Recommended
PPTX
PDF
PPTX
PDF
シリーズML-03 ランダムフォレストによる自動識別
PPTX
Interpreting Tree Ensembles with inTrees
PDF
PDF
ランダムフォレストとそのコンピュータビジョンへの応用
PDF
「樹木モデルとランダムフォレスト-機械学習による分類・予測-」-データマイニングセミナー
PDF
PDF
PPTX
Imputation of Missing Values using Random Forest
PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識 第3版
PDF
PDF
最近のRのランダムフォレストパッケージ -ranger/Rborist-
PDF
PPTX
PDF
PDF
PDF
PDF
Oracle Cloud Developers Meetup@東京
PDF
Randomforestで高次元の変数重要度を見る #japanr LT
PPTX
Feature Selection with R / in JP
PPTX
PDF
Lispmeetup #50 cl-random-forest: Common Lispによるランダムフォレストの実装
PDF
PPTX
Introduction of featuretweakR package
PDF
SQL Server 2016 R Services + Microsoft R Server 技術資料
PPTX
More Related Content
PPTX
PDF
PPTX
PDF
シリーズML-03 ランダムフォレストによる自動識別
PPTX
Interpreting Tree Ensembles with inTrees
PDF
PDF
ランダムフォレストとそのコンピュータビジョンへの応用
PDF
「樹木モデルとランダムフォレスト-機械学習による分類・予測-」-データマイニングセミナー
Similar to 32bit Windowsで頑張るRandom Forest
PDF
PDF
PPTX
Imputation of Missing Values using Random Forest
PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識 第3版
PDF
PDF
最近のRのランダムフォレストパッケージ -ranger/Rborist-
PDF
PPTX
PDF
PDF
PDF
PDF
Oracle Cloud Developers Meetup@東京
PDF
Randomforestで高次元の変数重要度を見る #japanr LT
PPTX
Feature Selection with R / in JP
PPTX
PDF
Lispmeetup #50 cl-random-forest: Common Lispによるランダムフォレストの実装
PDF
PPTX
Introduction of featuretweakR package
PDF
SQL Server 2016 R Services + Microsoft R Server 技術資料
PPTX
32bit Windowsで頑張るRandom Forest 1. 2. 自己紹介
twitter : fqz7c3
趣味:音楽、囲碁、映画、アニメ、フットサル
仕事: ビジネスとデータ分析の橋渡し
R :通算で2年ほど、前処理は基本Perlで。
機械学習:1年半ぐらい前に言葉を知りました
レベル:「ランダムフォレスト最強」な人
間違い等ございましたらご指摘ください
2 / 27
3. 「ランダムフォレスト最強」な人
データサイエンティストレベル表shakezoさんブログより
レベル2の人達は集計分析に加えて、最低限の機械学習や統計学の手法を
知っています。SVMやランダムフォレストなどのメジャーな手法を覚え、
データ分析が面白くなってくる頃です。しかしながらRやSPSSなどの専用ソ
フトを常にデフォルト設定のパラメータで分析していたり、特徴量選択や前
処理の重要性を甘く見る傾向があります。
近いうちに現実のデータはirisのように
甘くないことを知ることになるでしょう。
ありがちな発言
「ランダムフォレスト最強」
http://d.hatena.ne.jp/shakezo/20130715/1373874047
3 / 27
4. Random Forest
一つのデータセットから微妙に違う決定木を複数
作って、その多数決で答えを求めるアルゴリズム
データ
・
・
・
復元抽出&
決定木作成
判定
A
B
A
C
A
A
各判定の結果
多数決最終判定結果
4 / 27
5. 6. Rで使う
randomForestパッケージが有名
調整する
主なパラメータ
説明(デフォルト値)
ntree 生成する木の数(500)
mtry
各木で用いる変数の数
(分類: 全変数の1/3、回帰:全変数の二乗根)
nodesize
各ノードでの分岐の打ち切り数
(分類: 1、回帰: 5以下)
maxnodes 終端ノード数の上限値(NULL)
6 / 27
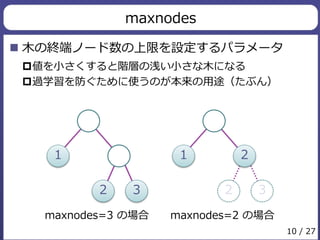
7. 8. 9. 10. 11. maxnodes
デフォルトがNULL
非常に複雑な大きな木ができる
大きな木ができても保持できる様に、大量のメモリを確保
しようとして失敗するっぽい(未確認)
maxnodesを適切に設定すれば
メモリ使用量を抑えられそう!
11 / 27
12. 13. 14. 15. 終端ノードを数える
森を見る
最も大きい木のノード数
ntreeで指定した木の本数
rfmodel$forest$nodestatus に
各木の全ノードについて、
それぞれ分岐であるか、終端ノードであるかの
情報が入っている
15 / 27
16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 参考資料
利用したデータ
UCI Machine Learning Repository のBank Marketing Data Set
http://archive.ics.uci.edu/ml/datasets/Bank+Marketing
下記論文からの引用
[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the
Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, June 2014
randomForestについて
マニュアル
http://cran.r-project.org/web/packages/randomForest/randomForest.pdf
forestの中身の見方
https://stat.ethz.ch/pipermail/r-help/2003-April/032256.html
27 / 27
28.

























![参考資料
利用したデータ
UCI Machine Learning Repository のBank Marketing Data Set
http://archive.ics.uci.edu/ml/datasets/Bank+Marketing
下記論文からの引用
[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the
Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, June 2014
randomForestについて
マニュアル
http://cran.r-project.org/web/packages/randomForest/randomForest.pdf
forestの中身の見方
https://stat.ethz.ch/pipermail/r-help/2003-April/032256.html
27 / 27](https://image.slidesharecdn.com/32bitwindowsrandomforest-140921005530-phpapp01/85/32bit-Windows-Random-Forest-27-320.jpg)




























