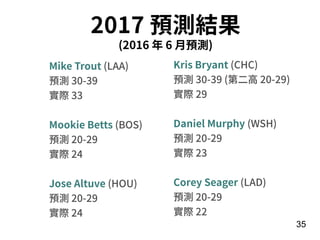
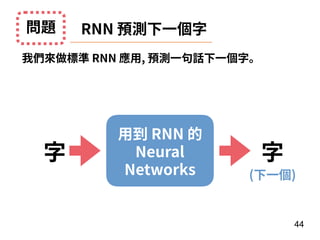
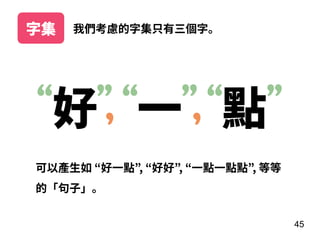
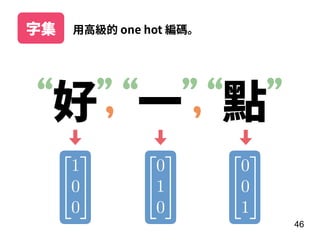
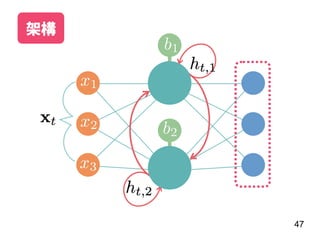
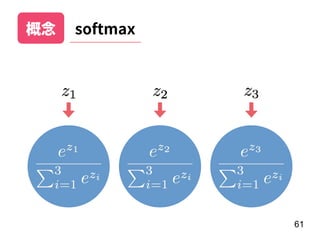
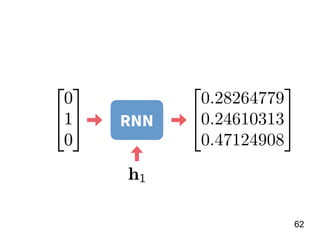
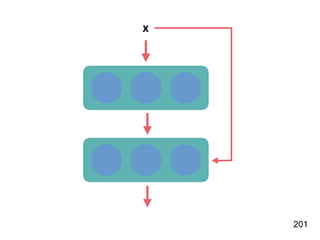
此文档介绍了神经网络的基本概念,重点在于递归神经网络(RNN)及其变体如 LSTM 和 GRU 的结构和应用。文中探讨了模型的训练过程、调参技巧,以及实际案例,如情感分析和 MLB 球员全垒打数预测。最后,提供了利用 Keras 框架实施 RNN 的具体步骤和示例。



