Download as PDF, PPTX

![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Motivation
Why?
1 An ontology is a formal, explicit specification of a shared
conceptualisation [TRG93, RS98]
2 Knowledge-bases are represented by ontologies [UMLS09]
3 Formalizing an ontology for a domain is a tedious and cumbersome
process (Knowledge acquisition bottleneck (KAB))
4 Substantially large text corpora available to be classified into an
ontology [BAO09]
5 Text corpora of the domain of discourse contains
Redundancy
Structured and unstructured text
Noisy data (Uncertainty via Degree of belief)
Lexical disambiguities
Semantic heterogeneity problems
6 Research on KAB is highly investigated by the Semantic (Web)
Community](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-3-2048.jpg)
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
General idea
General idea
1 Reverse engineering an ontology (bottom-up) (Lexicon ⇒ An
ontology)
2 Bayesian reasoning to deal with degree of belief
3 Conceptualization is learned through probabilistic reasoning
4 Lexicon-semantic structues extracted from Wordnet 3.0 [WN3009]
5 Use top-down approach to check the consistency of the generated
ontology
6 Constrained by conditions and hypotheses
7 Serialize the learned ontology into OWL DL and query using
SPARQL
“A little semantics goes a long way” - Hendler hypothesis [JH03]](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-4-2048.jpg)
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Probabilistic reasoning & Heterogeneity
Probabilistic reasoning
P-CLASSIC [DK97]
P-OWL extension [ZD04]
P-SHIF(D), P-SHOIN(D) & P-Pellet [TL07, PP08]
Heterogeneity
Read the web project [TM09, TM10]
SEAL, iSEAL & ASIA [RW07, RW08, RW09]
Taxonomy induction [RS06]
LOD [JB09, LD06]](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-5-2048.jpg)
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Knowledge acquisition & ontology learning
Knowledge acquisition
Approaches [PC09, DSK09, LS09, HC09, JB05]
Large scale knowledge extraction
Knowledge integration
Extracting commonsensical knowledge
Textual entailment with first-order-logic
Tools [TTO00, SS09, OLSW02, TTO01, HT09]
Text-To-Onto, Text2Onto, OntoWare.org LExO & HermiT
Ontology learning
Learning [PC09, PH05, CC08, JL09, LBM08]
Dealing with uncertainty and inconsistency
Semantic concepts with unsupervised statistical learning
Semantic Web Services & floksonomy
Formal concept analysis [PC05]](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-6-2048.jpg)

![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Goals
Goals
1 To generate consistent lexico-semantic ontology O with a T − Box
and a A − Box that can be serialized into OWL DL
2 Querying via SPARQL [SPARQL08] [JENA09]
How do we start ?
1 Corpus C contains a lot of documents di (di ∈ C ) for i = 1, 2, 3, . . .
2 Learned lexicon set L contains a finite list of words wj
(L = w1 , w2 , . . . , wn ) and group set G contains a finite set of groups
gk (G = g1 , g2 , . . . , gm )](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-8-2048.jpg)
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Definition
The lexicon L is the set that contains words belonging to the universe of
English vocabulary, which is part-of-speech type tagged with the Penn
Treebank English POS tag set [PT10] and the type of the word IS,
Term Description
NN Noun, singular or mass
NNP Proper Noun, singular
NNS Noun, plural
NNPS Proper Noun, plural
JJ Adjective
JJR Adjective, comparative
JJS Adjective, superlative
VB Verb, base form
VBD Verb, past tense
VBG Verb, gerund or present participle
VBN Verb, past participle
VBP Verb, non-3rd person singular present
VBZ Verb, 3rd person singular present](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-10-2048.jpg)

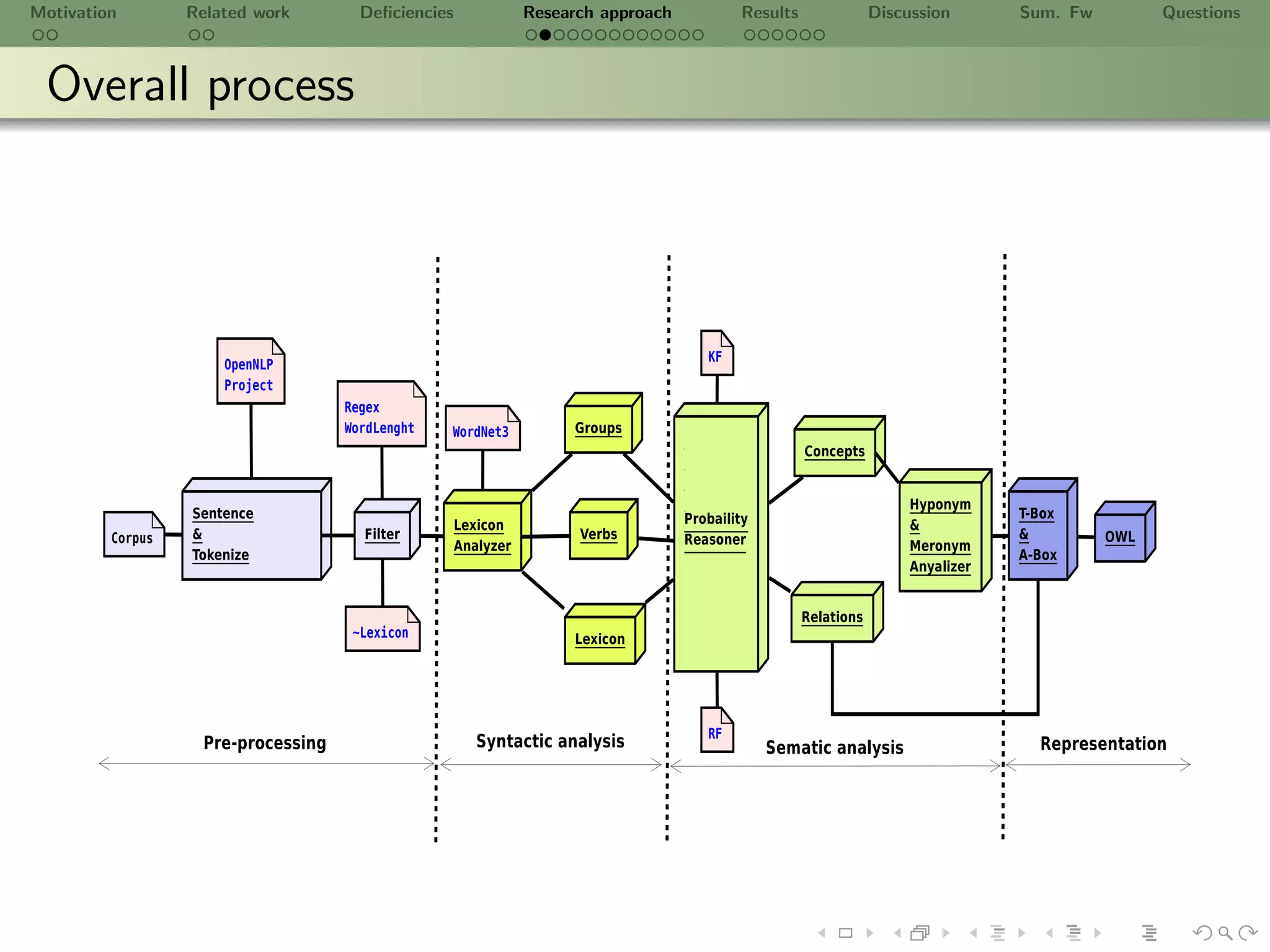
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Pre-processing
Filter
Regex ([a-zA-Z]+[- ]?w*) , Length of a word (2)
Example
1 The mevalonate pathway is comprised of three consecutive reactions
that are catalyzed by the enzymes mevalonate kinase (MK; E.C.
