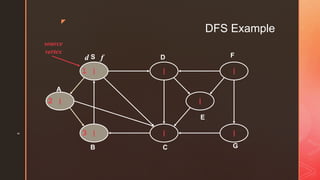
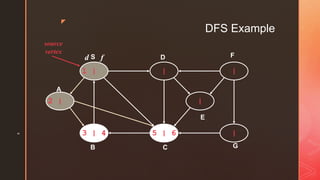
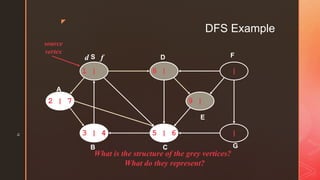
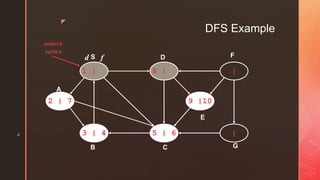
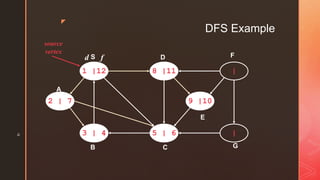
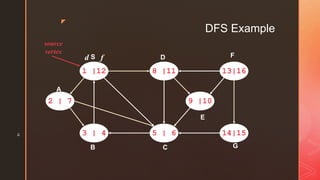
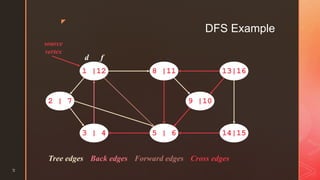
The document discusses depth-first search (DFS) algorithms. It provides pseudocode for performing DFS on a graph and walks through an example of running DFS on a sample graph. It explains that DFS classifies edges in the original graph as tree edges, back edges, forward edges, or cross edges based on how vertices are encountered during the algorithm's execution.

![z
2
Depth-First Search: The Code
Data: color[V], time, prev[V],d[V],
f[V]
DFS(G) // where prog starts
{
for each vertex u V
{
color[u] = WHITE;
prev[u]=NIL;
f[u]=inf; d[u]=inf;
}
time = 0;
for each vertex u V
if (color[u] == WHITE)
DFS_Visit(u);
}
DFS_Visit(u)
{
color[u] = GREY;
time = time+1;
d[u] = time;
for each v Adj[u]
{
if(color[v] == WHITE){
prev[v]=u;
DFS_Visit(v);}
}
color[u] = BLACK;
time = time+1;
f[u] = time;
}
Initialize](https://image.slidesharecdn.com/newmicrosoftpowerpointpresentation-170825075510/85/DFS-algorithm-2-320.jpg)
























![Depth first search [dfs]](https://cdn.slidesharecdn.com/ss_thumbnails/depthfirstsearchdfs-190926145304-thumbnail.jpg?width=640&height=640&fit=bounds)