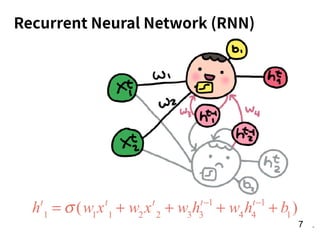







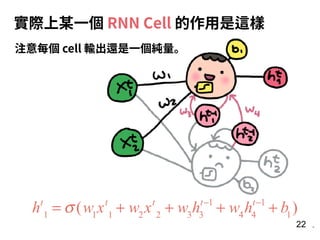






![31
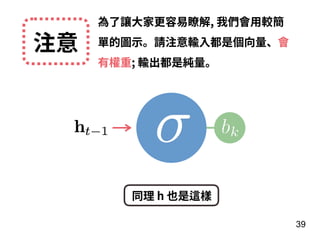
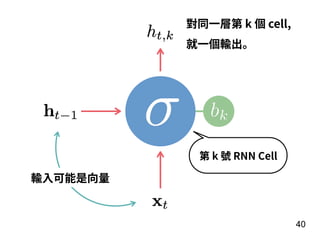
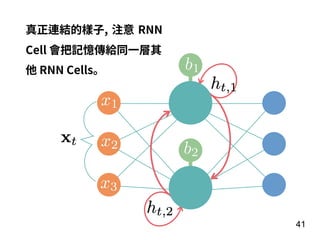
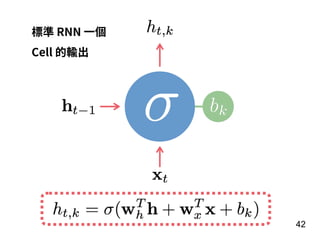
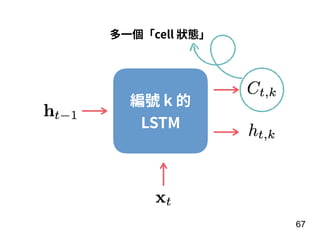
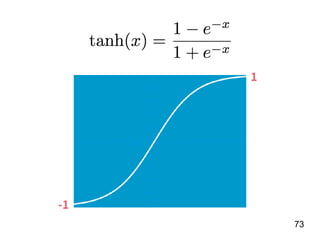
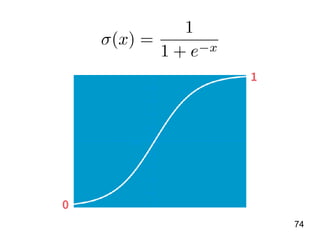
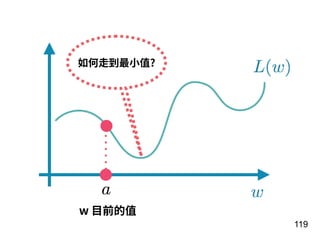
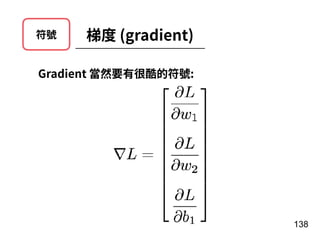
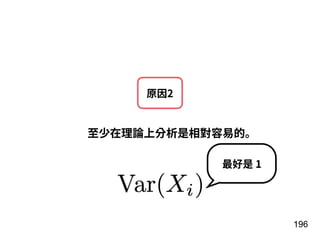
第 t-1 年
[Age, G, PA, AB, R, H, 2B, 3B, HR,
RBI, SB, BB, SO, OPS+, TB]
15 個 features
第 t 年
全壘打數
f](https://image.slidesharecdn.com/2018rnn-180304041325/85/Recurrent-Neural-Network-31-320.jpg)


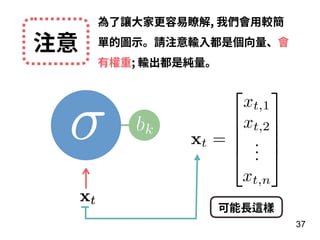
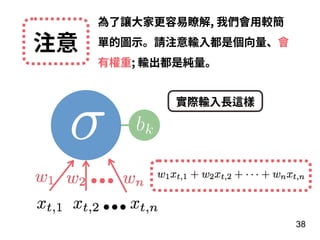

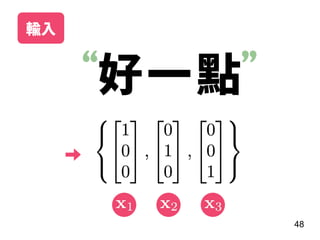
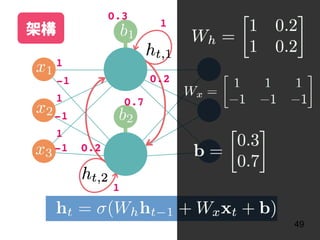
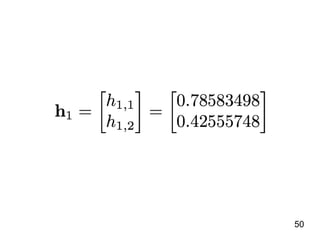
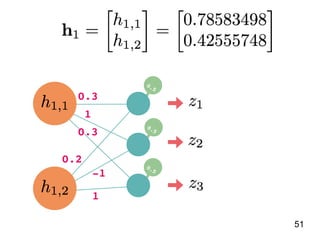

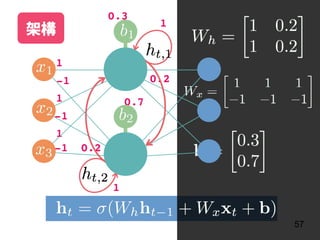
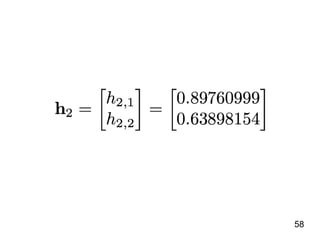
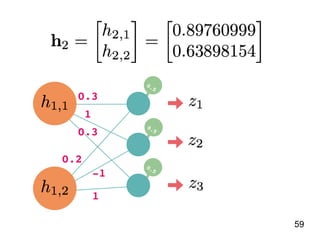
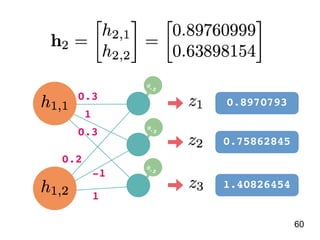