2.7.1.36), phosphomevalonate kinase (PMK; E.C. 2.7.4.2), and
diphosphomevalonate decarboxylase (PDM-DC; E.C. 4.1.1.33).
2 The DT mevalonate JJ pathway NN is VBZ comprised VBN of IN
three CD consecutive JJ reactions NNS that WDT are VBP
catalyzed VBN by IN the DT enzymes NNS mevalonate VBP
kinase NN -LRB- -LRB- MK NNP ; : E.C. NNP 2.7.1.36 CD
-RRB- -RRB- , , phosphomevalonate JJ kinase NN -LRB- -LRB-
PMK NNP ; : E.C. NNP 2.7.4.2 CD -RRB- -RRB- , , and CC
diphosphomevalonate JJ decarboxylase NN -LRB- -LRB-
PDM-DC NN ; : E.C. NNP 4.1.1.33 CD -RRB- -RRB- . .](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-12-2048.jpg)
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Pre-processing
Filter
Regex ([a-zA-Z]+[- ]?w*) , Length of a word (2)
Example
1 The mevalonate pathway is comprised of three consecutive reactions
that are catalyzed by the enzymes mevalonate kinase (MK; E.C.
2.7.1.36), phosphomevalonate kinase (PMK; E.C. 2.7.4.2), and
diphosphomevalonate decarboxylase (PDM-DC; E.C. 4.1.1.33).
2 The DT mevalonate JJ pathway NN is VBZ comprised VBN of IN
three CD consecutive JJ reactions NNS that WDT are VBP
catalyzed VBN by IN the DT enzymes NNS mevalonate VBP
kinase NN -LRB- -LRB- MK NNP ; : E.C. NNP 2.7.1.36 CD
-RRB- -RRB- , , phosphomevalonate JJ kinase NN -LRB- -LRB-
PMK NNP ; : E.C. NNP 2.7.4.2 CD -RRB- -RRB- , , and CC
diphosphomevalonate JJ decarboxylase NN -LRB- -LRB-
