Downloaded 168 times











![// get the list of tax/fees for this trade val forTrade: Trade => Option [ List [ TaxFeeId ]] = {trade => // .. implementation } // all tax/fees for a specific trade val taxFeeCalculate: Trade => List [ TaxFeeId ] => List [( TaxFeeId , BigDecimal )] = {t => tids => //.. implementation } val enrichTradeWith: Trade => List [( TaxFeeId , BigDecimal )] => BigDecimal = {trade => taxes => //.. implementation }](https://image.slidesharecdn.com/dependencyinjection-110503100116-phpapp02/75/Dependency-Injection-in-Scala-Beyond-the-Cake-Pattern-14-2048.jpg)
![val enrich = for { // get the tax/fee ids for a trade taxFeeIds <- forTrade // calculate tax fee values taxFeeValues <- taxFeeCalculate // enrich trade with net amount netAmount <- enrichTradeWith } yield ((taxFeeIds map taxFeeValues) map netAmount) (TradeModel.Trade) => Option[BigDecimal] :type enrich](https://image.slidesharecdn.com/dependencyinjection-110503100116-phpapp02/75/Dependency-Injection-in-Scala-Beyond-the-Cake-Pattern-15-2048.jpg)






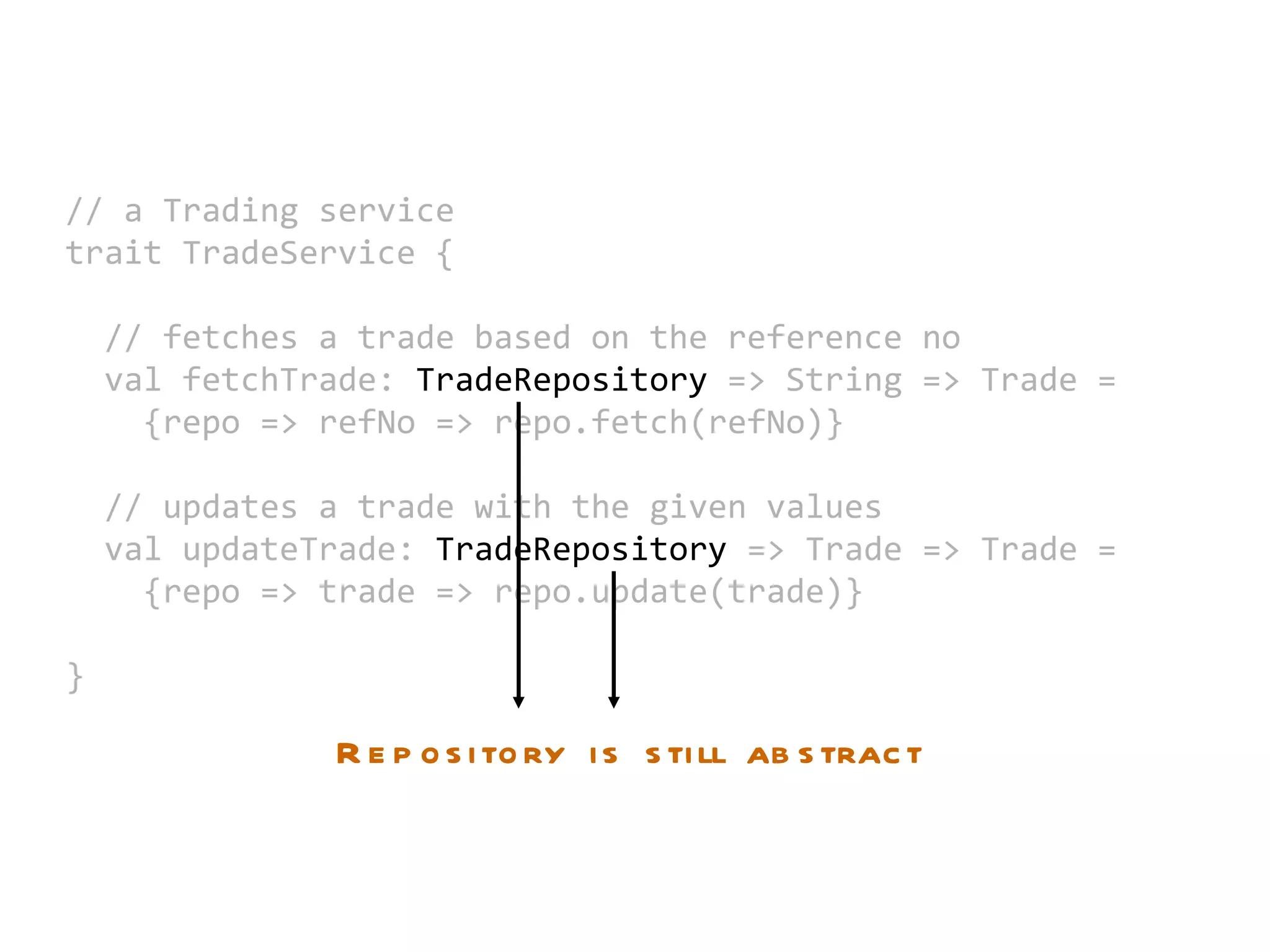
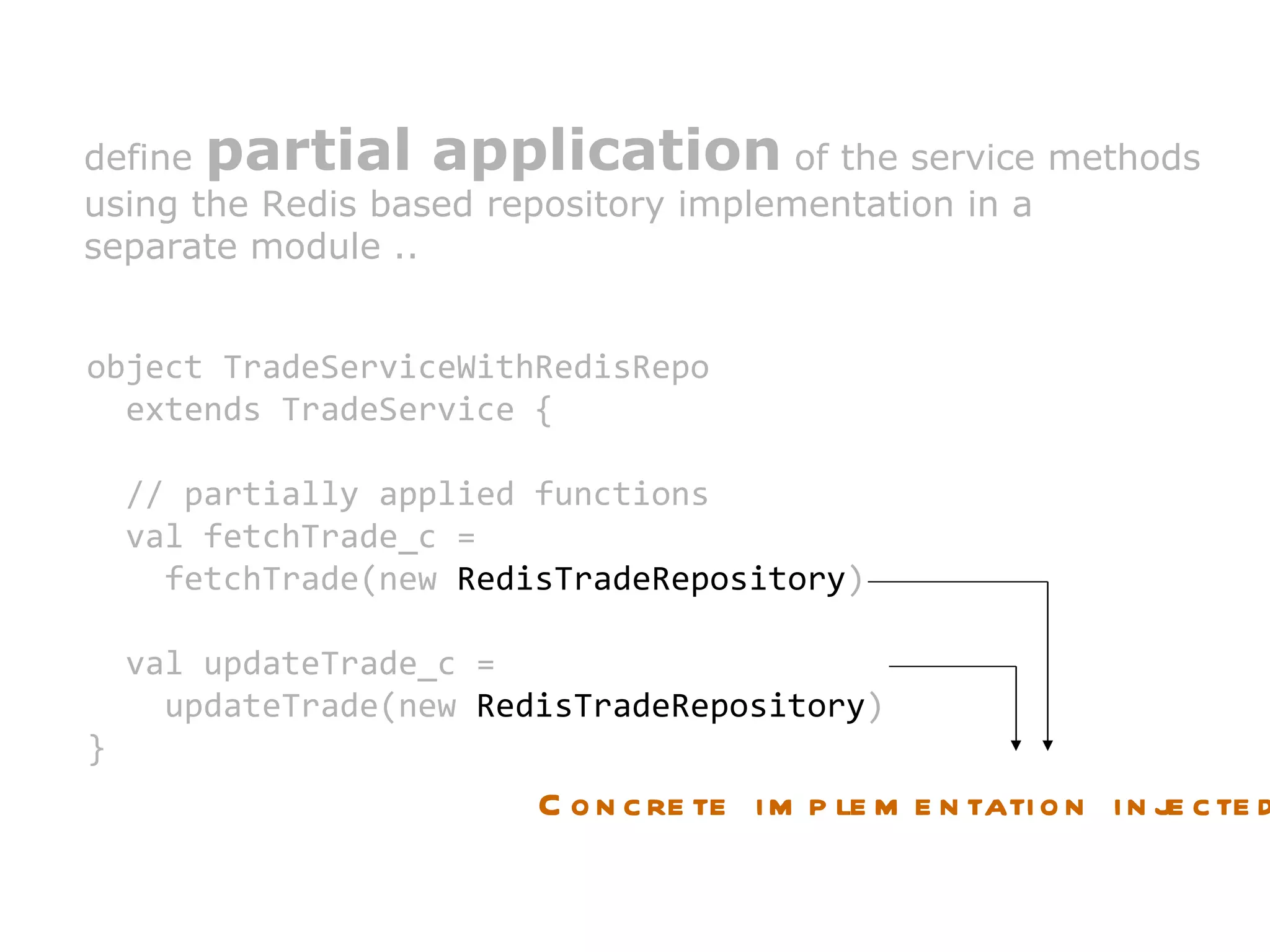
The document discusses dependency injection and different approaches to implement it in Scala code. It presents a trade service that depends on a trade repository interface. It shows how to inject a Redis implementation of the repository by partially applying the service functions. It also discusses using the Reader monad to delay injection of dependencies like the trade object. Finally, it proposes a typeclass based approach to dependency injection.


































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