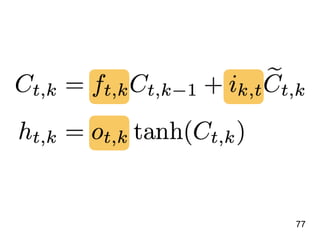








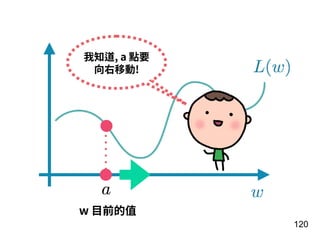
![說明 資料內容
我們來看⼀筆輸⼊資料⻑像:
[1, 1230, 3765, 566, 97,
189, 102, 86, ...]
92
每個數字代表⼀個字, 這就是⼀則評論。](https://image.slidesharecdn.com/2018rnn-180304041325/85/Recurrent-Neural-Network-92-320.jpg)
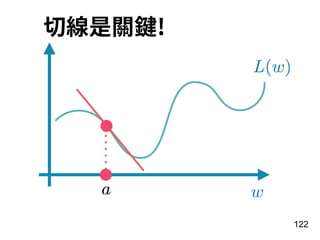
![注意 資料⻑度
每⼀則評論⻑度顯然是不⼀樣的!
for i in range(10):
print(len(x_train[i]), end=', ')
93
輸出: 218, 189, 141, 550, 147, 43, 123, 562, 233,
130](https://image.slidesharecdn.com/2018rnn-180304041325/85/Recurrent-Neural-Network-93-320.jpg)











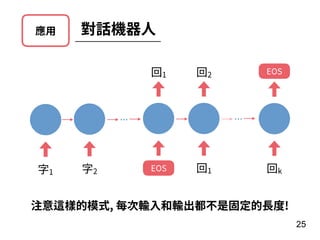
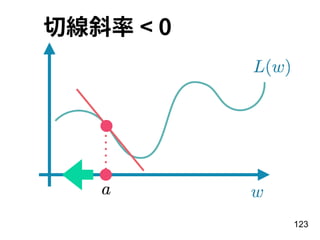
![重點 組裝
106
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])](https://image.slidesharecdn.com/2018rnn-180304041325/85/Recurrent-Neural-Network-106-320.jpg)






![重點 訓練成績
113
print('測試資料的 loss:', score[0])
print('測試資料正確率:', score[1])](https://image.slidesharecdn.com/2018rnn-180304041325/85/Recurrent-Neural-Network-113-320.jpg)







































































![[系列活動] 手把手打開Python資料分析大門](https://cdn.slidesharecdn.com/ss_thumbnails/python-171213042421-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[students AI workshop] Pytorch](https://cdn.slidesharecdn.com/ss_thumbnails/pytorch1-170911183243-thumbnail.jpg?width=640&height=640&fit=bounds)














![[數學、邏輯與人生] 05 數,三聲數](https://cdn.slidesharecdn.com/ss_thumbnails/05-161102062443-thumbnail.jpg?width=640&height=640&fit=bounds)
![[數學軟體應用] 05 HTML+CSS](https://cdn.slidesharecdn.com/ss_thumbnails/05htmlcss-161024122309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[數學、邏輯與人生] 03 集合和數學歸納法](https://cdn.slidesharecdn.com/ss_thumbnails/03-161019135315-thumbnail.jpg?width=640&height=640&fit=bounds)
![[數學、邏輯與人生] 01 基本邏輯和真值表](https://cdn.slidesharecdn.com/ss_thumbnails/01-161005134119-thumbnail.jpg?width=640&height=640&fit=bounds)




![[數學、邏輯與人生] 00 課程簡介](https://cdn.slidesharecdn.com/ss_thumbnails/00-160923023209-thumbnail.jpg?width=640&height=640&fit=bounds)