PDM-DC NN ; : E.C. NNP 4.1.1.33 CD -RRB- -RRB- . .](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-13-2048.jpg)
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Syntactic analysis
Bootstrap
1 di (di ∈ C ) for i = 1, 2, 3, . . .
2 From di read each sentence sj using OpenNLP
(sj ∈ di for j = 1, 2, 3, . . .)
3 Generate lexicon L according to the definition of lexicon
4 Each lexis wk ∈ L is normalized: find lemma or stemmed using
Wordnet 3.0
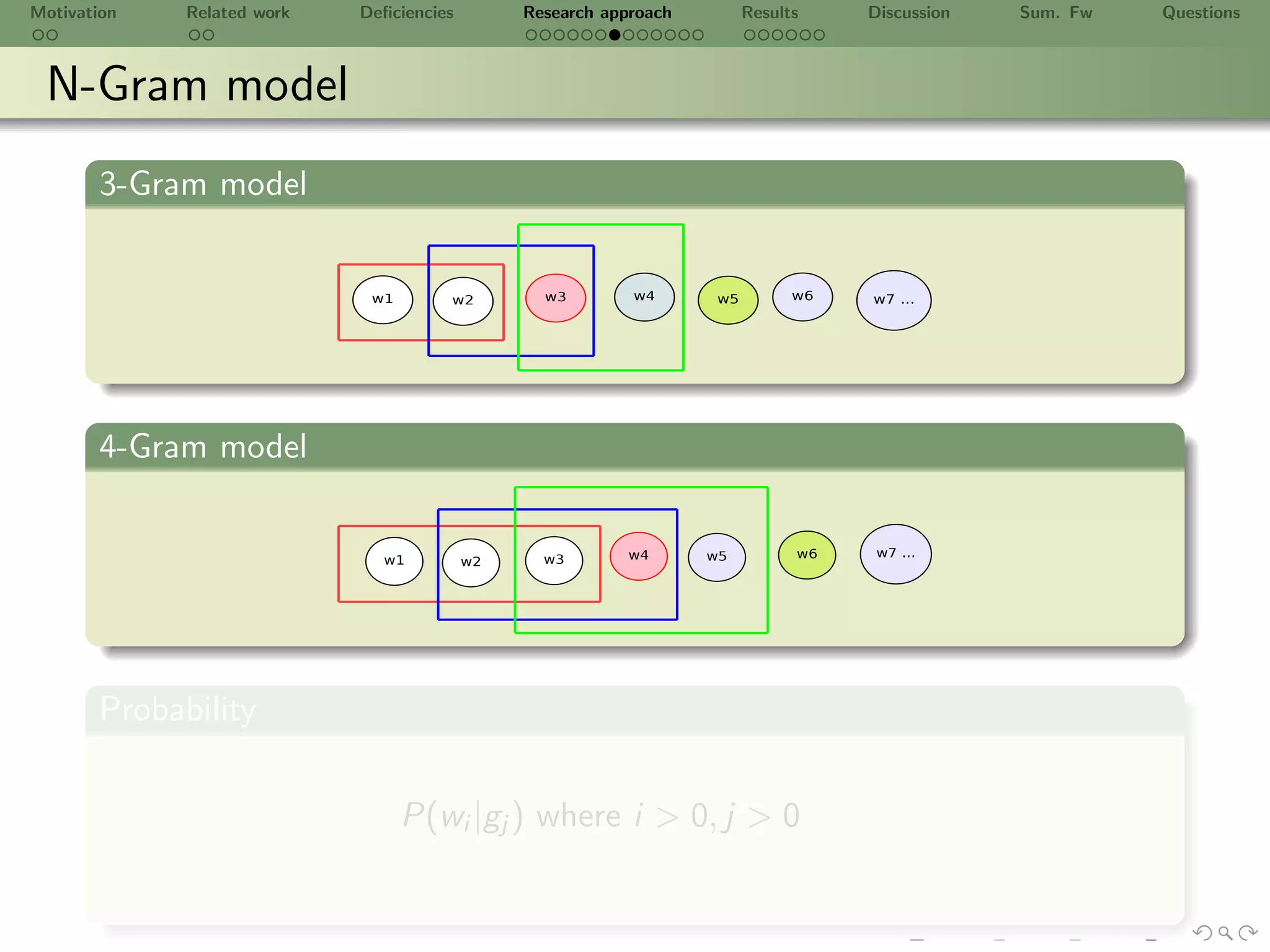
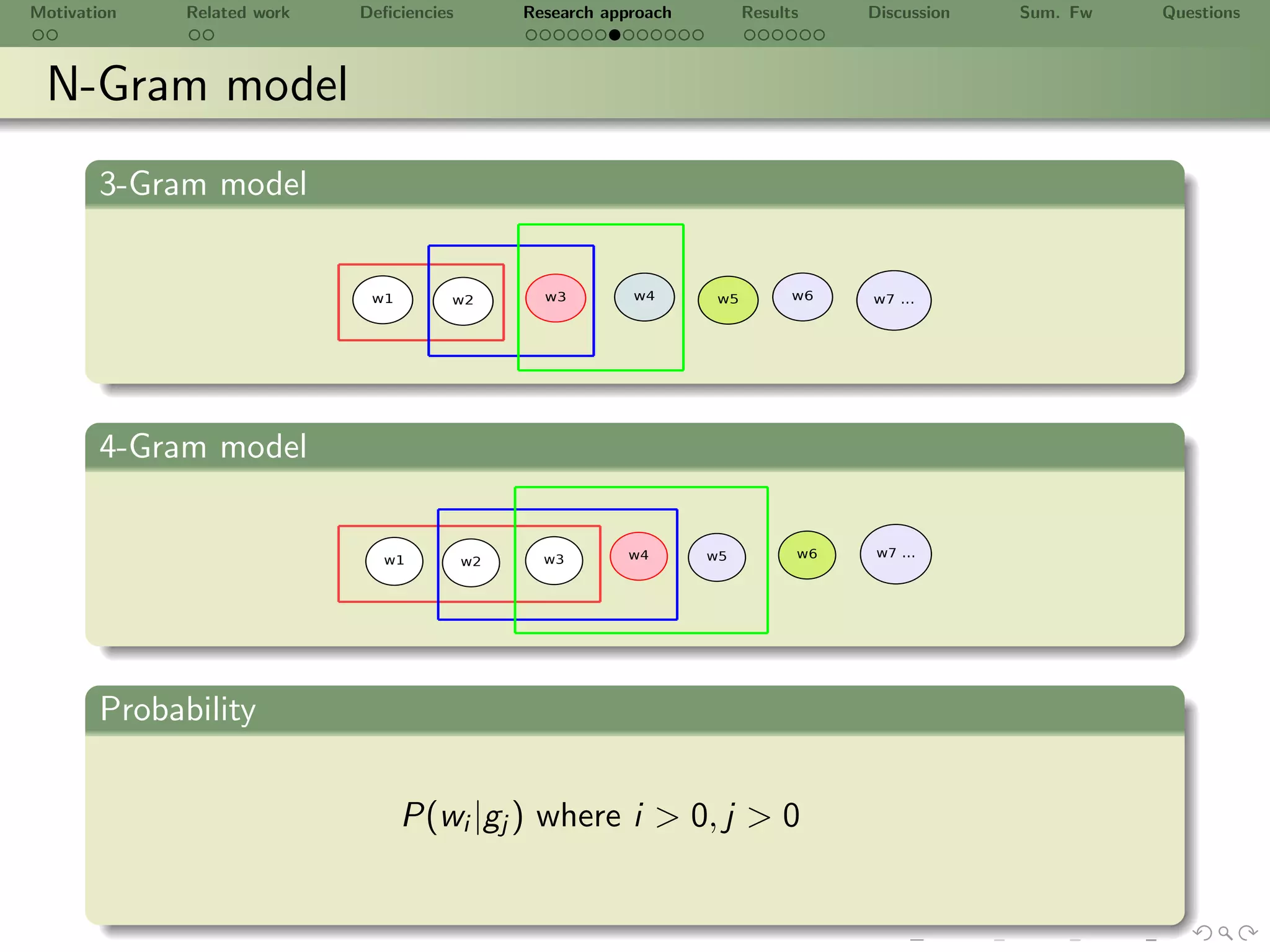
5 Candidate semantic groups gl using N − Gram model for lexis wk
[SJB09]
6 Candidate binary relationships vi (gj , gk ) vi , gk ∈ L using pattern
(NW OW VW NW OW )∗
∗ ∗ ∗ ∗](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-14-2048.jpg)
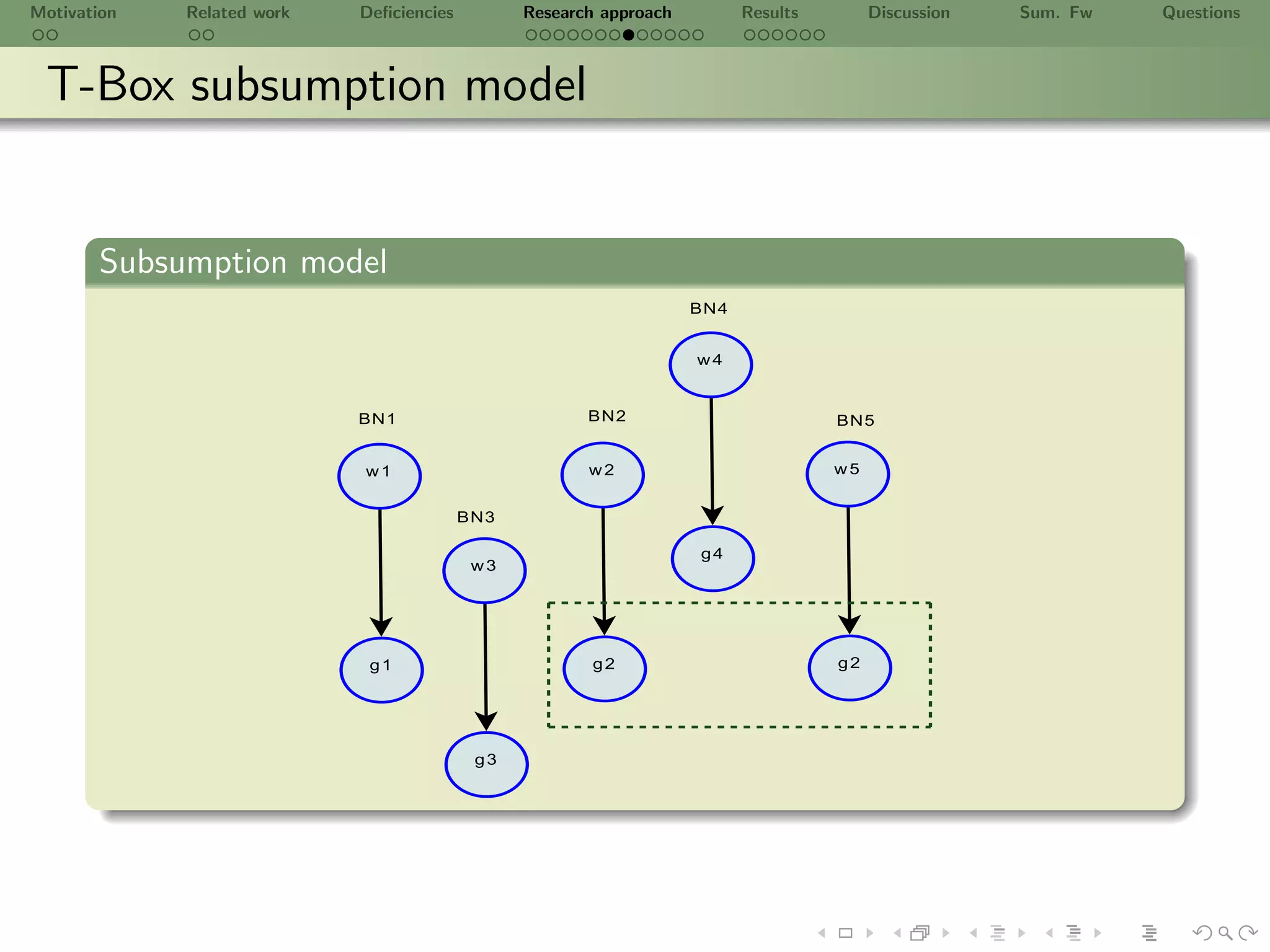
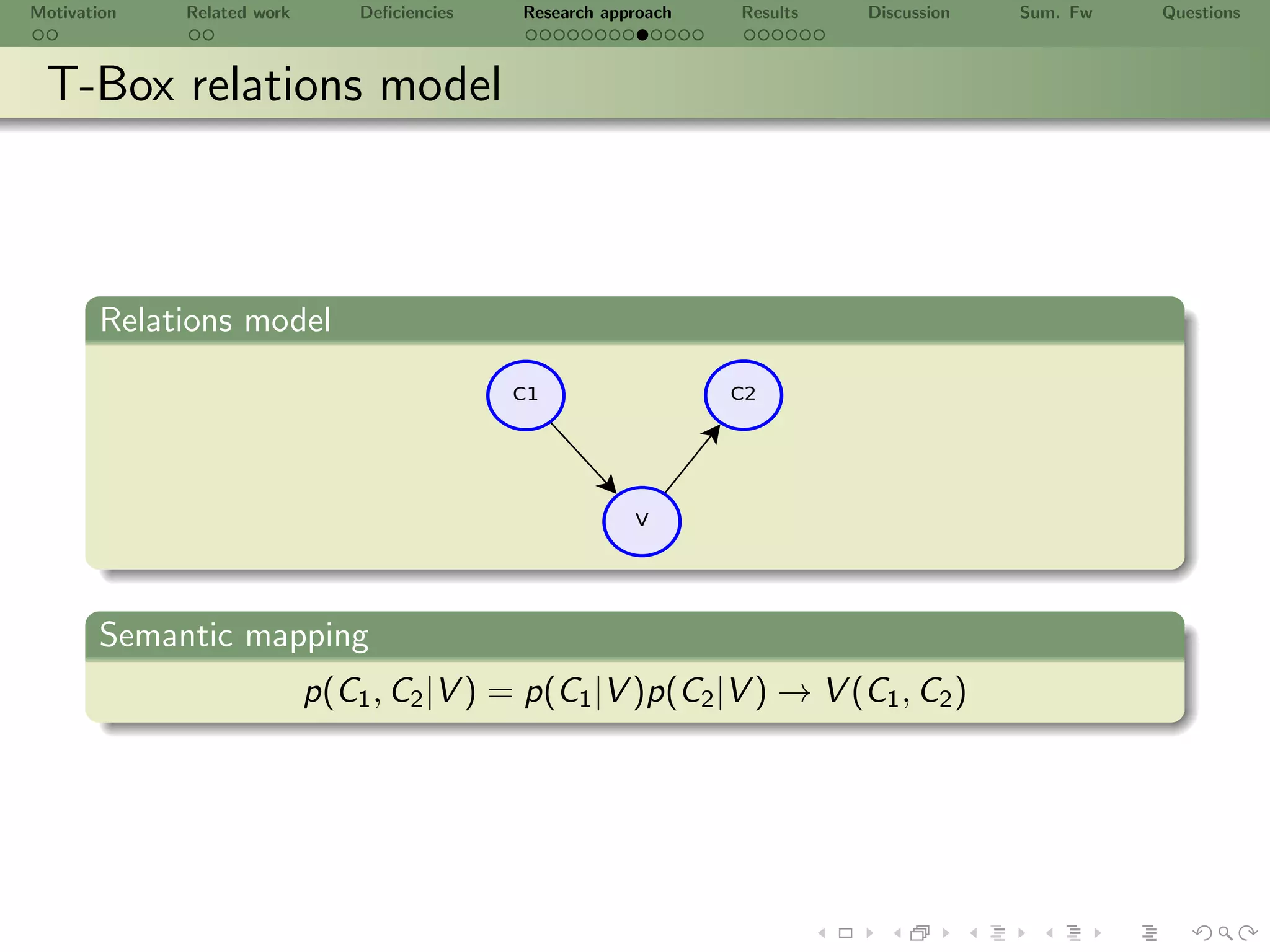

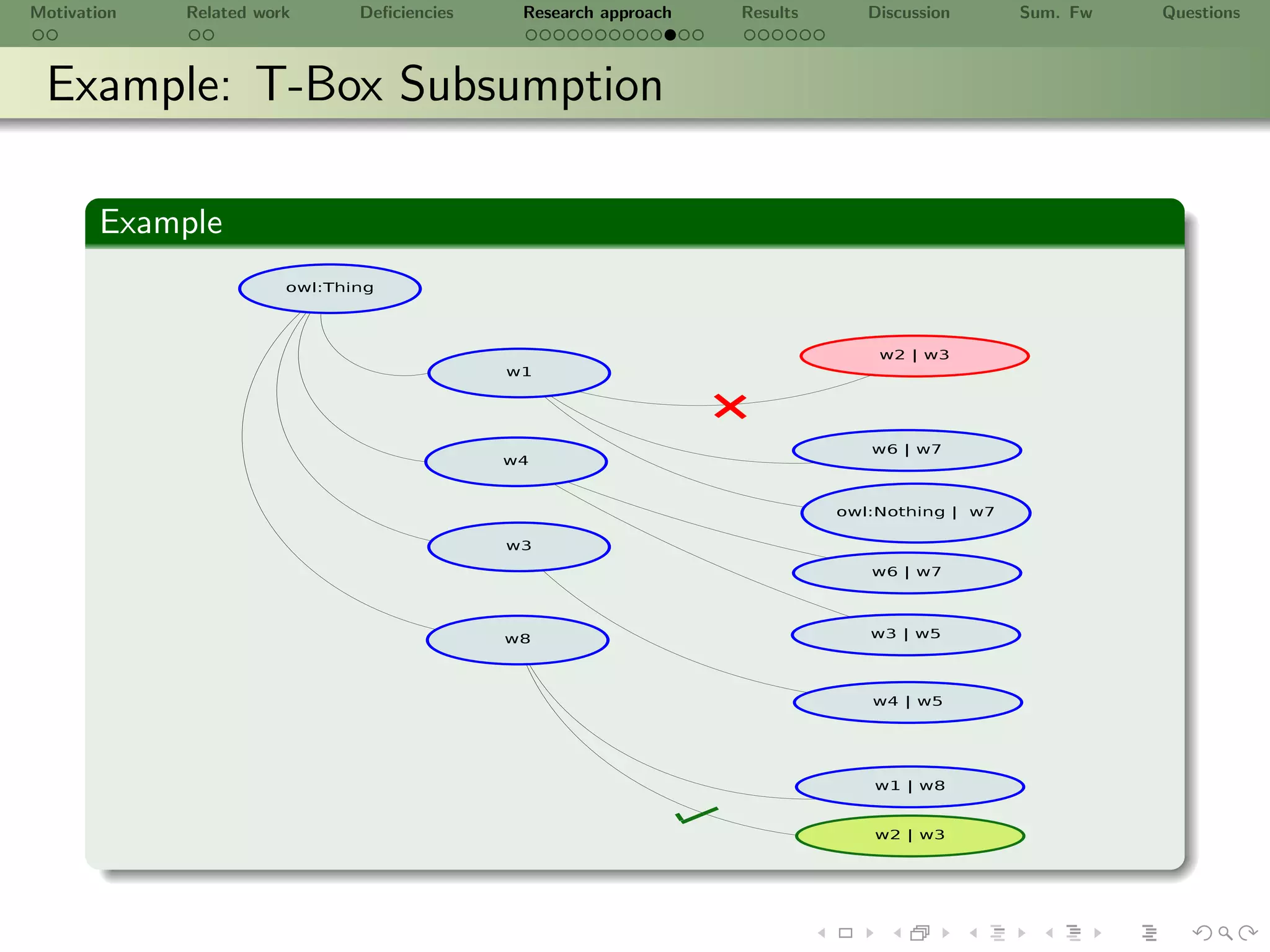
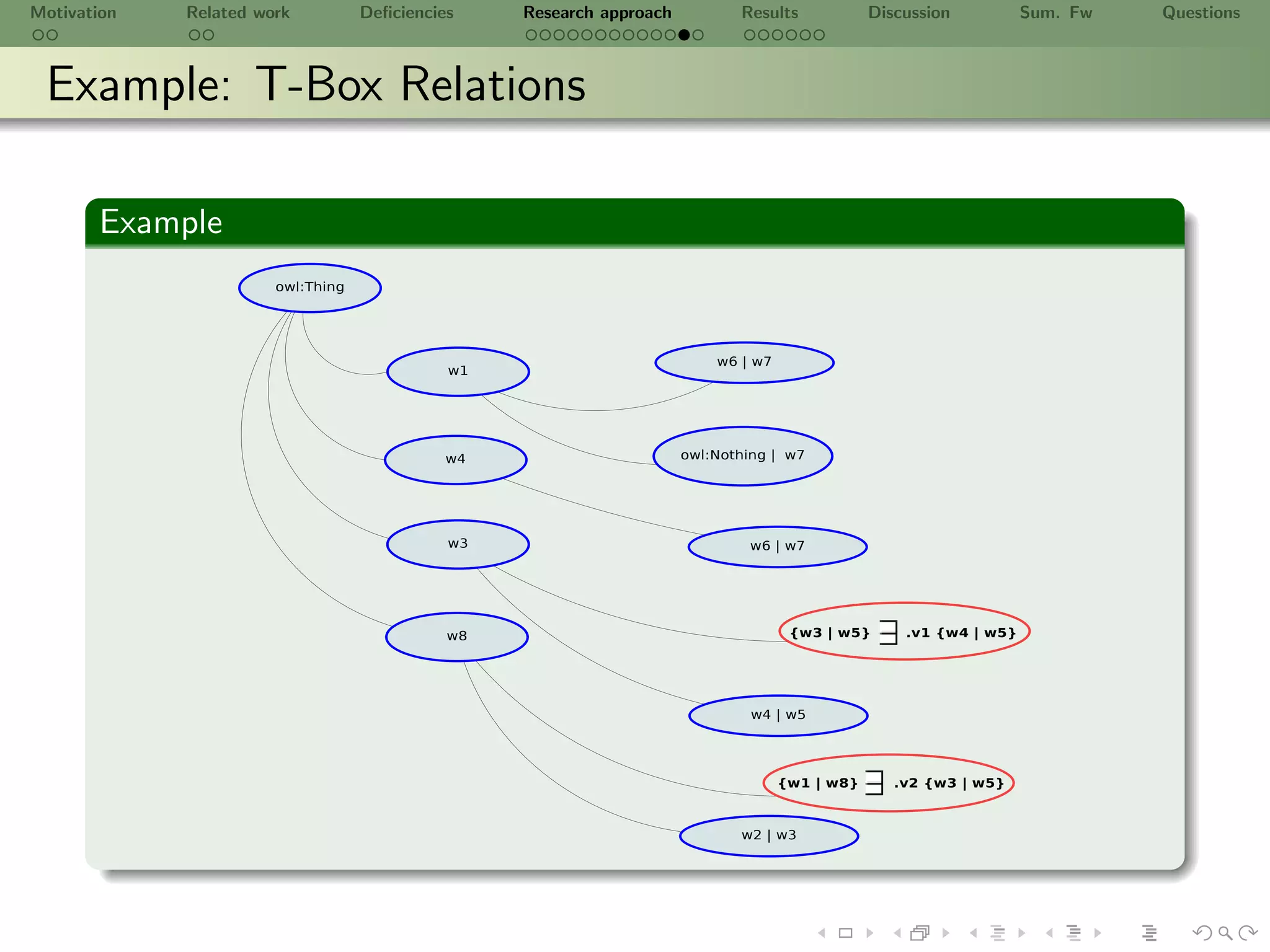
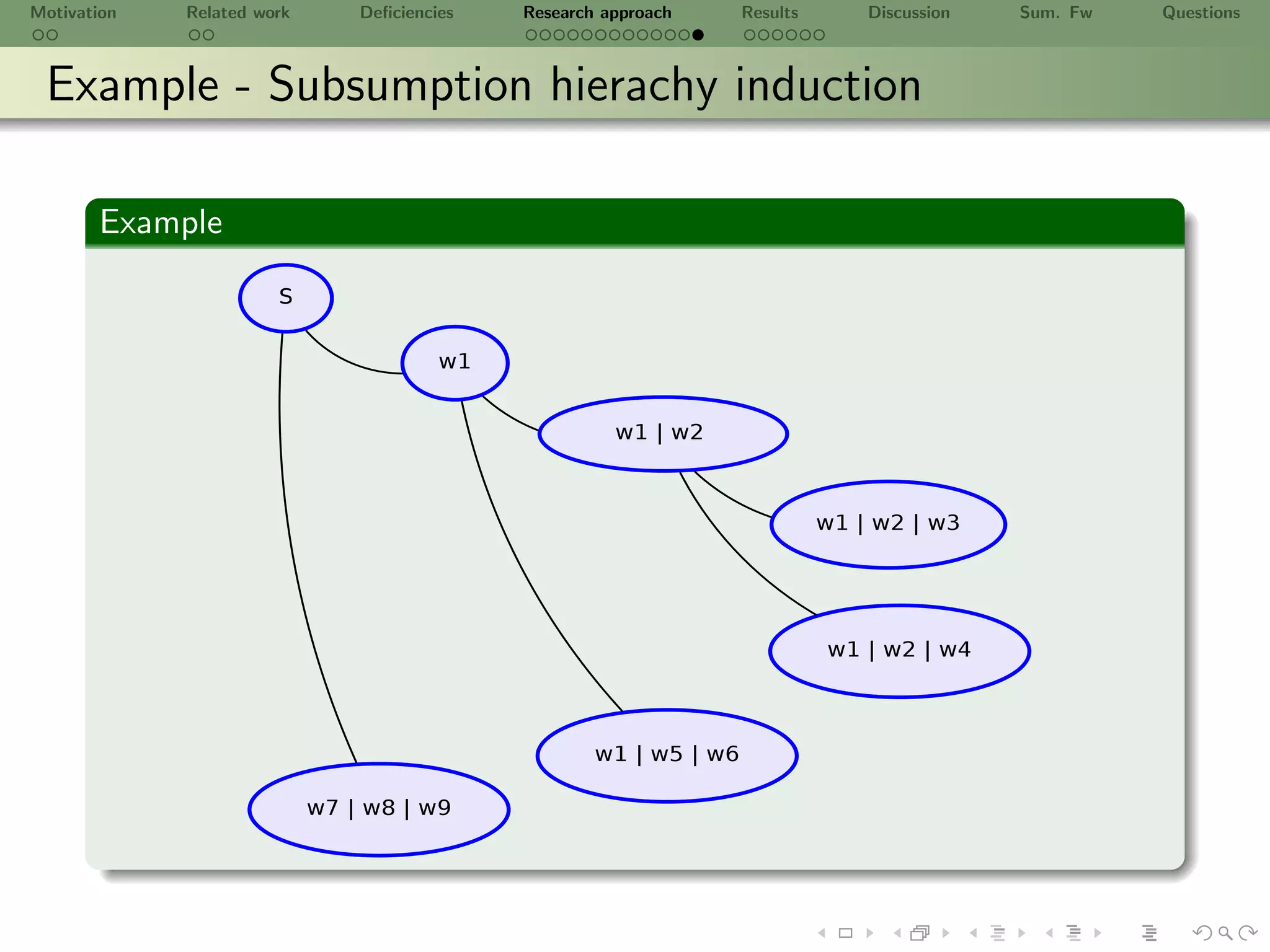
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Datasets
Datasets
1 PubChem assays, large public hight throughput screening dataset
[BAO09] (primary, qualitative evaluation). (Semantic Web Challenge
2010, http://bioassayontology.org )
2 Sample collection of 218 web pages extracted from the University of
Miami, Dept. of Computer Science (www .cs.miami.edu) domain
(quantitative evaluation)
3 Sample collection of 38 pdf files from ISWC 2009 proceedings
(secondary)](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-23-2048.jpg)
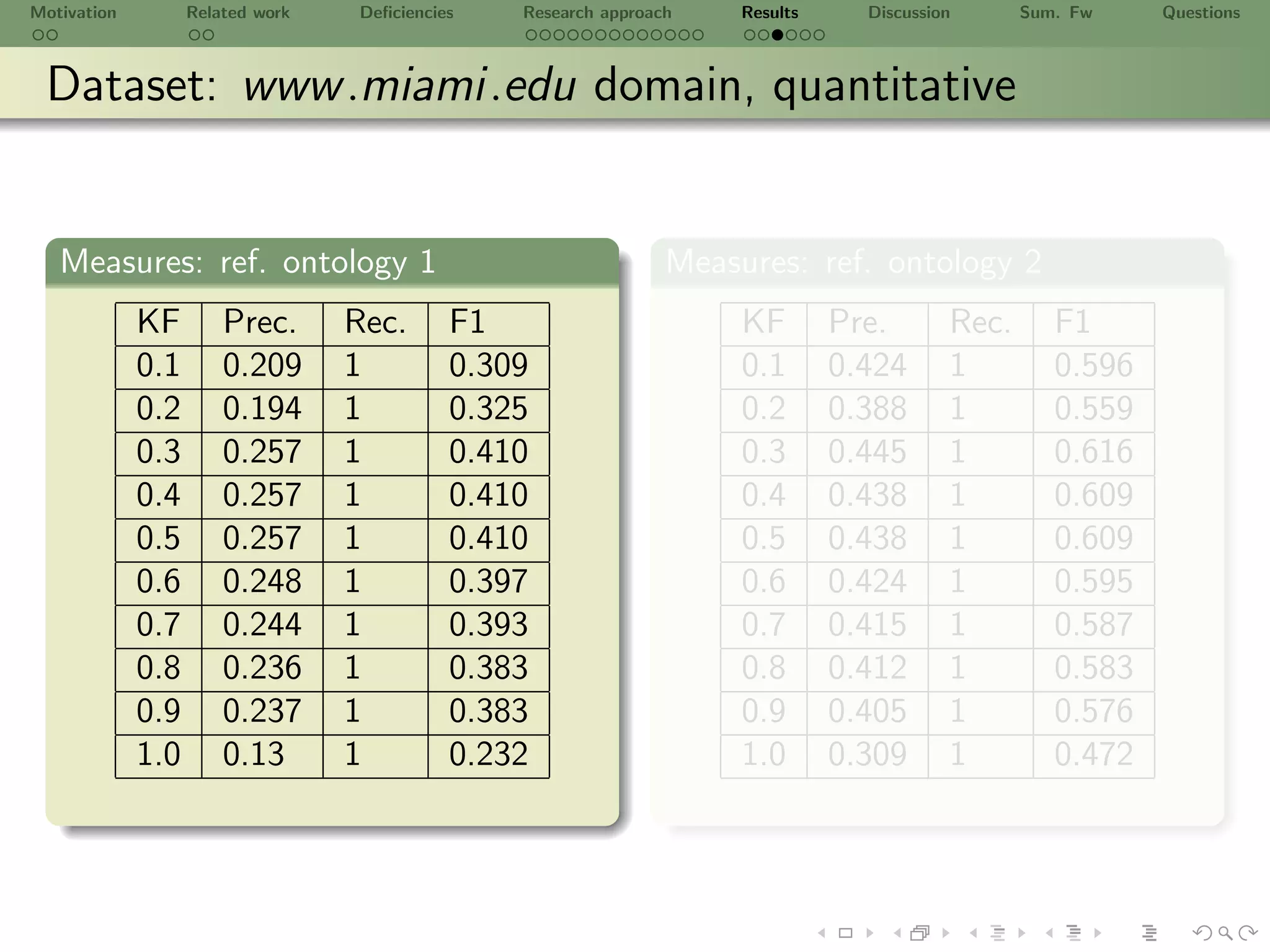
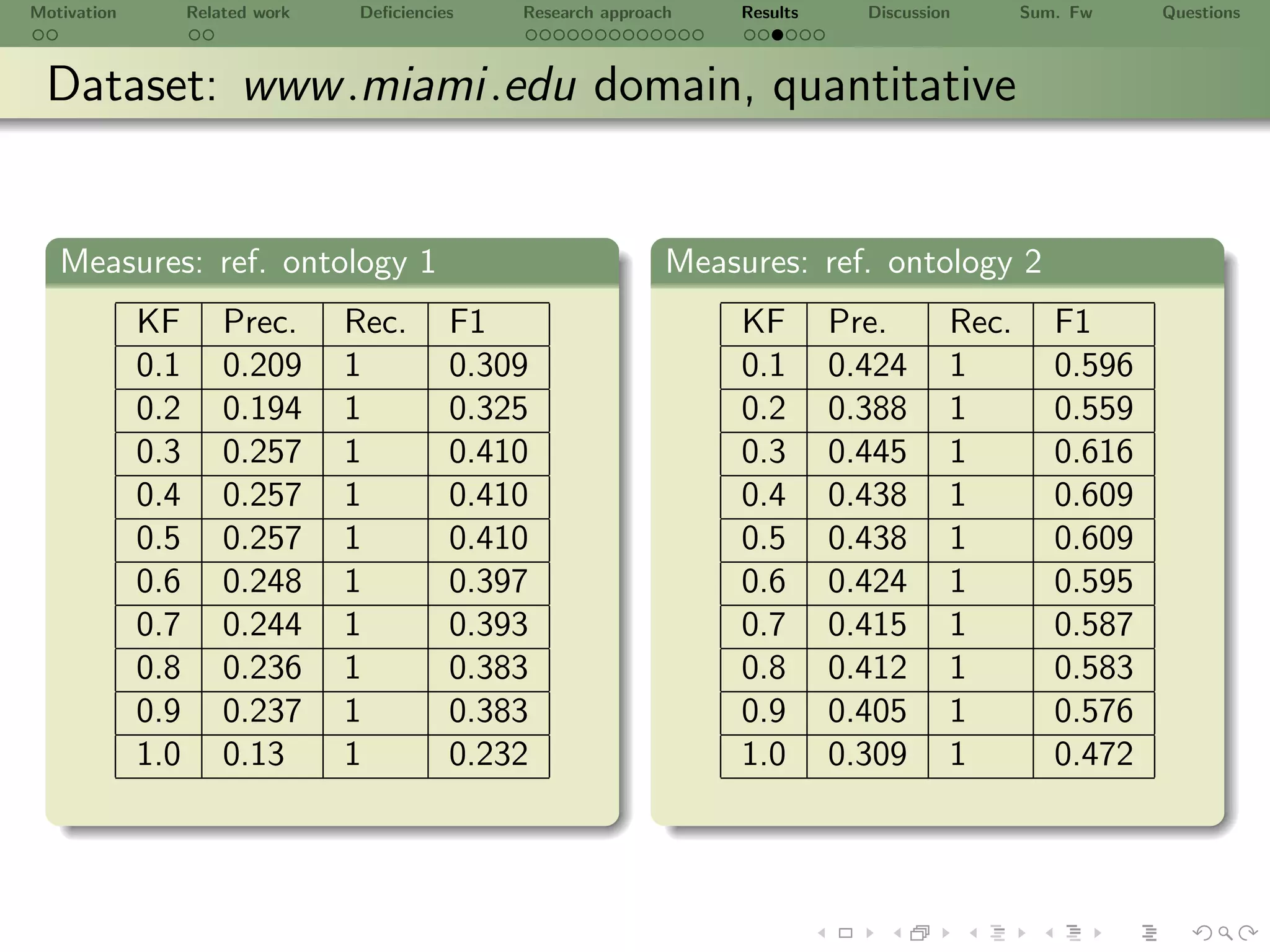
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
Dataset: www .cs.miami.edu domain
Detaset
Title Statistics Description
All documents are xhtml
Documents 218 formated with a give template
Norm. candidate concept words
Unique ConceptWords 5,384 from NN, NNP, NNS, JJ, JJR
& JJS using [a-zA-Z]+[- ]?w*
Norm. verbs from
Unique Verbs 835 VB, VBD, VBG, VBN, VBP
& VBZ using [a-zA-Z]+[- ]?w*
Total ConceptWords 39,455
Total Verbs 4,797
Total Lexicon 44,252 L = ConceptWords Verbs
Total Groups 39,455](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-24-2048.jpg)
![Motivation Related work Deficiencies Research approach Results Discussion Sum. Fw Questions
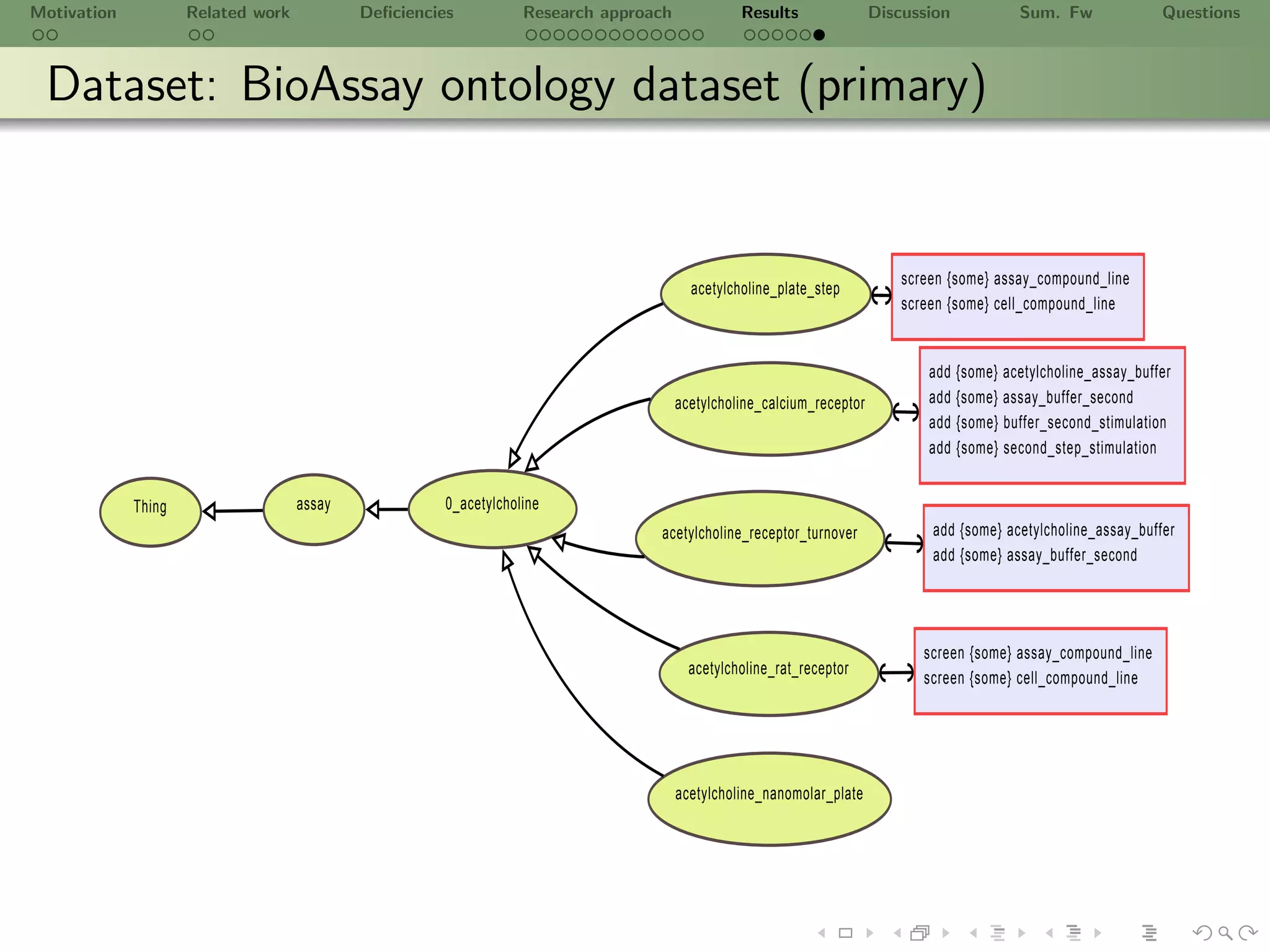
Dataset: PubChem dataset (primary)
Dataset
Title Statistics Description
All documents are xhtml
Documents 1,759 formated with a given template
Norm. candidate concept words
Unique ConceptWords 13,017 from NN, NNP, NNS, JJ, JJR
& JJS using [a-zA-Z]+[- ]?w*
Norm. verbs from
Unique Verbs 1,337 VB, VBD, VBG, VBN, VBP
& VBZ using [a-zA-Z]+[- ]?w*
Total ConceptWords 631,623
Total Verbs 109,421
Total Lexicon 741,044 L = ConceptWords Verbs
Total Groups 631,623](https://image.slidesharecdn.com/ursw2010-abeyruwanetal-101219162211-phpapp02/75/PrOntoLearn-Unsupervised-Lexico-Semantic-Ontology-Generation-using-Probabilistic-Methods-27-2048.jpg)








This document discusses the construction of a lexico-semantic ontology through a probabilistic approach that addresses the knowledge acquisition bottleneck in ontology generation. It outlines motivations, research approaches, and results, detailing phases like pre-processing, syntactic analysis, and semantic representation using various datasets. The study aims to create a consistent ontology that can be serialized into OWL DL and queried using SPARQL.

















































































